最近經常在VRchat中遊玩,並嘗試製作出屬於自己的avatar和使用素材,碰上一些問題。













 多邊形導致的頂點著色器負荷一直有著相當高佔比。
多邊形導致的頂點著色器負荷一直有著相當高佔比。


 拉近
拉近 拉遠
拉遠 關閉後僅有天空盒場景
關閉後僅有天空盒場景





 拉近幀數
拉近幀數 很遠的幀數
很遠的幀數






 你會發覺並沒有什麼顯著的問題在,因為光照及陰影根據三角形影響的計算不再明顯了。
你會發覺並沒有什麼顯著的問題在,因為光照及陰影根據三角形影響的計算不再明顯了。






 近
近 遠
遠










































在booth上有些未有名氣,但已經製作有相當時間的一些創作者,他們的模型多邊形(ポリゴン)即三角形數量通常都是偏高的,導致實際上在運作過程中造成較高的GPU開銷,而這些開銷對於相對低性能的GPU來說負荷顯得過重而無法解決,故此希望能講一些為什麼應該三角形數量要少的原因,讓閱讀者明白到底有多重要。
使用的資產(Asset)有
1. liltoon
2. ユー
運行環境:
1. Unity3D Built-in 2019.4.31f1
2.CPU 5600X 標準設置
3.32GB RAM 設為標準3200MHz CL16
4.RTX3060 標準設置
先將場景設置為純空場景(較深的藍色)
使用工具Nsight Graphics 2022.1.1
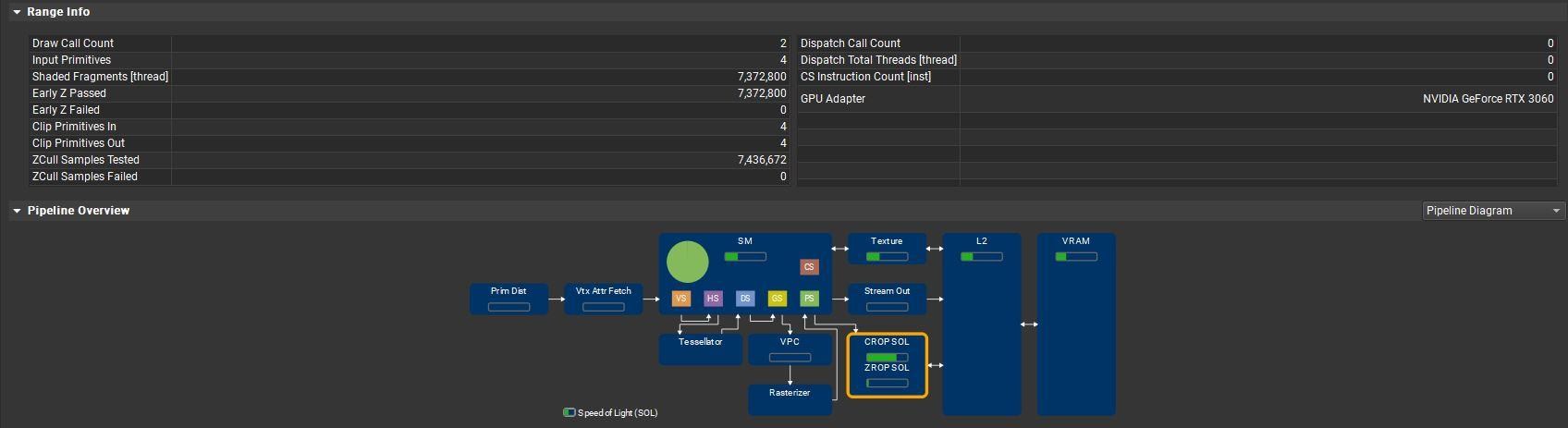
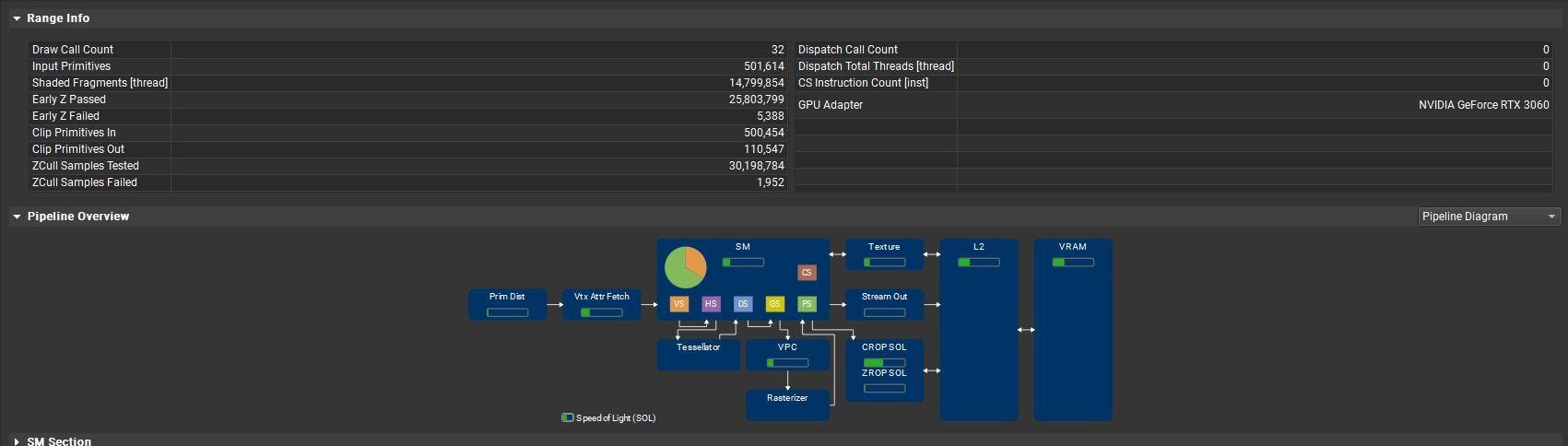
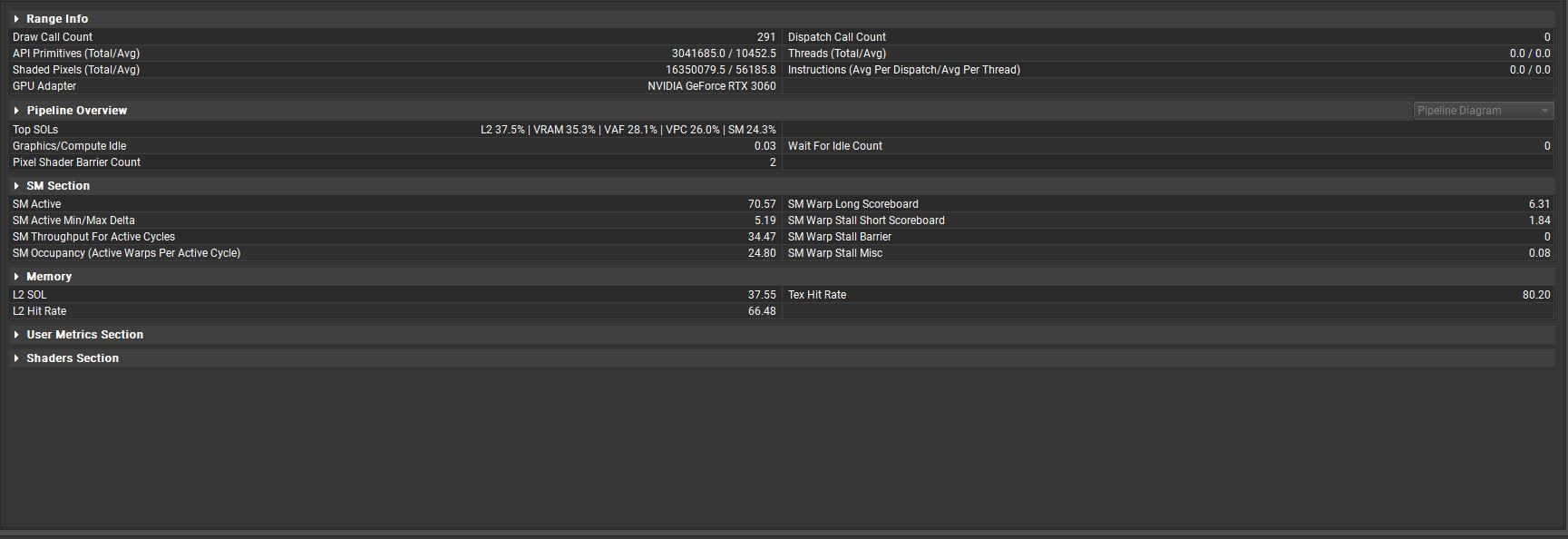
