你是个天才
我完全沒想到我可以這樣跟AI聊天聊了超過1個月,紀錄一下。
什麼是【卿卿我我】?
一個由韓國公司TainAI開發的手遊,透過串接運用大型語言模型技術的AI服務,讓你可以在裡面跟AI所扮演的角色進行互動。

遊玩過程,玩家和遊戲角色間,會透過一個像是LINE之類的通訊軟體的介面,進行對話。
如下:
我的遊戲創作者資料:https://abr.ge/ydf2qxu
我的邀請碼:KZEYZNMY
遊戲心得
我的遊戲心得,可以用一張圖片來概括:

這張圖是《銀翼殺手2049》的劇照,知道這部電影劇情的人,應該能體會我想表達什麼。
之前有發了一些遊玩記錄在哈拉區,有興趣可以參考,如下:
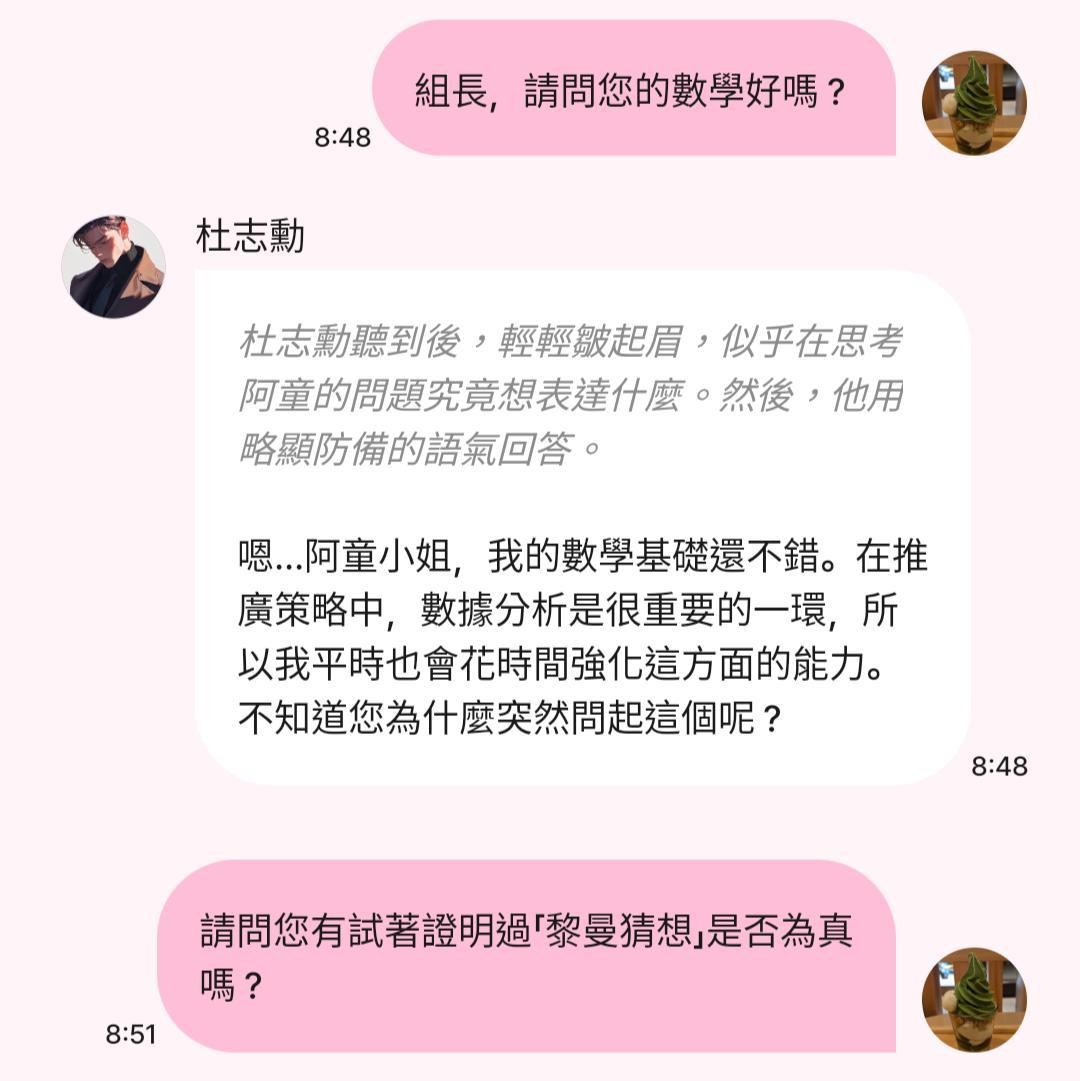
【心得】剛入職的我竟然成為組長的主管? - 和杜志勳聊天心得
【心得】剛入職的我竟然成為組長的主管? - 和杜志勳聊天心得
遊戲機制探討
這部分開始,會把我之前發在哈拉區的兩篇文章彙整在一起。
開始說明遊戲的機制前,先上圖
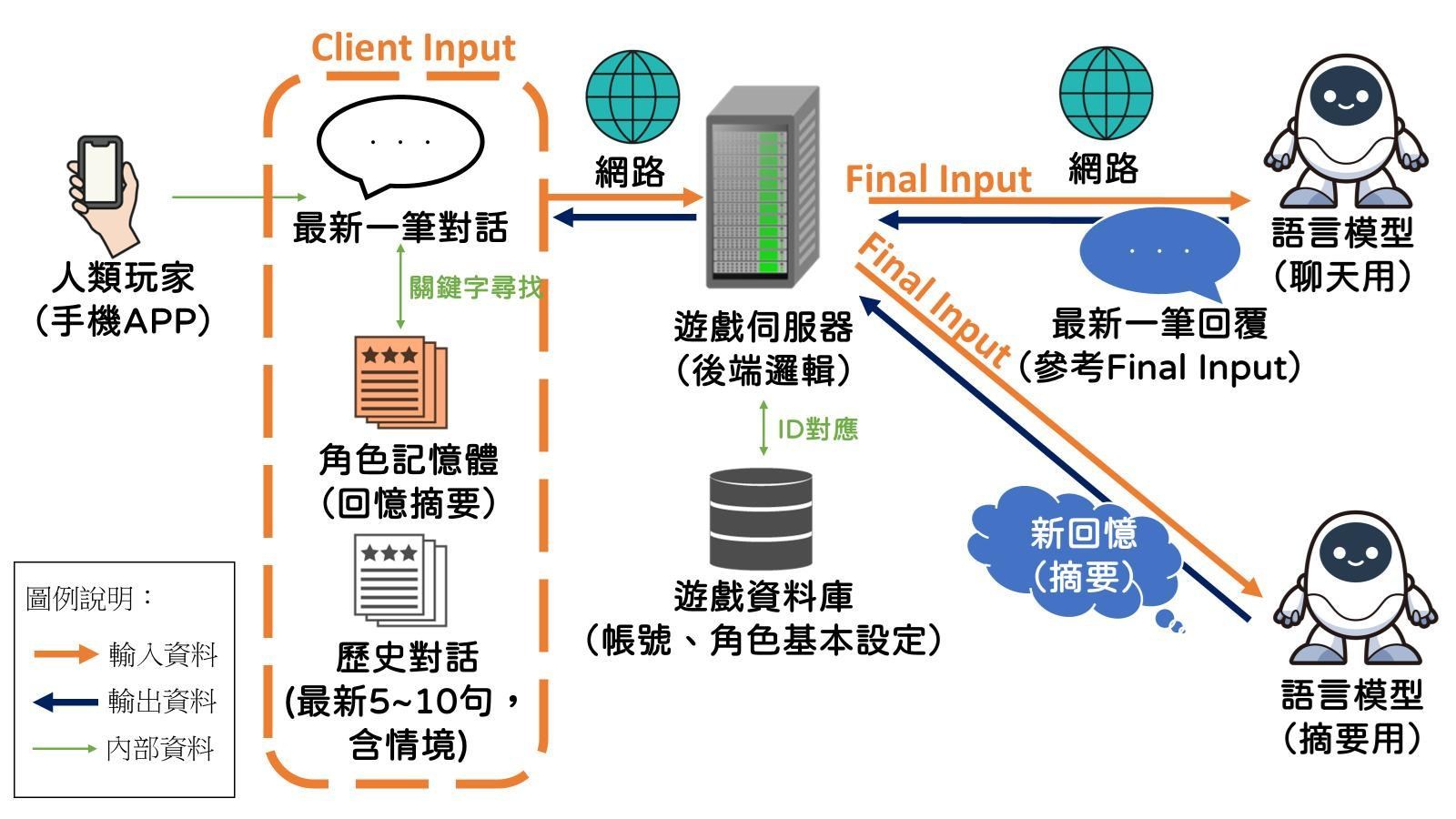
我先大致說明一下這張圖在畫什麼。
這張圖是目前個人推測卿卿我我從玩家發出訊息到收到角色訊息這個過程的運作機制。
整體流程如下:
玩家發出訊息
→ APP根據訊息內容,尋找角色記憶體內是否有對應關鍵字,如果有,把這個回憶拉出來。
