這個差別在 C 和 C++ 中也能看到,char const *str = "Hello"; 的 str 指向的字串位於 ROM,如果嘗試修改會是未定義行為,與 &str 相應,都只是沒有所有權的引用
本篇文章有不少程式碼,如果這裡的排版讓你感到閱讀困難,請服用 HackMD 好讀版。
► String 與 &str
能分清何謂可變、何謂不可變之後,要想理解 Rust 最常見的兩種字串型態就不那麼困難了。
在一般用例中,Rust 的字串分成兩種型態:String 和 &str。
String 比較接近我們近代程式語言常見的字串,是一個經過高度封裝的完整結構,可以動態增減、拼接字串的內容:
你可以從上面的範例注意到,my_string 在初始化的時候使用的是 String::from("Hello!") 而非 "Hello!",這兩個東西是不一樣的──前者是完整的 String,而後者正是剛才提及的 &str。當我們直接使用雙引號 "Hello!" 來表示字串時,它就是指向一筆靜態字串資料的參考(因此是 &str),而 String::from 這個函數則負責把 &str 指向的資料複製出來,包裝成一份完整的 String 字串。
由於字串拼接實際上做的是擴充原有的 String 所佔用的記憶體大小,然後把新增的字串資料填進去,因此 Rust 內建的字串拼接是設計成 String + &str 的形式,而不是 String + String。如果想要拼接兩個既有的 String,我們就需要用 .as_str() 方法取得它的參考 &str:
除此之外,String 切片的參考、&str 切片的參考也都能傳入接受 &str 的函數:
也就是說,本質上 &str 就只是指向一個資料地址、長度,且只能讀不能寫;String 則是自己擁有一份完整的資料,可以讀也可以寫,如此而已。
只要曉得如何在 String 和 &str 之間轉換,基本上就有能力處理大部分的情況。
能分清何謂可變、何謂不可變之後,要想理解 Rust 最常見的兩種字串型態就不那麼困難了。
在一般用例中,Rust 的字串分成兩種型態:String 和 &str。
String 比較接近我們近代程式語言常見的字串,是一個經過高度封裝的完整結構,可以動態增減、拼接字串的內容:
| let mut my_string = String::from("Hello!"); // 如果嫌麻煩可以用 "Hello!".to_string() my_string += " My name is Johnny."; // 等價於 my_string.push_str(" My name is Johnny."); my_string += " Yoroshikuuuuuuuu-"; println!("{my_string}"); my_string = my_string.replace("Johnny", "Pig Knuckle"); println!("{my_string}"); |
你可以從上面的範例注意到,my_string 在初始化的時候使用的是 String::from("Hello!") 而非 "Hello!",這兩個東西是不一樣的──前者是完整的 String,而後者正是剛才提及的 &str。當我們直接使用雙引號 "Hello!" 來表示字串時,它就是指向一筆靜態字串資料的參考(因此是 &str),而 String::from 這個函數則負責把 &str 指向的資料複製出來,包裝成一份完整的 String 字串。
由於字串拼接實際上做的是擴充原有的 String 所佔用的記憶體大小,然後把新增的字串資料填進去,因此 Rust 內建的字串拼接是設計成 String + &str 的形式,而不是 String + String。如果想要拼接兩個既有的 String,我們就需要用 .as_str() 方法取得它的參考 &str:
| let mut my_string = String::from("Hello!"); let new_string_to_add = String::from(" Konnichiwa!"); my_string.push_str(new_string_to_add.as_str()); println!("{my_string}"); |