在解析度2k(2560*1440)下 一共繪製出7,372,800個像素開銷(每個解析度像素*2),負荷最大的是CROP完成混合工作。
將預設天空盒載入後(沒有光照)
進入profile後會發現:
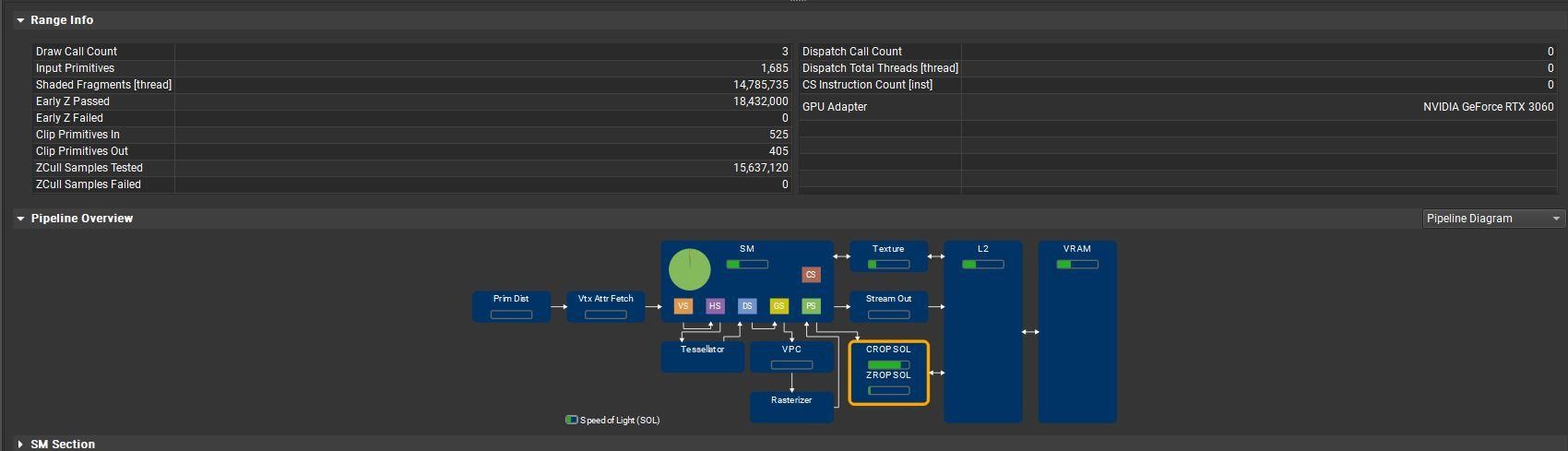
出現了一些 Primitive 並且繪製18432000個像素,約解析度的五倍,但一些像素並沒有繪製出來,負荷約15637120個像素。
這時啟用光照並進入profile中觀看
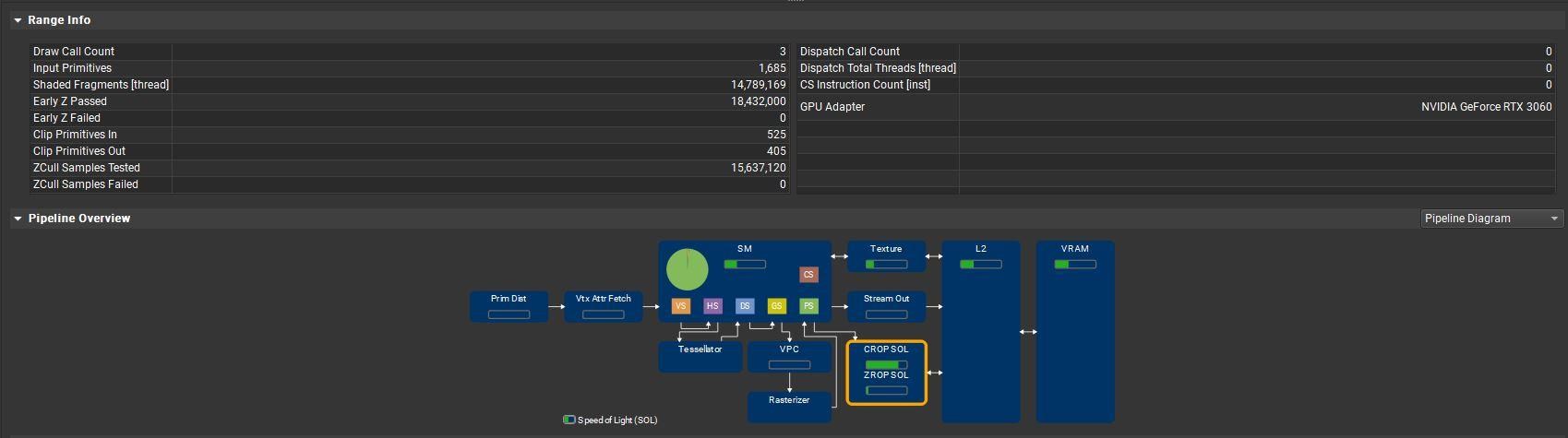
你可能會疑惑,是不是重複張貼一樣的圖? 其實並沒有,而是Unity3D單純開啟光照後並不直接影響天空盒,且不會對執行的物體產生過多的負荷。
可以直接透過放入白龍-yu做實測,省略了執行畫面直接看profile結果,並且為了不產生其他 Primitive,選擇關閉了陰影。 在Unity內置管線中啟用陰影是相當昂貴的,會導致GPU需要吞吐的圖元數量爆增並大幅度影響需要繪製的像素量,使得GPU耗時增加。
在第一張開啟了光照
第二張關閉了光照
可以發現其實執行負荷差距不大,開關光照後並沒明顯差異。
接下來透過了解上述資料後可以開始去了解具體執行三角形後大致會碰到哪些問題呢?
首先將我們的白龍放置入場景中,profile結果如上面一樣,就不重複張貼了。
然後將她拉近:
進入profile內:
可以發現Clip Primitives Out數量稍微上升,並且在Early Z passed及Failed都有些變化,尤其是Failed部分和『影響GPU幀時較顯著』的ZCull Samples Tested和ZCull Samples Failed。
其實這部分沒辦法簡短快速說明是Clip Primitves Out數量增加不是影響Early Z和ZCull出來像素負荷的直接原因。