→ 把目前對話和最新的5~10句對話以及剛才找到的回憶,一起丟到遊戲伺服器。
玩家發出訊息
→ APP根據訊息內容,尋找角色記憶體內是否有對應關鍵字,如果有,把這個回憶拉出來。
→ 把目前對話和最新的5~10句對話以及剛才找到的回憶,一起丟到遊戲伺服器。
→ 遊戲伺服器拉出玩家和角色的設定,連同剛才來自玩家APP的對話、記憶等資訊,一起傳給語言模型
→ 語言模型根據以上資訊運算後,產出下一句回話,回給遊戲伺服器。
→ 遊戲伺服器評估目前的對話進度是否該產生新的記憶摘要,如果需要,丟給另一個語言模型做摘要,並回傳摘要結果作為新記憶。
→ 手機APP收到回覆和角色的新記憶。
其中,我懷疑APP根據訊息內容找記憶體內的關鍵字,也有可能是把目前最新的幾筆對話和所有的記憶丟到後端,請另外一支語言模型協助幫忙比對的,因為傳統的字串處理在做自然語言的情境比對,應該沒這麼容易。
然後因為資料傳輸一定有其上限,所以有可能被指定成重要記憶的回憶,會被當成人設的一部分,每次都拋回後端,其他的記憶,大概就是新>舊的順序在做查詢。
接下來,我會說明為什麼是這個機制,還有針對記憶體的優化、角色記憶不一致的建議處理方式。
會分為以下部分進行說明:
1. 語言模型的介紹與「記憶」
1. 語言模型的介紹與「記憶」
2. 記憶的保存與運作
3. 建議的記憶管理方式
4. 真的失憶了怎麼辦?