除此之外,String 切片的參考、&str 切片的參考也都能傳入接受 &str 的函數:
| fn main() { let my_string = String::from("Hello!"); print_str(&my_string[1..=4]); let my_static_str = "Hello!"; print_str(&my_static_str[1..=4]); } fn print_str(content: &str) { println!("{content}"); } |
也就是說,本質上 &str 就只是指向一個資料地址、長度,且只能讀不能寫;String 則是自己擁有一份完整的資料,可以讀也可以寫,如此而已。
只要曉得如何在 String 和 &str 之間轉換,基本上就有能力處理大部分的情況。
► 字串背後的記憶體行為
然而,若想真正瞭解兩者的性質和差異、精準掌握什麼時候該用 String、什麼時候該用 &str,就得涉及記憶體管理的範疇。
首先,程式儲存資料的位置可以粗分為 stack、heap、ROM 三種區域:
String 實際上就是一個裝滿 u8 元素的 Vec。
我們現在試著宣告一個 String 字串:
當我們宣告一個 String 的時候,String 底下的 Vec 會包含三樣東西:
這三樣東西都會被存放在高效的 stack,並且在產生 String 物件時,系統會在 heap 上分配一個長度為 13 的記憶體,把字串的實際資料放進去:
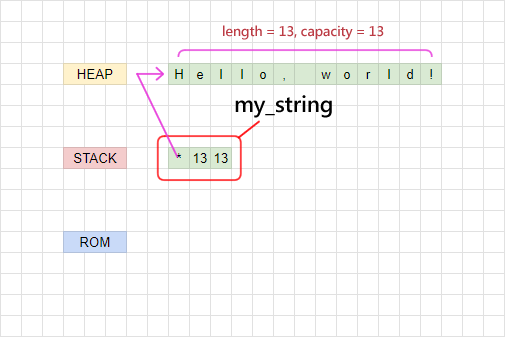
這裡的 cap 意義在於,它能夠讓程式的底層機制知道這份資料佔用空間的合法範圍。假如我們打算修改資料使之變長(例如我們拼接一段字串上去,讓它的長度從 13 變成 20),那麼系統就需要分配長度至少為 20 的空間給它用,這時候 len 就會變成 20,而 cap 也會變成至少 20。因為分配記憶體空間需要一定的運作開銷,有些情況下系統可能會刻意預先分配一些額外的記憶體空間(例如只需要 20,但系統分配 32),避免下次被寫入的時候又要大費周章分配記憶體空間,這種時候可能就會有 len 為 20、cap 為 32 的情況。
反之,如果我們把字串的資料抹除,覆蓋新的資料上去,但是新的資料較短:
這時候系統就不會重新分配記憶體,而是把 len 的值改為 2:
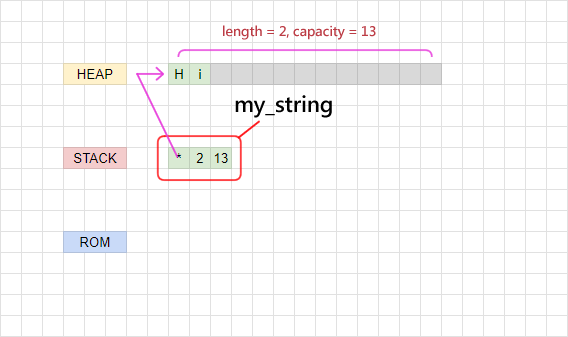
如此一來,系統就會知道這份資料只有前兩格是有意義的,讀取時只需要拿到前兩格的資料就可以停下來了。
若我們想宣告一個可能會被頻繁修改的字串,而且我們確定範圍都在一定值以內,就可以使用 with_capacity 方法:
在一些用程式讀寫檔案的例子當中,時常會專門宣告一個固定長度的 buffer,把讀到的資料分批寫入 buffer 以後再取出,正是因為這樣可以避免一直重新分配記憶體而拖累速度。
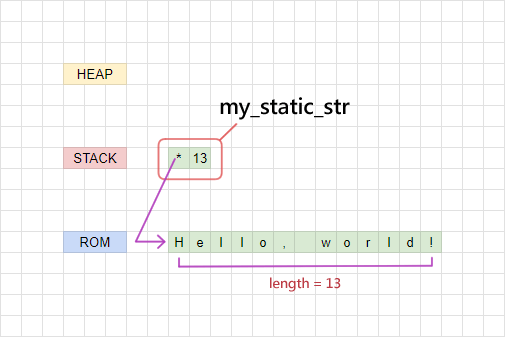
接下來換個情境吧。當我們把一個字串寫死在程式裡:
字串的實際資料會被放在程式的 ROM 區域:
若我們先產生一個 String,再獲得它的參考:
這時候 my_str 就是一個指向 heap 上的數據的變數了:
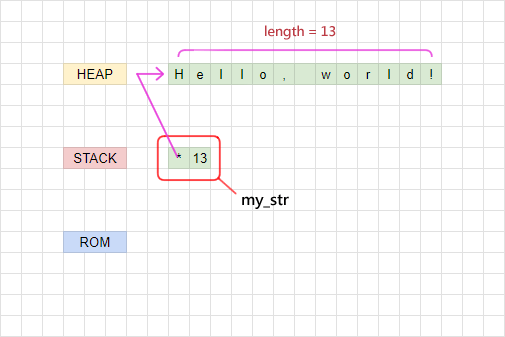
&str 參考的對象可以是一個 String,也可以是一個被寫死在 ROM 上面的字串。
以上就是 String 和 &str 的差別。
其實上面例子中 my_static_str 的型態,我們可以說它是一個「&'static str」,加上了 'static 標籤表示這個字串是從程式執行以來就一直存在,直到程式關閉:
不過這個標籤從 2017 年的 Rust 1.17 版本開始就不是必要的東西了,因為就算你省略了 'static 標籤,編譯器也可以自動推斷出這個字串是 'static 的,畢竟它本來就是個寫死的字串,而不是從其他地方讀取而來。假如你從某些文獻看到 &'static str 這種形式也不用感到驚慌,只要知道它是寫在 ROM 上面的字串就行,本質上還是個 &str。
► 為什麼字串要設計得這麼囉嗦?全都封裝成 String 不好嗎?