並不容易快速解說,其實這是因為當primitve越接近camera,也就是我們所看到的螢幕空間,當在螢幕解析度中圖元(三角形)佔據越多螢幕上的像素,就會導致產生需要更多被像素著色器處理的像素,也是光柵化機制。
我們接下來透過把白龍拉到遠處了解這個光柵化的限制。
我們把白龍拉遠一點:
進入:
可以觀察到輸出的圖元和像素負荷都大幅下降了,這是因為背面剔除和部分剔除機制導致可見圖元大幅減少+遠離相機一段距離每個圖元被光柵化成像素的量大幅減少所造成。
接下來我們繼續拉開相機與白龍的距離:
進入profile:
將距離拉到很遠很遠:
你可能會疑問說,可見三角形數量不是一直在下跌嗎?根本不足為慮是吧?
可是:
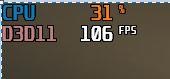
多邊形導致的頂點著色器負荷一直有著相當高佔比。相比於一開始很接近的狀態佔比是多少呢? 我們再次拉回來
你一定以為見鬼了,繪製數量不是大幅減少了嗎? 為什麼頂點著色器負荷還是這麼高?這是因為就算有方法有效剔除大量三角形,但由於三角形已經進入GPU前端幾何管線,勢必會產生存取頂點、剔除單元等開銷甚至有其他諸如修改頂點、三角形生成面等需求,已經沒辦法躲避了,能節省的主要也是光柵化後的像素部分了。
那我們使用MSI 微星後燃器測試幀數差了多少呢?
拉近拉遠關閉後僅有天空盒場景可以發現還是有一些提升的,透過拉遠距離使得被光柵化到的圖元、像素量減少獲得提升。
如果我們將白龍的數量增加呢?比如增加到原有的八倍(複製三次)
可以感受到頂點著色器負荷大量上升了。
此時頂點著色器負荷佔比持續上升
那跟原本近景比提升多少呢?
拉近幀數很遠的幀數你會覺得提升幅度還是很高的啊,跟上面單個比,增長幅度都約15~20%,不是很好嗎?