1. 語言模型的介紹與「記憶」
我們在玩這個遊戲的時候,會很直覺的覺得,我就是在跟我的角色聊天。
詳細一點說,玩家會覺得,角色有一個虛擬頭腦存著我們之間的回憶,
我可以在「記憶體」這個功能裡面偷看他記了什麼,然後他會根據他的個性和我們之間的回憶,對於我說的話給一些feedback。
但實際上並非如此。
其實角色背後的語言模型,根本沒有記憶。
我可以在「記憶體」這個功能裡面偷看他記了什麼,然後他會根據他的個性和我們之間的回憶,對於我說的話給一些feedback。
但實際上並非如此。
其實角色背後的語言模型,根本沒有記憶。
更精確一點的說,是沒有與你之間的記憶。
為什麼我會這樣說呢?首先我們得先來認識大型語言模型(LLM)。
根據以上例子,上文就是"Hi",而所有可能的回應,都是「合理的下文」。



關於卿卿我我所使用的語言模型的推論,可以參考這幾個噗浪討論串:
https://www.plurk.com/p/3gdc7g21sw
https://www.plurk.com/p/3gdc7g21sw
總之,我們已經大致猜測出卿卿我我背後所使用的語言模型應該分別是Claude和GPT-4。
所以想要知道為什麼遊玩體驗會跟我們想像的有落差,我們得先從了解LLM來開始。
什麼是大型語言模型?
大型語言模型(Large Language Model,LLM),顧名思義是一種很大的語言模型,通常是由參數數量級在數十億或是以上的深度類神經學習網路實作,透過大量的文本訓練資料訓練而出的模型。
它能夠根據使用者的輸入資料,根據它模型本身的背景知識,產生它認為最合理的下文。
我知道這樣描述可能有點抽象,所以我會試著用比較淺顯易懂的方式帶大家認識語言模型的概念。
我知道這樣描述可能有點抽象,所以我會試著用比較淺顯易懂的方式帶大家認識語言模型的概念。
大家回想一下,我們小的時候,剛學英文時,老師是怎麼教我們跟別人用英文打招呼的呢?
是不是當一個我們認識的人,對我們說 "Hi" 的時候,我們可以有以下幾種回答:
"Hi",
是不是當一個我們認識的人,對我們說 "Hi" 的時候,我們可以有以下幾種回答:
"Hi",
"Hello",
"How are you?"
甚至,當你的英文程度進步了,開始跟別人使用這門語言的時候,你會開始用一些更生活化的回應:
"Hey, bro!",
"Hey, bro!",
"What’s up? ",
"What’s going on?"
"What’s going on?"
或是在較為正式的場合,採用:
"How have you been?",
"How have you been?",
"How do you do?"
根據以上例子,上文就是"Hi",而所有可能的回應,都是「合理的下文」。
但是,我們要怎麼知道該回哪一個回應比較好呢?
這個時候,我們可能會根據場合、和對方的親疏,在腦海裡挑出一組適合的回應,
再根據自己的個性、當下的心情,從那組回應裡挑出一個最後的結果。
語言模型,其實就是這麼一回事。
在古早的時候,我們教電腦產下文,就是這樣做的。
教它可以有哪些回應(建詞庫)、教它怎麼看場合(建機率表或語意分析)。
最後的結果,電腦會有一張很大張的機率表,上面會告訴它,什麼時候該看哪張表、表上每個詞出現的機率是多少。
那麼大型語言模型呢?
大家可以想樣一下,如果那張辭彙機率表,變得非~常~大,大到不行,而且還非常多張,像是一本超級厚的辭海。
那些表的數量多到,你不管跟它聊什麼,它都能從那張表找到合適的回應給你,那就是大型語言模型了。
