主題
 達人專欄
達人專欄
前言
Object Detection作法主流分為1 stage 和 2 stage approach。籠統一點來講的話,1 stage approach如yolo,經過一個regression就得到輸出;2 stage approach如faster rcnn,經過2個regressor得到輸出。
這些上課都聽過的觀念都很好講,但實際用code組織pipeline後才發現許多眉角。 這邊先提個簡單的問題,看看大家是否曾經也有一樣的疑惑。
Q1: 在2 stage approach的 Faster rcnn模型中,輸入什麼到stage2的regressor,使其輸出bounding box?
- Stage1輸出的Proposal Box 座標。
- Proposal Box 對應的Feature maps。
Q2: 假設RPN輸出 1152個bounding box,但實際的ground truth只有3個目標,這1152個bounding box要怎麼處理?
程式碼同樣到個人網站 觀賞效果較佳。
學了半年,踩坑血淚史。 (設計不同box格式的動機是為了實驗,如果用預設bbox格式大概就不會接觸到這麼多了。)
(設計不同box格式的動機是為了實驗,如果用預設bbox格式大概就不會接觸到這麼多了。)
(設計不同box格式的動機是為了實驗,如果用預設bbox格式大概就不會接觸到這麼多了。)Object Detection
objection detection是ML的應用之一,跟classisfication差別在於objection detection需要標記出物件所在的位置。 標記方法通常是bounding box (bbox)、mask、Keypoint等。
標記方法當然也可以自己設計,本篇的範例中,我們設計了一種結合bbox和keypoint形式的資料型態,為了方便稱呼,先簡稱為polybox。 它由box的中心座標(x_c , y_c)展開4個角落的座標點(x_1, y_1 ) ~ (x_4, y_4 ),這四個點以相對於中心點的座標形式儲存。

Faster RCNN
關於faster rcnn的講古文網路上很多,這邊就只打重點了:
- 在Stage1之前,它會在圖片平均分布n*m個 Anchor point,每個anchor point分別展開asp * size 個anchor box。這些anchor box會做為之後的基底重複使用 (只需在開頭生成一次即可)。
- Stage1 有個網路叫Region Proposal Network (RPN),含有一個Regressor和Classifier。 Regressor輸出bounding box的log(偏移量),Classifier輸出二元分類 (True/False)。
- Stage2 通常稱為模型的Head,同樣含有一個Regressor和Classifier做跟stage1差不多的事,只是這裡的Classifier輸出的是多元分類。

Backbone 是什麼
Backbone是模型中用來初步提取特徵的一環。Backbone網路的泛化能力要佳,現在我們直接call API下載的pretrained backbone是別人train好的成果,通常是已經train在大量資料上train一段時間,且有一定的測試水準。 若我們在組pipeline的時候沒引入pretrained backbone就會需要train很久很久很久.....。
Backbone常用的有: VGG-19、ResNet-50等U-Net結構,後面的數字代表層數,越深的層代表模型越胖,train的時候記憶體消耗更大。 舉例來說,Pytorch預設的faster rcnn backbone為MobileNet,MobileNet的設計理念是輕量,沒有像ResNet那麼多層。使用MobileNet train出來的模型check point檔案大小為300MB左右、而ResNet-50為1GB左右。

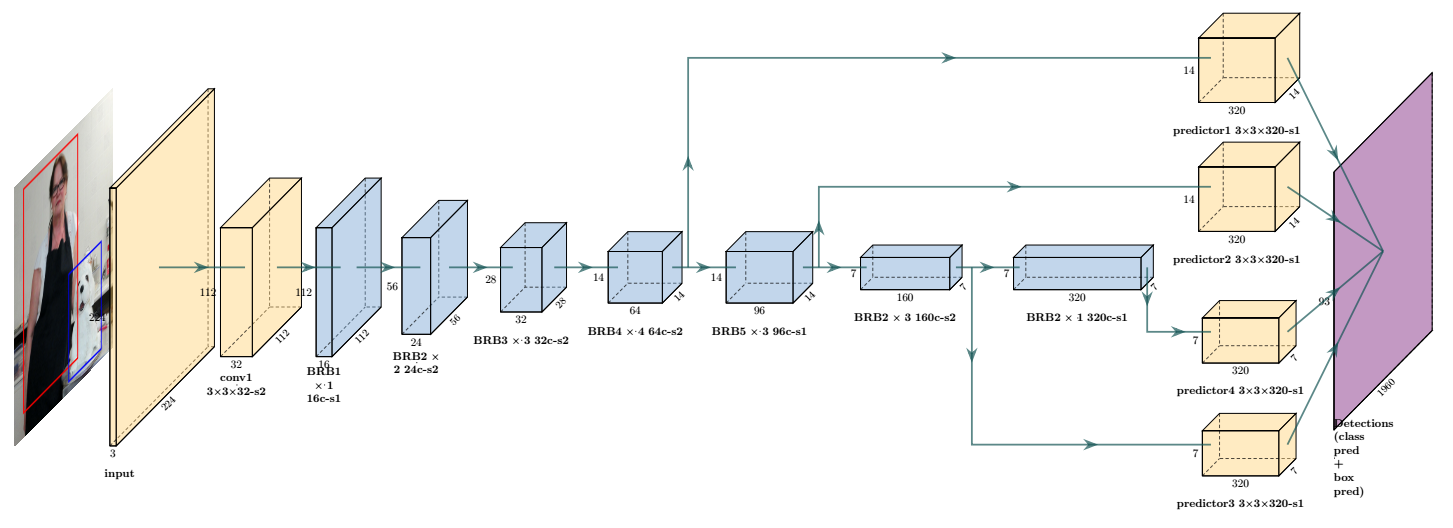
MobileNet架構 MobileNet-Tiny (nitheshsinghsanjay.github.io)
Q:Backbone會影響模型成效嗎?
A:會。但若不是以追分為前提,用哪個backbone基本上都能完成任務。模型開發階段應思考的是pipeline怎麼處理資料,而不是要用哪個backbone。
Anchor Box 生成邏輯
以Resnet-50來說,它的stride為32,例如輸入 512*256 (channel 3)的圖片進去,得到的feature map為16*8 (channel 2048),表一張圖片可以塞下16*8個anchor point。