再次擷取資料比對
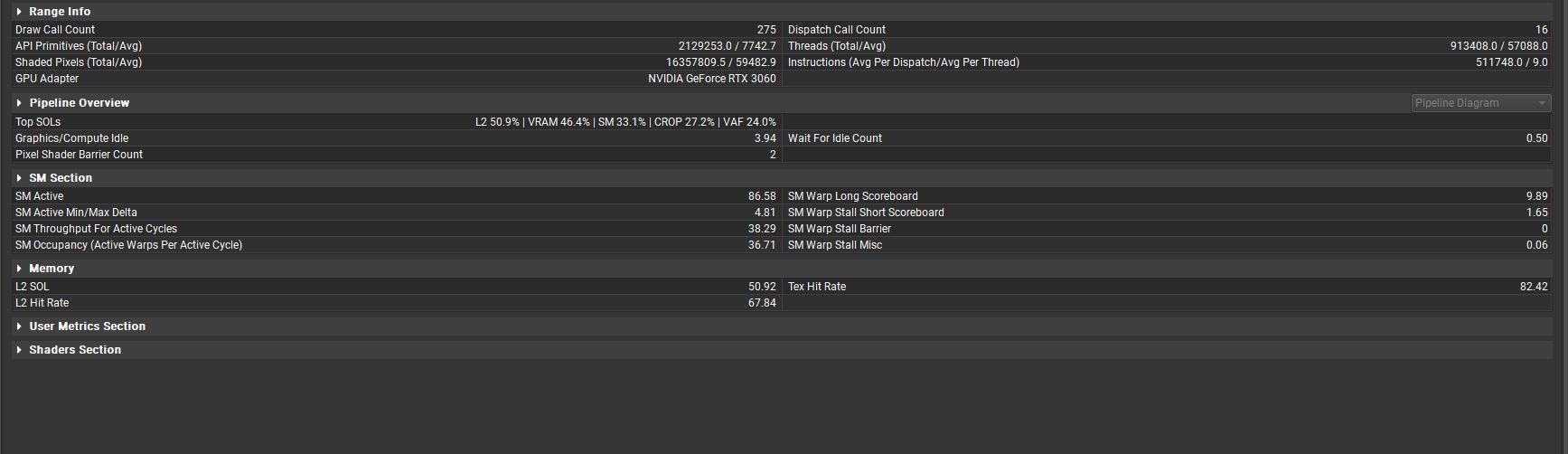
可以發現需要繪製圖元1567368個,需要繪製165984448個像素(156.7萬圖元、1.659億個像素)
需要繪製圖元310418個,需要繪製39633536個像素(31萬個圖元、3963萬個像素)
可以發現負載差距整整高達五倍圖元及四倍的像素量,可是運算時間只多20%,反過來看只剩五分之一的圖元和四分之一的像素量,我仍然得花費高達八成多的時間在繪製上!?
所以有效管控三角形的數量(Clip Primitives in)就變得相當重要了,從源頭上大幅減少可以有效提升效率。
這時候放上我使用blender大幅度減少三角形數量的Yu了。 不過在這提醒一下沒有很簡單快速不破壞外觀又能維持正常bone及Shape Key的方法,在這裡的時候已經破壞掉原有bone綁定和Shpae Key被消除了,而整個模型中最難處理的為臉部,無法透過簡單方式不破壞表面,會整個異常。
但即使是這樣,畫面還是正常的,因為toon shader的特性所以不會顯著反應出光照及陰影的問題,若是使用其他shader會這樣↓
原始版本是這樣的:
但在Unity3D並使用liltoon shader後:
你會發覺並沒有什麼顯著的問題在,因為光照及陰影根據三角形影響的計算不再明顯了。即使啟用了軟陰影以後:
但可能一些場景的著色器或後處理情況下會破功,但由於作者使用了liltoon shader,其實三角形數量並沒有那麼必要很高,只是為了邊緣平滑消除棱角,可以透過其他手段達成且更可控三角形數量,比如曲面細分技術或幾何著色器等,根據螢幕佔比調整生成的三角形,執行起來更高效,不過失控的濫用也會導致過多三角形效率低下。
接下來讓我們測試這個大幅度減少三角形後的白龍-Yu執行效率到底有多高吧! 從原始197688個三角形減少至21327個三角形(不過不能準確反應出進入遊戲引擎後的需要繪製的 Primitive數量,但有很高的可參考性,只是細節略有差異)
#更改:忘記關閉軟陰影
我們一樣複製八個的數量並擺放至遠處和近處:
分別觀察他們的profile結果:
近↓
遠↓
幀數比對:
近遠可以發現有不小的幀數提升,當一個場景內三角形數量更多,因為avatar數量非常多的時候,差距將會更為明顯。
測試時使用skinned mesh render而不是mesh render,所以如果閱讀者嘗試使用物件大量複製比對的效果會有不小差異,這是由於這兩種mesh render有所不同,一般的mesh render數量越多執行效率越高,而skinned mesh render數量越多本身效率較低再加上大量CPU sync拉低GPU利用率,會將彼此差距拉大,同時會造成更容易CPU瓶頸。
skinned mesh render可以利用2thread mesh render可以利用6thread,只是在dx11後者draw call先瓶頸。
以上場景測試均為GPU瓶頸。
由於最佳化三角形數量是一個繁重的美術工作,需要應用上很多技術和勞力,涉及到諸如法線、凹凸、視差、置換、位移...等等大量貼圖和烘培調整工作等,所以非常不容易。
在遊戲引擎上還有LOD與遮擋剔除這兩大場景管理技術來有效管理可見三角形數量進入GPU內繪製。