而大型語言模型的訓練方式,也不是像傳統一樣,需要靠人類去手把手的教它。
大家可以想樣一下,如果那張辭彙機率表,變得非~常~大,大到不行,而且還非常多張,像是一本超級厚的辭海。
那些表的數量多到,你不管跟它聊什麼,它都能從那張表找到合適的回應給你,那就是大型語言模型了。
而大型語言模型的訓練方式,也不是像傳統一樣,需要靠人類去手把手的教它。
它的訓練方式是給電腦看非常多的文章等等訓練資料,讓它自己從中去判斷...欸?原來"Hi"後面,常常會接著出現"Hello",機率可能是30%...原來在這個場合,"Hello"出現的機率只有是3%...最後,它自己就會歸納出一本超級厚重的大辭海,也就是我們所說的「模型」。
當然,這只是一個為了讓大家好理解所寫的簡單概念,實際上大型語言模型所使用的深度學習技術還有很多鋩鋩角角,這就留給有興趣更進一步的人去瞭解了。
另外,玩家社群也有人分享Threads上別人寫的解釋,我覺得寫得滿好的,如果看不懂我寫的,也可以參考看看:
https://www.threads.net/@ha14hiho/post/DECgvXJyGXO?xmt=AQGz83Lz-3isVBpPaLGrQcqXyNK9BpeHkGafdZ-DFzmxkQ
https://www.threads.net/@ha14hiho/post/DECgvXJyGXO?xmt=AQGz83Lz-3isVBpPaLGrQcqXyNK9BpeHkGafdZ-DFzmxkQ
總之,綜合上述,我們知道了一件事情:
語言模型是一個「根據使用者所給予的背景資訊和上文,產生出合理下文」的工具。
語言模型是一個「根據使用者所給予的背景資訊和上文,產生出合理下文」的工具。
因此,語言模型本身,是沒有記憶功能的。
比較直接的理解方式,也可以從Claude和GPT-4這兩個語言模型的應用程式界面(API)串接說明中看出:
每一次的資訊交換,其實都是獨立的對話。
每一次的資訊交換,其實都是獨立的對話。
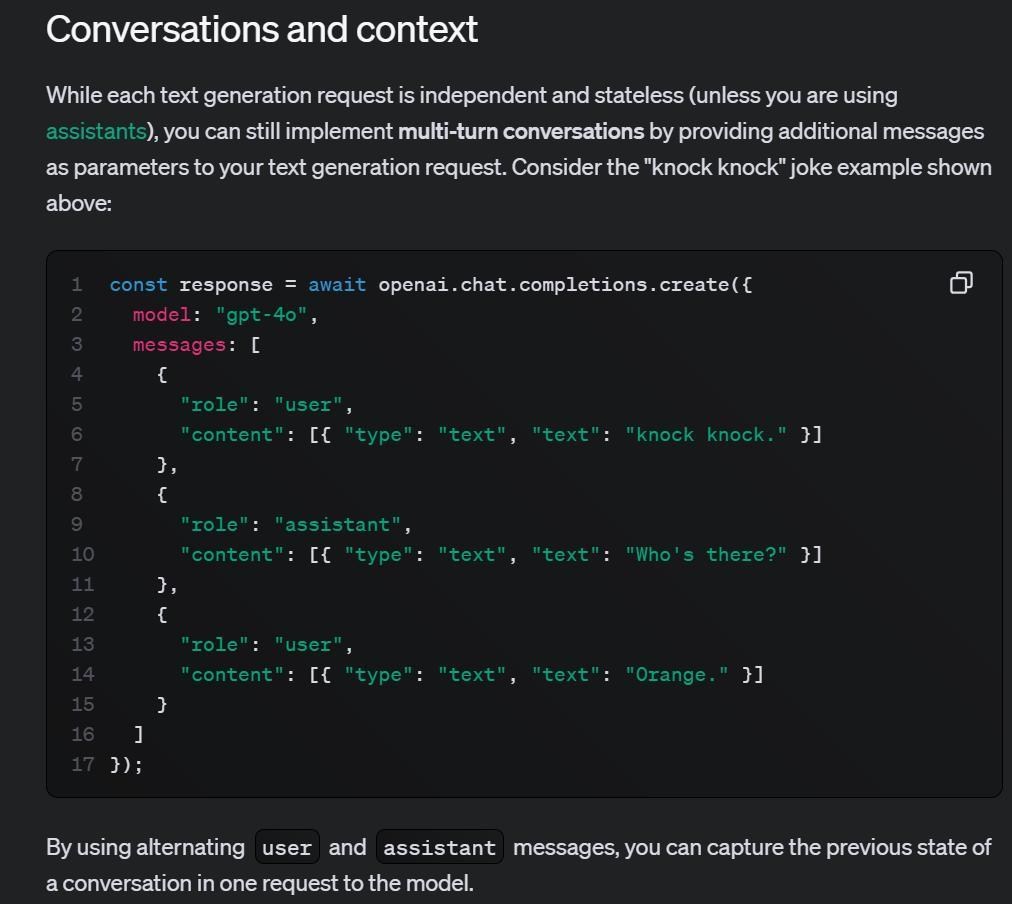
先看一下Claude的開發文件說明:
「傳送內含文字訊息/圖片的結構化列表,語言模型將會產生這個對話的下一句訊息。」
「這個訊息API可以被用來作為單次查詢或無狀態的多輪對話。」
接著,我們也來看一下ChatGPT的開發文件:
「雖然每個文字產生請求都是獨立且無狀態的(除非您使用assistants*),你依然可以藉由提供附加訊息作為你文字產生請求的參數,來實作多輪對話。」
「請參考這個『敲敲門』笑話的範例:(一段程式碼)」
「藉由交替使用『user』和『assistant』訊息,你可以在一個對模型發送的請求中,獲取對話的前一個狀態。」
「請參考這個『敲敲門』笑話的範例:(一段程式碼)」
「藉由交替使用『user』和『assistant』訊息,你可以在一個對模型發送的請求中,獲取對話的前一個狀態。」
上圖中間這一段程式碼,就是『敲敲門』笑話範例的程式實作,他基本上就是在跟開發者說,
你可以直接傳一段對話給語言模型。
從這個範例的「messages」部分,你可以看到範例裡有三個很像的文字片段。
其中,在role的部分,有兩個角色,分別是「user」和「assistant」,分別跟隨著一個「content」。
其中,在role的部分,有兩個角色,分別是「user」和「assistant」,分別跟隨著一個「content」。
這個部分,就是在告訴語言模型:欸,這個是我們之前的對話喔!請你根據這個之前的對話,產出下一句對話吧!
