此篇乃NVIDIA在SIGGRAPH2015所發表Next-Generation Graphics APIs的整理,希望有更多人對寫繪圖程式有興趣。
為什麼我們需要新的圖形API?
這些新的API目標都是提升CPU效能,以下說明如何達成目的:
各家API的相似與相異處
Command Buffers
當CPU thread要交付GPU工作時,並不是一次只送一項指令(command),而是將指令收集起來。傳統上只有一個thread會收集指令,且收集動作是藏在driver內部。等到應用程式下令送出(flush),driver才會將整個command buffer送給GPU。在GPU依順序執行指令的期間,CPU又回到收集指令的作業。
三個新API都提供了command buffer與command queue物件,我們可在每個thread分別使用不同buffer,將指令填充進去。
三者相同處:
三者相異處:
Pipeline State Objects(PSO)
與以往不同,現在大部分的state設定值都儲存在PSO裡面。應用程式無法在繪圖中切換單一個state,必須整組一起切換。這種設計可以讓driver提早編譯和檢查state的錯誤,避免driver在繪圖中切換state時還得停下來檢查。
PSO內包含所有階段的shader、大部分fixed-function的state,還有vertex與render target在記憶體中的格式(format)。vertex buffer與texture不會直接存進PSO內,而是用綁定(binding)的方式,其他沒在PSO內的fixed-function state的處理方式則是各家API稍有不同。
D3D10是直接對command buffer設定這些state,Metal中的一部分state也是如此:
Tiled architectures和Pass的設計只出現在Metal與Vulkan,詳細看這裡。
Memory and Resources
此小節只與DX12與Vulkan有關。
以下是專有名詞解釋:
兩者用語比較:
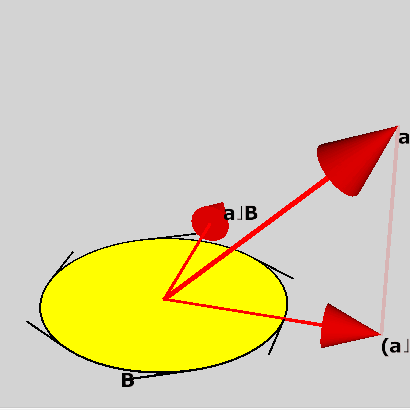
下圖是新API的resource binding模型。

每個綁定點稱作descriptor,descriptor會儲存指向資源的指標和其它相關資訊,例如texture的長寬和格式等。不同GPU可能會需要不同的資訊,所以descriptor設計成對應用程式不透明。
Descriptor table是一個API物件,相當於一塊用來儲存descriptor的buffer。在D3D中,指向一組descriptor table的物件被稱為root table。
Pipeline layout(或root layout)也是個API物件,它用來規定每一個descriptor應該指向什麼資源。不同的PSO可使用相同的pipeline layout,如此一來繪圖時便可使用同一組table。
D3D12與Vulkan皆提供pool(heap)用於配置descriptor table,以下是兩者用語比較:
Data Hazards and Object Lifetimes
舊API driver會在背後自動處理資料存取的問題,例如:
新API全都得自己來:
總結
新的API做了一些妥協,我們得到更多的控制權和可預測性,但我們也承擔了一部分driver的責任,更像是在遊戲主機上寫程式。SIGGRAPH 2015還有一些演講者分享使用新API的心得,還有使新API容易使用的策略,各位有興趣可以接著到這裡。
為什麼我們需要新的圖形API?
這些新的API目標都是提升CPU效能,以下說明如何達成目的:
減少CPU負擔,減低CPU成為瓶頸的機會
傳統只有一個thread會用來交付GPU工作,一旦遇到複雜情境,CPU就會成為瓶頸。一般作法是使用render thread來專門和GPU打交道,減輕main thread的負擔。即使driver內部改用多個thread同時處理,改善幅度仍舊有限。新API解決問題的方式很直接,即所有thread都可以交付GPU工作。
Driver的效能更穩定、更容易預測
以往呼叫某個API時,driver可能會開始編譯shader、或是插入fence、清除快取、配置記憶體等。這意味著每次呼叫同一個API,所花費的時間可能都不一樣,也因此每個frame的時間很難一致,此問題因下述功能得以解決。
提供明確、更接近遊戲主機的控制能力,
應用程式現在得自行負責CPU與GPU之間所共享的資源的同步問題、防止資源同時被讀寫,還有記憶體管理。各家API的相似與相異處
Command Buffers
當CPU thread要交付GPU工作時,並不是一次只送一項指令(command),而是將指令收集起來。傳統上只有一個thread會收集指令,且收集動作是藏在driver內部。等到應用程式下令送出(flush),driver才會將整個command buffer送給GPU。在GPU依順序執行指令的期間,CPU又回到收集指令的作業。
三個新API都提供了command buffer與command queue物件,我們可在每個thread分別使用不同buffer,將指令填充進去。
| D3D12 | Metal | Vulkan |
| ID3D12CommandList | MTLCommandBuffer | VkCmdBuffer |
| ID3D12CommandQueue | MTLCommandQueue | VkCmdQueue |
三者相同處:
- 任何thread都可儲存與交付指令
- Command buffer內部不透明,無法像遊戲主機一樣製作pre-built buffer
- State不會繼承,不同Buffer的State設定不會互相影響
三者相異處:
- Metal的command buffer被提交後就無法再使用
- Vulkan與D3D12中允許重複使用
- 可在不同frame提交同一個command buffer