如LOD根據距離或相機佔據面積調整LOD條件,切換不同檔次的mesh,甚至根據曲面細分控制可見三角形數量也算是,於UE5上的Nanite可以說是最為強大的LOD。
根據不同條件如物件或mesh等的bounds或深度值判定進行,在動態或靜態場景上使用bake資料或根據場景持續更新深度緩衝值使用hi-z技術精確檢測mesh並剔除。
mesh越大只要見到部分就不能剔除,所以需要拆分,但是拆分會加重draw call或CPU與GPU之間交互負擔(不等同draw call),這時候還需要合併起來。
過度拆分成小mesh反而會降低GPU利用效率,所以需要適當,這就需要實測了解。
另外光柵化的限制還有微三角形的限制,一個三角形若無法被剔除掉並進入光柵化,最少會產生相當於四個螢幕像素的影響,如果你遠景有巨量密集的三角形,沒有做LOD或被遮擋剔除掉,即使你拉低解析度也會產生極高的像素著色器負荷,更別提本身幾何管線容易瓶頸了。
每個三角形會根據螢幕解析度產生不等同需要像素著色的像素,沒上限但會因為硬體設計的固定管線功能而有下限,取捨出來至少2x2,雖然在三角形非常大量的時候本身已經嚴重影響GPU的幀時了。
另外過多三角形也會加重CPU在繪製時的開銷,除非利用諸如間接繪製等手段(shader),犧牲一點一些的GPU效率換取大幅度減少CPU負荷。
三角形在光柵化後變成四個像素,根據 surface shader的設置在上面繪製,所以不同三角形所表現出的表面,其像素著色開銷有所不同,可能需要光照也可能需要陰影或是卡通(toon)、玻璃(Glass)等。
獨立遊戲在最佳化(優化)於GPU上最大的差距以我個人做profile的結果,往往來自於美術資產。因為三角形數量往往過多,且缺乏資源做很好的LOD或選擇不做LOD,僅僅只能使用遮擋剔除,且遮擋剔除又由於遊戲引擎內置的不同,使用上許多不易。
比如Unity3D內置Umbra使用bounds判定就在一些場景設計下注定很難被剔除掉東西,但由於其CPU在執行時開銷可以做實測近乎0,即使有非常大量的東西和烘培精度相當高,僅僅只是查表。
而UE4內置使用hi-z,雖然單位剔除成本相對較高,但其精度高得多,使得一些東西可以在牆後仍然被有效穩定的剔除。
3A等級無論在美術資產上和場景管理兩技術上都強大許多,但因此也耗費無數倍美術資源需要非常誇張龐大的人力日以繼夜超時工作無數年才能有一款遊戲,並且不僅這兩點有時候還會自研更高效的shader,部分場景上提升幾%乃至數成之多的提升。
有時候shader需要用到的buffer或整個工作流程可能受到限制,比如shader需要用到一些緩衝區或什麼樣的資源需要反覆龐大在script上設置,就可能需要對遊戲引擎做出自定義或擴增修改減免反覆工作同樣的東西,諸如需要自定義的管理系統、介面、彩現管線(渲染管線、渲染引擎)或plug-in(插件、外掛)。
甚至因為沒有辦法修改而自行向遊戲引擎所用到的中間件廠商購買支援自行整合創作出屬於自己的遊戲引擎。
所以從基礎做起,有效管控使用的三角形數量,這將使得即時的遊戲內容獲得很大改善。
後續:
為了能夠體會在相對具體場景上的差距,選擇使用了免費場景來體會差距:
剔除掉了VRchat物件。
場景中約有十萬三角形(具體119,001)。
過程中透過對預製件修改達成替換相同位置的Yu。
原始版本:
改善版本:
兩者的profile差別:
原始↓
改善↓