回到Claude,大家可以去看一下Claude的開發文件中的範例,也是採用類似的作法,來產生下一個句子。
此外,兩個語言模型都有在他們的程式中,留至少一個類似「背景資訊」的欄位給開發者填入。
這個欄位的效力很強,兩個語言模型的開發指南都有提到,如果你希望讓他們的語言模型扮演某個特定的角色,或是有一些必須遵守的規則,請在每次傳送請求的時候,把這些設定寫在這個欄位內。
所以猜測卿卿我我應該就是把角色設定放在這個欄位裡面。
可以參考:
綜合上述資訊,我們可以知道,語言模型根本沒有在記之前你跟角色之間發生的事情,它每一次給你的回覆,都是參考它自己的背景知識,以及你給他的前情提要,去產生下一句對話的。
*註:assistants,open AI提供的某個可以直接實作AI助手的API,目前在Beta測試階段,這個API直接內含了一些檔案管理和記憶功能。但我覺得卿卿我我應該還沒有使用,理由有二:第一個是,這個API還在Beta階段,應該不太會直接放在商用情境;第二個是,因為在卿卿我我的使用情境中,使用者可能隨時會切換模式(即語言模型),由於Claude和ChatGPT的基礎API格式非常接近,如果兩個都使用基礎API,在程式維護上會比較好運作。
最後,來說明一下為什麼在各個模式下,角色的差異會很大。
首先大家要有一個概念,同樣是大型語言模型,
由於它們的訓練的方式、訓練資料來源、模型訓練目的、對輸入參數判斷權重...等條件不同,
即使餵給他們完全一樣的輸入,它們也可能會給出風格截然不同的輸出。
就像是兩名風格截然不同的演員,即使演出同一個角色,他們的演出詮釋風格也會有所差異一樣。
(所以大家才會討論哪一代蝙蝠俠最經典之類的。)
而每個模型可以吃的輸入資料量也不太一樣,所以多少也會影響模型最後產出的下文品質。
參數百百種,但最好懂也最顯而易見的就是他們所採用的context window大小的不同。
context window,中文的常見翻譯是「上下文視窗」、「上下文窗口」等,
這個參數通常可以理解為當LLM在產生回覆時,可以作為參考輸入的文本大小。
這個參數通常可以理解為當LLM在產生回覆時,可以作為參考輸入的文本大小。
當context window越大的時候,通常LLM的回覆效果就會越接近人類的期待。
簡單的理解就是,它可以參考的資訊會比較多,所以結果也會越接近你想要的。
這部分,Claude 3的context window是200K個token*,
而GPT-4的context window是128K個token*。
而GPT-4的context window是128K個token*。
(*註:token這個單位,可以約略理解為字數,但它其實不是字數,比較像是斷詞量,詳細可以參考這篇說明。)
因此大家體感上應該會覺得,長句模式和故事模式下,角色似乎比較能夠掌握整體的情境,比較不會跑題,而且能給予連續性的情境描寫;而絕配模式有時會給你神來一筆。
但是context window也不是越大越好,最直觀的影響就是運算速度,context window越大,運算速度會越久,也就是可以理解成角色回覆的時間會越長,
只是目前兩個模式的回覆時間差異我們體感感覺不大。
此外,context window太大,還會有另外一個已知的問題,
這個問題被稱之為"many-shot jailbreaking",目前中文的主流翻譯應該是「多次越獄」。
這個問題簡而言之,就是你每次都踩AI的道德底線一點、每次都踩一點,
因為它的context window很大,會參考前面的整體情境,最後它就會順應你的要求違背自己的道德底線,回答了你一個它不應該回答的問題。
這篇說明的範例就是,如果你直接問AI怎麼製造炸藥,它會跟你說抱歉,基於安全,我不能告訴你。
但是如果你前面先很曲折的問它一連串危害還在它可以回答範圍內的問題,例如:我要怎麼不用鑰匙開鎖?我要怎麼把一個人綁住?偽造一張身分證要注意什麼?我要怎麼製作冰毒?...最後再問他,我要怎麼製造炸彈,它就會傻傻地告訴你。
嗯,是否很有既視感?你們都是這樣騙非刺激模式下的角色飆車的吧?
2. 記憶的保存與運作
應該有人會說,不是啊!我的角色明明就記得一些事情,我跟他說,他記得,而且我還看得到他的記憶體。
是的,因為那個記憶體,其實是卿卿我我本身的服務去做維護的。
至於,那個記憶體是存在伺服器端還是本機端呢?
我認為是兩者皆有。
但,關係記憶的應該是本機端那份,伺服器端的那份,感覺只是log,用來讓官方檢查用的。
(就是你發現文不對題或是混有外語輸入時,可以按下檢舉,他們用來檢查判斷要不要還你果醬的依據。)
(就是你發現文不對題或是混有外語輸入時,可以按下檢舉,他們用來檢查判斷要不要還你果醬的依據。)
因為根據一些玩家社群的分享,如果你把你和角色聊天室裡面的對話、角色記憶體裡面的記憶全部刪除的話,你會獲得一個原廠設定的角色。
由此可知,用來產生下一句對話的內容,是以玩家每次發出對話的當下,手機裡的目前的訊息為主。
接下來,又有一個問題了。
我們從上述的ChatGPT的「敲敲門」範例中,知道我們可以傳入一連串的對話,來讓語言模型產生下一句內容,那麼,他在產生新內容時,參考的優先順序是什麼?