- command buffer內可包含另一個commander buffer
Pipeline State Objects(PSO)
與以往不同,現在大部分的state設定值都儲存在PSO裡面。應用程式無法在繪圖中切換單一個state,必須整組一起切換。這種設計可以讓driver提早編譯和檢查state的錯誤,避免driver在繪圖中切換state時還得停下來檢查。
PSO內包含所有階段的shader、大部分fixed-function的state,還有vertex與render target在記憶體中的格式(format)。vertex buffer與texture不會直接存進PSO內,而是用綁定(binding)的方式,其他沒在PSO內的fixed-function state的處理方式則是各家API稍有不同。
D3D10是直接對command buffer設定這些state,Metal中的一部分state也是如此:
d3dCommandBuffer->OMSetStencilRef(0xFFFFFFFF);Vulkan的所有state與Metal一部分的state使用小型的state物件來儲存:
mtlCommandBuffer.setTriangleFillMode(.Lines);
mtlCommandBuffer.setDepthStencilState(mtlDepthStencilState);
vkCreateDynamicViewportState(device, &vpInfo, &vpState);
Tiled architectures和Pass的設計只出現在Metal與Vulkan,詳細看這裡。
Memory and Resources
此小節只與DX12與Vulkan有關。
以下是專有名詞解釋:
- Allocation, 代表一塊實體或虛擬的address space
- 配置記憶體時可選擇cache行為、CPU與GPU是否可存取
- Resource, 特定(記憶體)布局的記憶體
- 可以是一個線性buffer,或是2D/3D/multisample texture
- View,特定"格式/用途"的resource
- color render target或depth stencil target
兩者用語比較:
| D3D12 | Vulkan | |
| Allocation | ID3D12Heap | VkDeviceMemory |
| Resource | ID3D12Resource | VkImage VkBuffer |
| View | ID3D12DepthStencilView ID3D12RenderTargetView ... |
VkImageView VkBufferView |
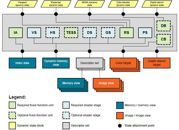
下圖是新API的resource binding模型。
每個綁定點稱作descriptor,descriptor會儲存指向資源的指標和其它相關資訊,例如texture的長寬和格式等。不同GPU可能會需要不同的資訊,所以descriptor設計成對應用程式不透明。
Descriptor table是一個API物件,相當於一塊用來儲存descriptor的buffer。在D3D中,指向一組descriptor table的物件被稱為root table。
Pipeline layout(或root layout)也是個API物件,它用來規定每一個descriptor應該指向什麼資源。不同的PSO可使用相同的pipeline layout,如此一來繪圖時便可使用同一組table。
D3D12與Vulkan皆提供pool(heap)用於配置descriptor table,以下是兩者用語比較:
| D3D12 | Vulkan |
| ID3D12DescriptorHeap | VkDescriptorPool |
| - | VkDescriptorSet |
| D3D12_ROOT_DESCRIPTOR_TABLE | VkDescriptorSetLayout |
| ID3D12RootLayout | VkPipelineLayout |
Data Hazards and Object Lifetimes
舊API driver會在背後自動處理資料存取的問題,例如:
- 對一塊正在被GPU使用中的buffer做記憶體映射(map),driver會等待該buffer使用完,或是乾脆配置一塊新的buffer,然後找時機取代掉舊的。
- 繪圖到一張image上,然後馬上將它當作texture。driver會防止資料寫入前就作讀取動作,並處理cache一致性問題。
- 配置比GPU記憶體還大的texture,drvier會幫忙將資料page in/out來製造空間。
新API全都得自己來:
- 明確同步CPU/GPU
- 沒有map discard或類似的功能了,此功能會使效能無法被預測
- 不要寫入GPU正在讀取的資料
- 用ID3D12Fence/VkEvent來同步
- 明確管理物件生命週期
- 不要刪除GPU正在用的物件
- 明確管理資源常駐(D3D12)
- 明確指示資源的transition(見這裡state transition小節的說明)
- 每個資源都處於某個狀態(state),例如"我現在是texture",或"我現在是color target"
- driver不會自動變更資源的狀態,須明確下指令來切換
- driver會在狀態切換時自動插入barrier、清空cache、壓縮或解壓縮資料
- 使用錯誤狀態的資源會得到未定義的結果
總結
新的API做了一些妥協,我們得到更多的控制權和可預測性,但我們也承擔了一部分driver的責任,更像是在遊戲主機上寫程式。SIGGRAPH 2015還有一些演講者分享使用新API的心得,還有使新API容易使用的策略,各位有興趣可以接著到這裡。