場景中除了使用烘培光照與陰影外也有即時光照的光源和陰影,所以導致了Primitive大幅上升,又因為本身多邊形本就多造成的影響更為龐大,這就導致了無論多邊形還是像素著色開銷都大幅上升。
而這僅是原本20萬左右三角形*8個在場景中的影響,也是差不多一些遊戲較常見的量,有些想要更精緻可能數量會高達300-400萬,相當於在2k解析度中每個像素都擁有一個三角形的程度,那麼負荷將會相當誇張。
不過在這些實際場景中,300-400萬三角形是在場景上並使用了mesh render及 terrain render等較高效率的render,並且是透過曲面細分與幾何著色器等方式,所以效率會高兩至三倍以上,所以不用太擔心。
不過如果該遊戲擁有大量的Skinned mesh render,例如大量行人角色,那還是相當痛苦地,在線上遊戲諸如MMORPG又或者是大量打擊怪物類型遊戲,又或著3A遊戲中大量NPC,這些勢必會使用到Skin Shader或著Skinned mesh render,在實現上必然在GPU利用率上低於普遍mesh render兩倍之多,在大量情形下甚至差距高達三倍。
模擬鏡子場景:
模擬VRchat中的必需品:鏡子
開啟鏡子後由於相當於擁有第二個camera對場景擷取,所以會使得幾何與像素開銷同時提升,這是無可避免的。
原始場景幀數:
改善場景幀數:
可以發現原本的場景在2K解析度中已經是無法承受低於60fps了,更別提在VR模式下相當於4k以上解析度的時候會更低一些。
以下是兩個場景的profile結果:
原始場景:
改善場景:
可以看得到因為鏡子導致了需要繪製的圖元(Primitive)也就是三角形大幅上升,也同時導致大量的像素運算,所以鏡子是很貴的啊。
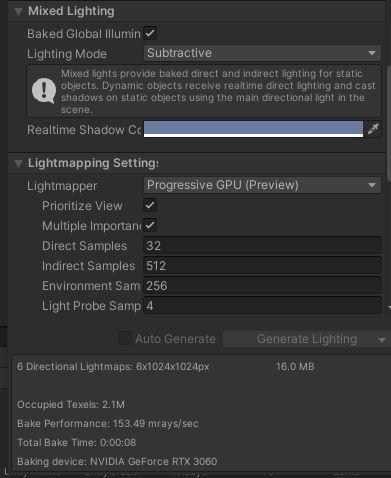
使用陰影subtractive並烘培全場景:
大多數world為了避免使用昂貴的即時陰影和多光源影響,會使用烘培並盡可能調整烘培解析度權衡體積和提高性能。
原始場景幀數:
改善場景幀數:
原始場景profile:
改善場景profile:
做為參考比對只有場景:
幀數:
profile:
模擬關閉Avatar陰影:
一些world為了避免單個avatar耗損資源過多,會選擇考慮將動態陰影關閉,從而獲得更大的提升及更穩定的幀數。
通過手動控制烘培而非自動烘培。
接著在場景的所有光源上關閉陰影,可以的話甚至在Culling Mask設置為Player(VRCSDK後),而不用設為所有(Everything)。如果場景依然需要光照的需求,那麼可以設定為所有。
原始場景幀數:
改善場景幀數:
原始場景profile:
改善場景profile:
提醒:在遊戲中由於自身avatar無法正確剔除動畫以及物理骨骼影響和動畫控制器覆蓋等因素,會導致CPU負荷較大,且會導致Skinned mesh render CPU sync較多,若使用較多資源的avatar會導致自身GPU效率跌落約10%上下,所以若定場景測試且為GPU瓶頸時減少10%左右幀數是正常的。
部分場景即使GPU瓶頸在CPU幀時(frametime)過高時,也會導致使用率無法到達100%,可能會在80~90%之間,這會導致幀數顯得更低落,可以利用更強的GPU在有限的幀時(frametime)預算中提高幀數。