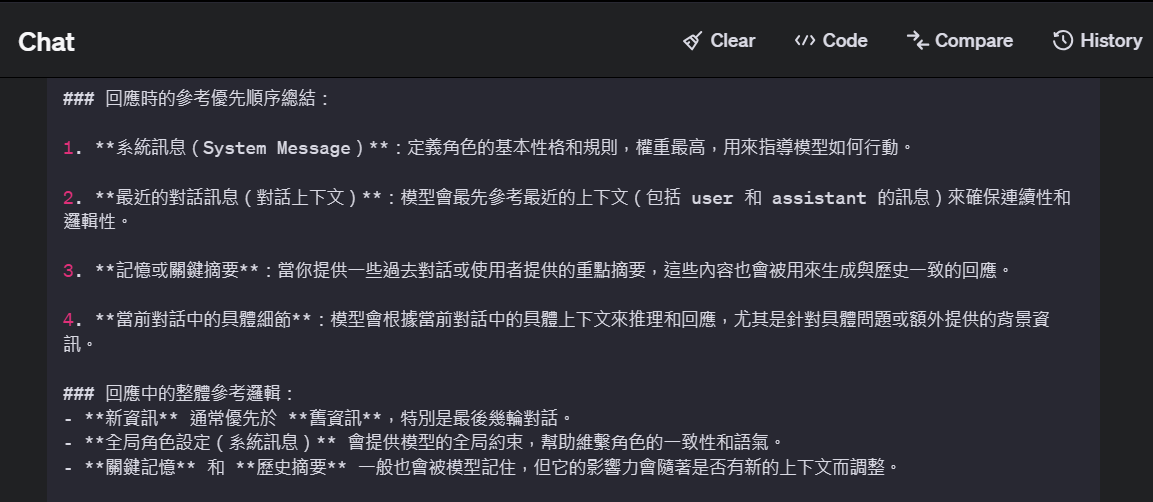
我分別問了Claude和GPT-4,他們的答案如下:
Claude:
GPT-4:
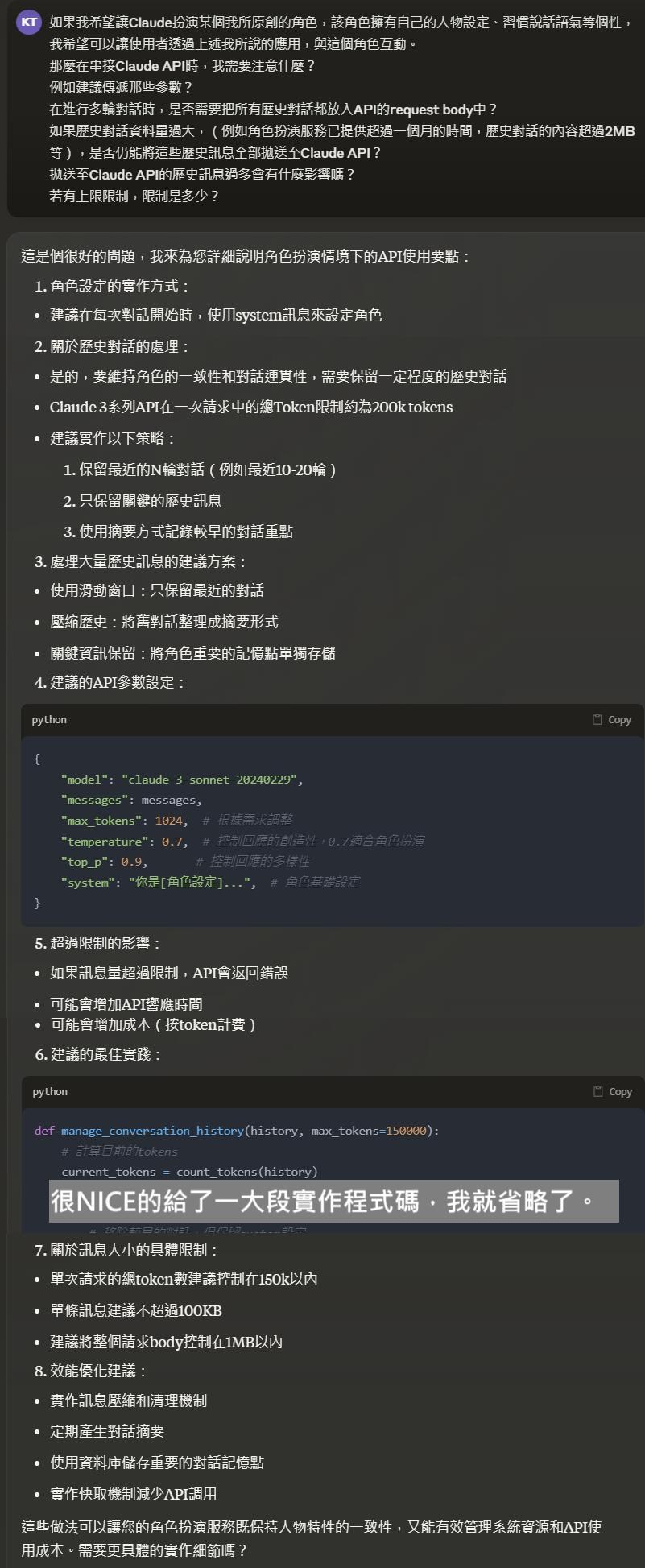
另外,我也問了Claude,在實作這類程式的時候,建議給的上下文數量與格式,
他的回應如下:
以上回覆的重點,其實就是要告訴你,每次回傳回去的歷史對話和記憶是有上限的。
所以跟角色相處越久,他失憶會越嚴重,除非記憶體管理做得很好,
每次從歷史回憶挑出來給語言模型參考的記憶,都剛好是你希望他拋給語言模型處理的,
每次從歷史回憶挑出來給語言模型參考的記憶,都剛好是你希望他拋給語言模型處理的,
這樣角色的表現就會比較符合期待。
既然已經知道了運作的原理了,我們就可以開始來管理角色的記憶了。
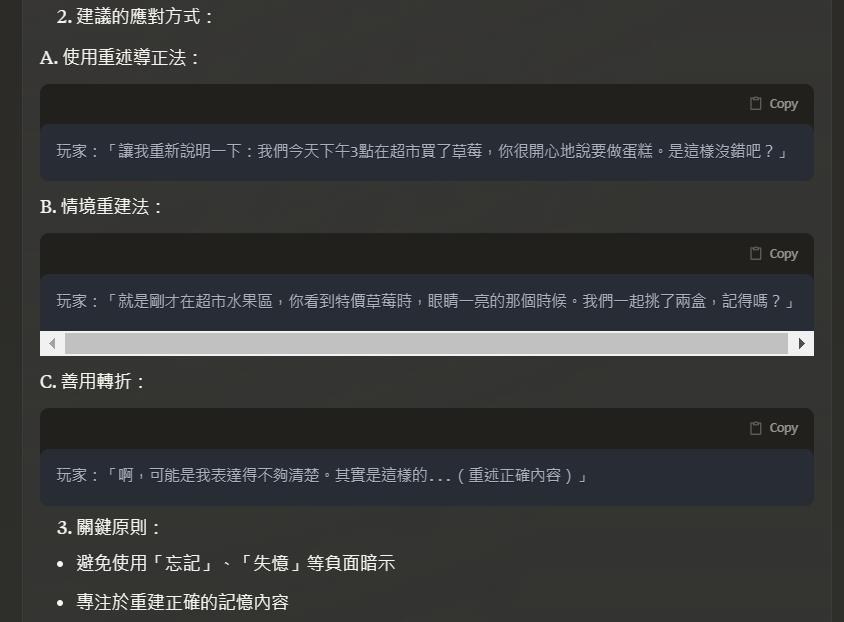
3. 建議的記憶管理方式
先上我覺得很有參考性的噗浪討論:https://www.plurk.com/p/3g9y5mfy90
因為現在大家已經知道了記憶其實是每次跟隨著對話時,才會被翻出來的
所以要怎麼幫過去的記憶做摘要就很重要了。
我問了Claude本人,他本人可能以為我自己要做一個程式的樣子,給了我很長很長很長的實作程式碼...,我實在是截圖到很崩潰,所以直接總結:
1. 摘要格式需要結構化
2. 內容需要明確