Q:為甚麼是feature map解析度決定anchor point數量?
A:feature map上面像素的亮度,可以視為神經激活程度(信心值的指標)。anchor point數量對應feature map的解析度,比較方便我們用激活程度去找對應的anchor point。當然你也可以自己設計feature map上面的資訊怎麼對應anchor point。


Anchor point example.
Understanding and Implementing Faster R-CNN: A Step-By-Step Guide | by Neeraj Krishna | Towards Data Science 
Understanding and Implementing Faster R-CNN: A Step-By-Step Guide | by Neeraj Krishna | Towards Data Science
有了anchor point後,再根據size和aspect 的設定,在每個point上產生size*aspect個box。 例如size和aspect各3個時,會產生9種大小的box。整張圖片就會有 16*8*9*4個資訊。 (長*寬*box數量*每個box需用4個數字表示)
RPN怎麼做
Backbone的feature map初步會送入Stage1 的Proposal 模組做處理,分別輸出信心值、log(offset)。
注:
- Faster Rcnn用 1*1 kernel的conv層取代fully connected network。
- reg_head 被註解的那個是因為我們的Polybox格式為n*10 。 (預設bbox為n*4)
定義一模型:
輸出的大小為:Classifier : [batch , 9 , 16 , 8 ], Regressor : [batch , 9*10 , 16 , 8 ]。 剛好對應上anchor point的數量,意即只要找到Classifier輸出大於一定值的index,可以做為索引anchor box之用。
範例程式:

Loss設計邏輯
RPN層的Classifier和Regressor預測後,該結果跟真實資料比較,得到loss值以進行訓練。 上述會一直強調Regressor輸出的是log(offset),是因為網路文章幾乎沒有談論到計算loss之前須進行的encode動作。

在paper裡面表明offset的寬度、高度處理。[1506.01497] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks (arxiv.org)
從程式來看,在Pytorch函式庫中可以看到它先把gt資料做encode的動作,才拿去跟regress結果計算loss。

實際定義:

這可以理解為一種標準化處理,例如proposal的寬度跟真實資料的寬度差不多時,log結果會接近0,則regress結果也應該是個接近0的數字。 大部分的時候log能幫我們把值限制在1.多以下,即使gt比proposal大了3倍,log結果=1.06。 如此能控制模型預測的值域範圍。 除以寬高則能起到放大的作用(因為資料值域為 [0,1])。
要輸出到圖片上的時候再decode得到真的座標即可。

Q: 如果regressor不輸出log(offset),而是直接輸出offset,拿去真實資料比較會怎樣?
A: 會很難train,因為資料的值本身就很小,誤差沒做處理會更小,導致loss看起來很小很漂亮,實際跑起來卻很糟。
完成到這裡,其實就是做出了一個1-stage approach的模型了。
加上Stage2
Stage2就像頂樓加蓋一樣,用一個網路去微調stage1的輸出。
以下跟著pytorch的架構做個簡潔的stage2模組:
邏輯:
- 將所有feature map打包,送去roi_pool層,依照proposal box的範圍統一切成n*n的小feature map。
- 多跑兩個全連結層加深一下。
- 輸出。
(因為cuda版本比較舊,跑到一半ops.roi_pool會無預警發生memory leaks的error,所以改用MultiScaleRoIAlign。)

Q:為甚麼要做ROI Pool?
A:也可以不做,然後拿整張feature map去train。 但stage1都幫我們標出哪裡是重點了,我們可以只抓那邊的特徵(ROI)再去學習會更有效率。 因為每個anchor box的大小都不一樣,切出的小feature map也大小不依,經過一個pool層將它們壓成固定大小才能接後續的全連接層。
參考/引用
- Understanding and Implementing Faster R-CNN: A Step-By-Step Guide | by Neeraj Krishna | Towards Data Science
- [1506.01497] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks (arxiv.org)
關於前言的解答:
Q1: 在2 stage approach的 Faster rcnn模型中,輸入什麼到stage2的regressor,使其輸出bounding box?
- Stage1輸出的Proposal Box 座標。
- Proposal Box 對應的Feature maps。
Q2: 假設RPN輸出 1152個bounding box,但實際的ground truth只有3個目標,這1152個bounding box要怎麼處理?
A: 在training 階段,會計算每個box跟每個gt的iou,根據原paper定義保留的規則達成以下任一個條件:(1.) 每個gt box對應最大的iou的anchor box、(2.) 對任一gt box iou大於0.7的anchor box。在inference階段因為沒有gt box輸入,則是保留信心值高於一定閥值的anchor box。