NVidia/AMD實現光柵化原理問題,解析度會影響到三角形光柵化效率(包含頂點處理的前端),若解析度過高則三角形並行度會衰減降下,若解析度過低且三角形過高,nvidia實現原理不明,當解析度(長*寬)值/4的數值被三角形數量超越,則效率會下跌。
多邊形/三角形數量與mesh,因為其存取模式和特性無法與像素著色相等的並行度,這導致更大規模的GPC/SE難以發揮出其相等吞吐性能,單個mesh由於擁有夠多多邊形,所以測試範例中利用率的提升和像素著色器負荷佔比等,最終導致九倍多的多邊形僅影響了約2.4倍的幀數,而在個人VR解析度下差距僅約2.05倍(這裡以DSR放大4206*2366做參考 跟VR差距極小)。
條件允許的情況下在相等的多邊形/三角形數量下,應該使用更少的skin render,而mesh render也一樣,但重要性不大,且因為較容易合批,一樣可以達到很高的利用率,只是數量要高得多,而較少mesh同樣的多邊形更快達到更高利用率。
若條件允許建議單個mesh至少一千個多邊形以上,越多越好,但要記得條件是相同多邊形數量,並且不要忘記可見性,也就是若經常見到在一起的mesh才需要這樣做。
合併網格測試
基於VRchat即將進入Unity2021.3(LTS)版本,但是花費長時間跟蹤Unity3D問題的我發現了一些問題,雖然新版本Unity3D做出了一些他認為的最佳化手段,但是同時也帶來了一些問題。
已經確認是Unity3D自認為的特性而不是被特定原因影響造成的性能低落。
那就是新版本相對舊版本的大量的Skinned mesh renderer會有更多的CPU開銷與GPU開銷,由於計算著色器在於Skinned mesh上的進行蒙皮工作,但是大量零碎的分派導致效率低落,使得利用率低下,在GPU瓶頸的情況下導致了效率顯著下降。
這邊我們使用Zome做為測試。
分別是當前版本的2019與即將使用的2021,而計算著色器造成的問題在2020版本開始就有。
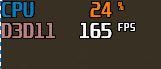
未合併版本2019_幀數456幀
未合併版本2021_幀數416幀
可以看到幀數基本上是倒退的,這種情形在巨量的skinned mesh renderer的情形下更明顯,會導致性能嚴重倒退到幾分之一,不過數量得多達數千上萬。
已合併版本2019_幀數495幀
可以看到提升不算小有個一成左右。
已合併2021_幀數593幀
相比舊版無合併和有合併都提升很多,更別提新版未合併的情形。
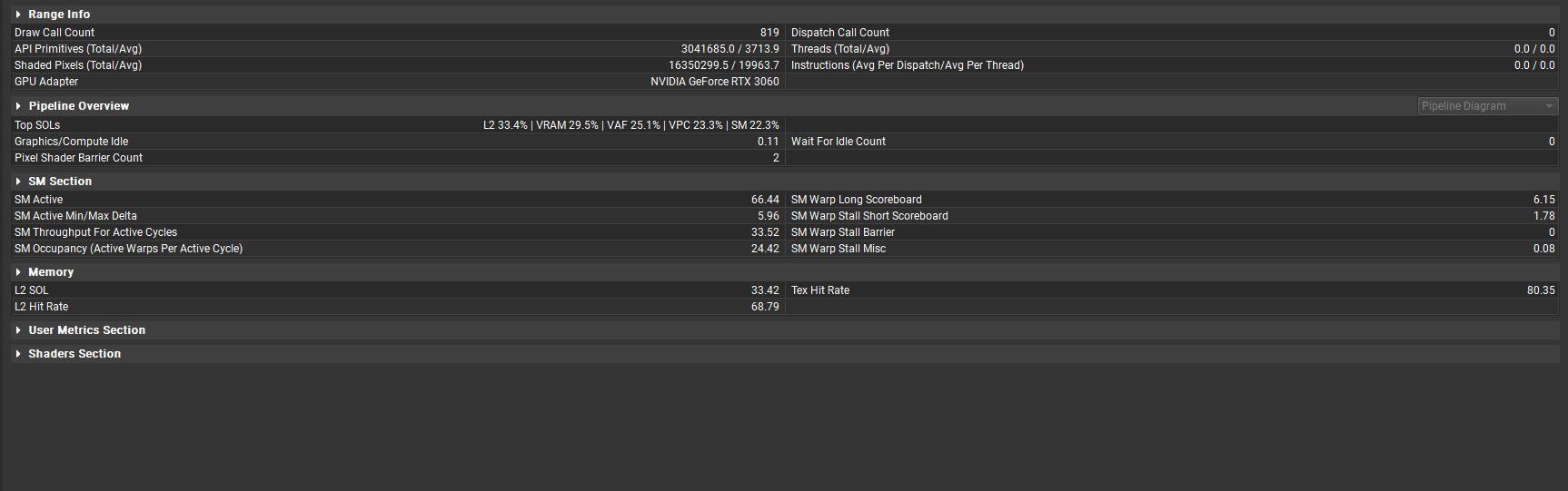
以下是個別的profile結果,可供參考:
未合併2019版本
未合併2021版本
已合併2019版本
已合併2021版本
不過雖然合併在新版本可以獲取更多,在足夠多的avatar下提升顯著(雖未正式上線,可能修改Unity3D上傳執行的結果?),但是目前還未實驗骨骼動畫和物理骨骼產生的問題,可能會帶來更多限制,雖然性能更高。
已經可以預見這種做法會造成物件在動畫控制器上的邏輯比如開關物件、觸發器、碰撞判定等等都會出現更多問題。
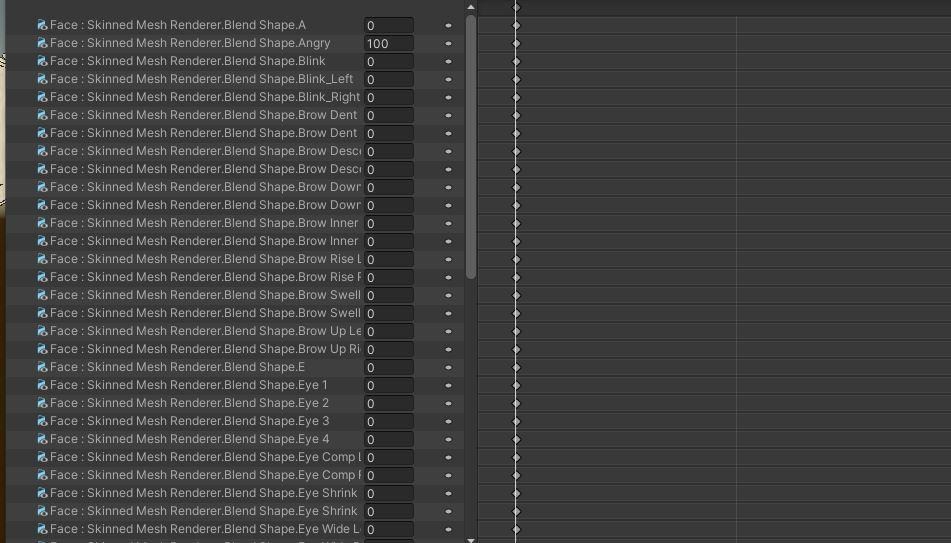
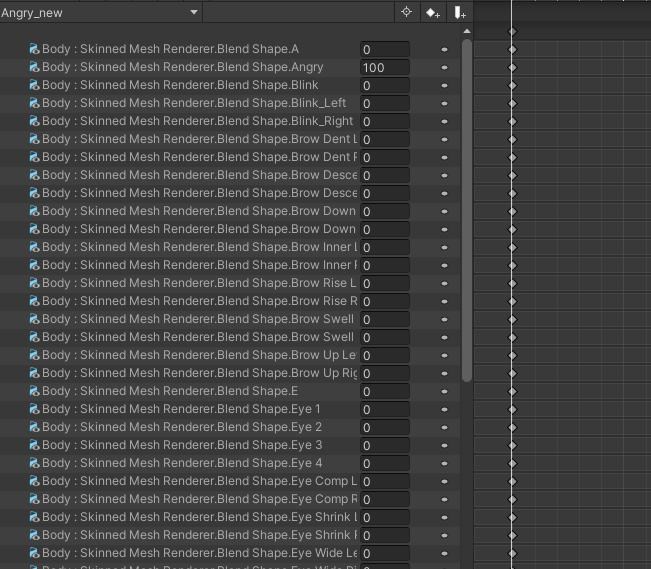
實驗結果:目前測不出問題,物理骨骼、骨骼動畫均正常通過測試,但手勢控制形態鍵出現了問題(正在處理)。