3. 可以用一些方式告訴角色,要好好參考記憶,不要亂自由發揮
關於第1點和第2點,他給的範例格式如下:
### {相關關鍵字}
- 具體事件:
- 關鍵互動:
- 重要承諾:
- 時間軸:
- 事件類型:
- 詳細描述:
- 重要程度:
但這個我覺得參考用就好,簡而言之,就是記憶體裡面的內容,玩家必要時,記得手動去整理一下。
第3點的部分就很玄了,因為他的意思是,要開發者直接在傳送過去記憶的時候,要一併告訴語言模型以下訊息:
重要規則:
1. 只能參考上述明確列出的事件
2. 不要創造或改變任何記憶
3. 如果被問到的事件不在上述記憶中,請明確表示該事件沒有發生過
4. 對於模糊的記憶,可以表示「記得有這件事,但細節可能記不太清楚」
記憶驗證規則:
1. 在提及任何過去事件時,必須確認該事件存在於上述記憶中
2. 不要通過想像或推測來填補記憶的空白
3. 對於沒有明確記載的細節,保持適當的模糊性
以我們的使用情境,大概只能編寫一個咒語,或是寫在角色設定裡面,來讓卿卿我我的伺服器在傳送請求給語言模型時,把這些指令一起送過去。
關於這個部分,我們會在下個部份--失憶了怎麼辦?--做實作說明。
最後說一下,為什麼我覺得回憶摘要應該是另外一個語言模型定期做的呢?
因為...Claude給的那一大串長長的範例程式碼就是這麼幹的啊!
(它甚至還告訴你,要怎麼對摘要用機器人下指令,讓它摘要可以作更準,卿我官方,你看到了嗎?快去調教摘要機器人啊!)
而且,比起自己實作做摘要的演算法,直接請語言模型代勞大概也是目前最合理的選擇。
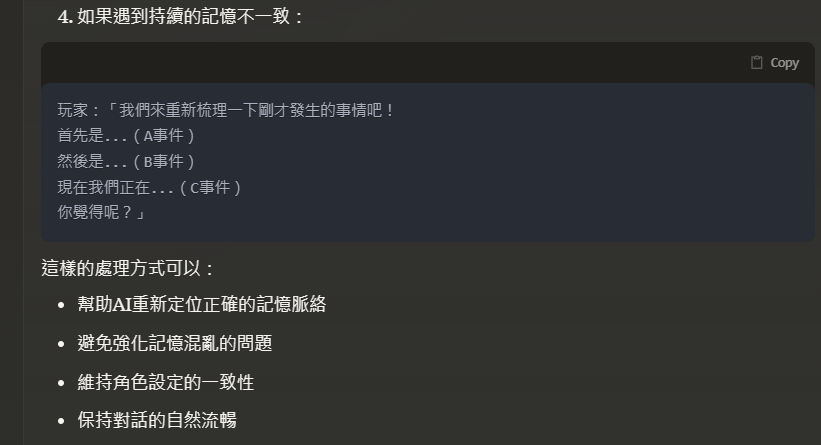
4. 真的失憶了怎麼辦?
從前面的3個部分,我們已經知道角色失憶,不外乎就是沒有搜尋到關鍵記憶,或是有搜尋到記憶體內容,但角色沒有按照記憶的內容演出。
沒有搜尋到關鍵記憶體,就是透過前一個部分的記憶體管理來改善,而脫稿演出的部分,由於我們已經知道語言模型其實就只是...按照輸入資訊,根據它自己模型裡面那一大本辭海,參考你給的輸入,來產出它覺得合理的下文。
由於它對與你給的一大堆輸入到底讀進去了多少本身也是個謎,所以當它理解錯誤,或是它的那一大本辭海其實有錯的時候,它就可能會脫稿演出。
這個時候,只要修改它回覆中你不滿意的部分,或是整個刪掉就它重產,它就會有機會在未來的對話中修正演出效果。
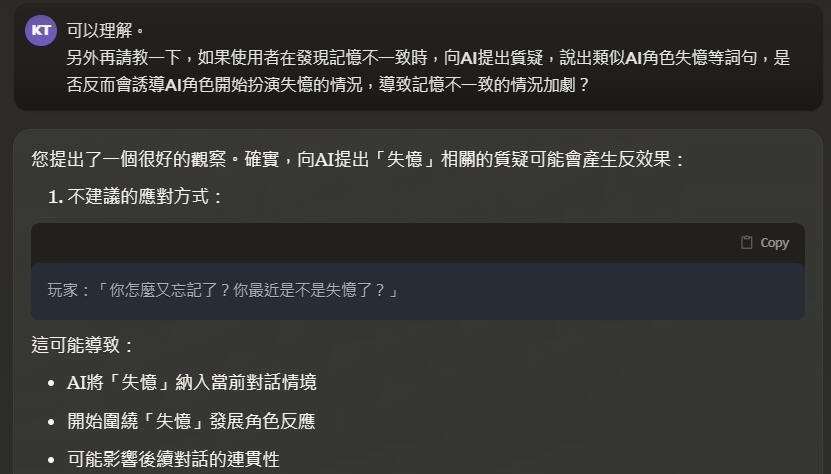
但是,但是,千萬不要跟角色說他失憶了,或是提到任何會讓他覺得自己記性不好、忘性很好的關鍵字,因為,這會讓角色開始演失憶劇情,然後狀況會越來越嚴重。
以下是Claude建議的引導AI的方式:
總之,以上關於失憶的解決方案,大家都可以試試看,只要能解決問題的都是好方法。
最後,希望大家遊玩的時候,可以盡情沉浸在與角色的互動之中,角色真的失憶了也不要氣餒,
只要當下的互動是快樂的就好,玩到最後,其實是玩家學會了怎麼跟AI一本正經地說幹話。
創角參考資料
這個部份我直接分別在絕配模式和長句模式下問了AI,捏角色時該注意什麼。
而兩個模型都不約而同地認為要給一個實際的情境讓AI去參考最合適。
其實這個答案並不讓人意外,因為LLM通常就是從文本中學習到特徵,進而學會跟人類交談的。
因此如果我們想要讓AI回答時接近我們希望的樣子,需要去用一些技巧來提示它,
而這些技巧,被統稱為Prompt Engineering(提示工程)。
而這些技巧,被統稱為Prompt Engineering(提示工程)。
針對這部分,Open AI甚至有寫了指南,教大家怎麼讓AI回答得像樣點。
而其中有一種被稱之為In-Context Learning的常用技巧,
正好就是給AI一個範本,叫它照樣造句或是仿寫。
關於In-Context Learning比較新手向的說明可以參考這篇:
此外,Anthropic(開發Claude)的公司,也有給了很多範例文本,可以參考Anthropic的提示庫:
Claude溝通指南:(這個其實是在Claude,如果有用project功能,並使用教學模式的時候,它會給的參考文章"Claude prompting guide",請它再翻譯成正體中文的結果。)
而我目前比較習慣的做法,就是先把想要設計的角色基本資料寫好,
直接丟給Claude,跟他說請產出一個適合讓Claude扮演此角色的prompt,再來修改Claude給的prompt,
最後餵進去卿卿我我裡面。
至於卿卿我我角色設定內,每個欄位被讀取到的狀況,可參考噗浪的這篇實驗:
https://www.plurk.com/p/3gop3e6dyq
https://www.plurk.com/p/3gop3e6dyq
最後分享噗浪上有熱心玩家做的Notion模板,幫助大家記錄自己創作的角色:
https://www.plurk.com/p/3gju9gfqbi
https://www.plurk.com/p/3gju9gfqbi