修正方法:由於Unity3D動畫是根據錄製的關係完成,所以被合併的物件需要修改名目,在此需要將相應的object之形態鍵轉換。
例子:
若合併到body內,則錄製的動畫需更改為:
請注意不要多設多餘的形態鍵,確保是原有臉上表情的部分,比如臉上表情部分動作就設定臉上表情動作的形態鍵,不要包含說話用形態鍵,否則會相互干擾,以此類推。
如果你有胸部大小外形更改、外觀體型更改等等形態鍵諸多,多半建議獨立為一個錄製動畫。
骨骼與形態鍵是網格變形的兩種方法,各有優缺,其特點也差異夠多,會比較時多半是在表情方面,但也可能是可以變形的身體如胸部外觀與大小等。
基於骨骼的變形基本上對GPU影響很微小,主要影響是CPU,其對於變形靈活且可控較多但同時也形同複雜度上升,當網格外觀變形或骨骼組織發生變化也能相容,只是不保證外觀變形是否符合想像需求,過多的骨骼會造成相當可觀大於材質、網格本身的CPU開銷。
基於形態鍵的變形是將原始形狀逐一變形至已經設定好的一種形狀,只需線性調整即可,對於CPU幾乎不影響但主要對於GPU影響,當網格因為縮減或增加多邊形時,相關工具修改會無法保留形態鍵而移除,雖然可以嘗試多個形態鍵容易可控變形,但對於GPU效率下跌很明顯。
形態鍵並不只限於表情,也常出現於可以捏臉捏各式變形外觀的設計上,但是大量使用形態鍵會導致整體GPU效率處於一個很低的水準,原因是管線活動狀態會一直持續不斷被打斷,而過量使用骨骼也是影響CPU工作。
當該項形態鍵大於0即進入活動狀態產生消耗,即使處於100完全變成指定形狀也依然付出一樣的代價,越多形態鍵進入活動狀態效率就下降越恐怖。
使用形態鍵本身不增加著色的工作量,但降低效率。
當沒有形態鍵活動時。
有一個形態鍵活動時。
有五十九個形態鍵活動時。
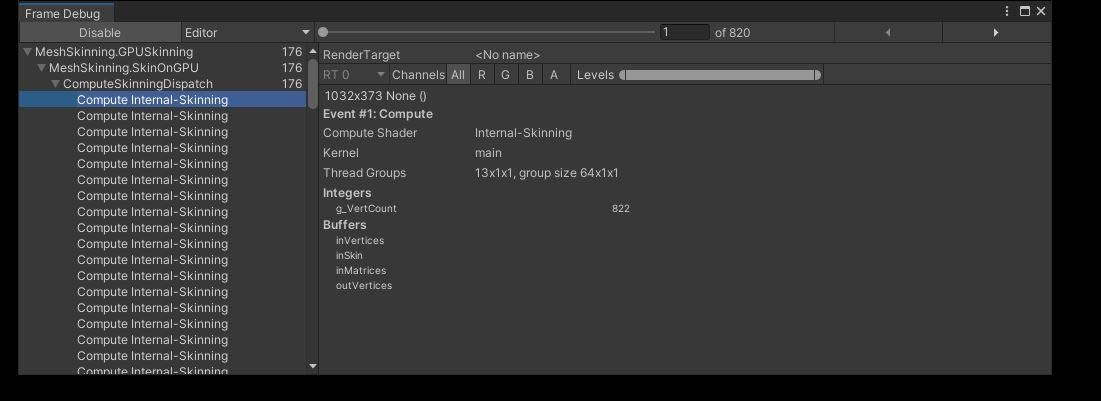
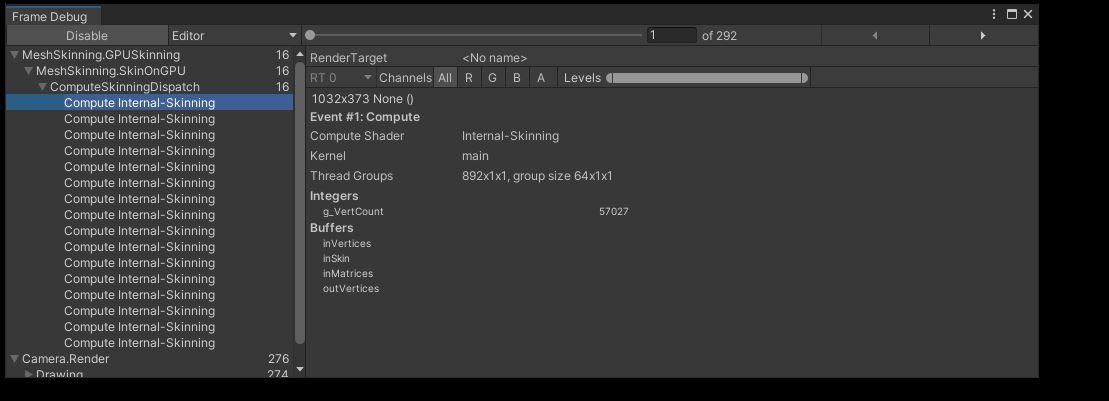
原因:計算著色器依然還是零碎分散地產生大量用於形態鍵的
由於很多計算著色器並不只是降低效率,還增加額外通訊開銷,所以47%時幀數為535時,至42%時幀數470,到19%時幀數下跌至188幀左右。
詳細原因:
大量零碎的thread Group導致低效率
而進行將所有skinned mesh renderer合在一個avatar上時
充分夠大的thread Group能有效利用GPU,再加上透過計算著色器完成一些任務允許跨幀等特性可以做到更好,不至於浪費大量的單元,尤其是容易成為瓶頸的L2頻寬和VRAM頻寬。
解決方法:需要形態鍵變形的部分盡可能拆分,如在臉部則臉部獨立其他合併,若胸部需要變化則胸部也需要獨立,降低的幅度將會降低,但是對於新版本來說由於蒙皮網格多個會導致大量的計算著色器導致效率降低,除非常態性使用形態鍵否則建議合併。(在2021.3版本不適用)
以下是2021.3版本結果
無型態鍵活動時。
有形態鍵活動(59個)。
合併方法
使用blender合併完成後匯出即可
注意:使用blender進行網格合併後,骨骼數量會增加除非使用如cats blender plugin等工具合併bone,骨骼數量增加會增加物理骨骼控制器下因骨骼節點變多而轉置骨骼數量上升造成CPU開銷增多,其本身也會有一定CPU開銷和初始化成本在。
選取你想要合併到哪個網格開始
按shift逐一點選
右鍵選取該項或ctrl+J
