在許多程式語言對字串的實作當中,字串底層的資料多半是不可變的。表面上這些字串看起來都可以自由增減、取代,但實際上只要字串被修改了,系統就會在背後重新分配記憶體、重建一個新的字串去取代掉原來的位置,這並不是真正意義上的「字串修改」,它只是語言本身對於這個過程高度抽象化的結果。
若把全部的字串都封裝得讓開發者難以微調,這可能就不是 Rust 想要的方向。作為一個系統級的語言,Rust 必須提供選項讓使用者有辦法親自掌握這些細微的差異,既能選擇使用抽象的高級功能,也能按照需求使用開銷較小的做法,也就有了 String 和 &str 的分別。
除此之外,也有一個理由是基於「所有權」的設計。對於 String 變數和 &str 變數,兩者相差最大的地方就是「一個是真正被擁有的資料,一個是從其他地方借來的」,它們的有效範圍和權限在實務上有很大的不同。因為篇幅太長,打算之後再把所有權單獨拿出來說說,畢竟 Rust 也正是透過嚴格的所有權系統來阻止潛在的安全問題,這不是兩三句就能夠說得完的。
我沒提到的是,其實真要細分起來的話,Rust 的字串至少還有十種:可以存放非 UTF-8 內容的、可以共享所有權的、可以跨執行緒讀取的、固定長度的、被寫入時才複製的、作業系統專用的、檔案路徑專用的……其中有很多都要具備更多關於 Rust 的背景知識才能理解,在這之前還是先聚焦在這些背景知識吧。
然而,若想真正瞭解兩者的性質和差異、精準掌握什麼時候該用 String、什麼時候該用 &str,就得涉及記憶體管理的範疇。
首先,程式儲存資料的位置可以粗分為 stack、heap、ROM 三種區域:
- stack:存取速度快但空間小,通常我們在程式裡直接宣告的變數都會被放在 stack 上面
- heap:存取速度慢一些但能用的空間大,通常在遇到大小不確定或是較大的資料時會存到 heap 上面,比如可變長度的陣列(Vec)
- ROM:read-only memory,用來存放編譯階段早就已經確定並寫死在程式裡的靜態資料
String 實際上就是一個裝滿 u8 元素的 Vec。
我們現在試著宣告一個 String 字串:
| let my_string = String::from("Hello, world!"); |
當我們宣告一個 String 的時候,String 底下的 Vec 會包含三樣東西:
- ptr(pointer):實際資料內容的記憶體位址
- len(length):有效的資料長度
- cap(capacity):實際被分配的記憶體大小
這三樣東西都會被存放在高效的 stack,並且在產生 String 物件時,系統會在 heap 上分配一個長度為 13 的記憶體,把字串的實際資料放進去:
這裡的 cap 意義在於,它能夠讓程式的底層機制知道這份資料佔用空間的合法範圍。假如我們打算修改資料使之變長(例如我們拼接一段字串上去,讓它的長度從 13 變成 20),那麼系統就需要分配長度至少為 20 的空間給它用,這時候 len 就會變成 20,而 cap 也會變成至少 20。因為分配記憶體空間需要一定的運作開銷,有些情況下系統可能會刻意預先分配一些額外的記憶體空間(例如只需要 20,但系統分配 32),避免下次被寫入的時候又要大費周章分配記憶體空間,這種時候可能就會有 len 為 20、cap 為 32 的情況。
反之,如果我們把字串的資料抹除,覆蓋新的資料上去,但是新的資料較短:
| let mut my_string = String::from("Hello, world!"); my_string.replace_range(.., "Hi"); println!("{my_string}"); // -> Hi |
這時候系統就不會重新分配記憶體,而是把 len 的值改為 2:
如此一來,系統就會知道這份資料只有前兩格是有意義的,讀取時只需要拿到前兩格的資料就可以停下來了。
若我們想宣告一個可能會被頻繁修改的字串,而且我們確定範圍都在一定值以內,就可以使用 with_capacity 方法:
| let mut my_string = String::with_capacity(1024); |
在一些用程式讀寫檔案的例子當中,時常會專門宣告一個固定長度的 buffer,把讀到的資料分批寫入 buffer 以後再取出,正是因為這樣可以避免一直重新分配記憶體而拖累速度。
接下來換個情境吧。當我們把一個字串寫死在程式裡:
| let my_static_str = "Hello, world!"; |
字串的實際資料會被放在程式的 ROM 區域:
若我們先產生一個 String,再獲得它的參考:
| let my_string = String::from("Hello, world!"); let my_str = my_string.as_ref(); |
這時候 my_str 就是一個指向 heap 上的數據的變數了:
&str 參考的對象可以是一個 String,也可以是一個被寫死在 ROM 上面的字串。
以上就是 String 和 &str 的差別。
其實上面例子中 my_static_str 的型態,我們可以說它是一個「&'static str」,加上了 'static 標籤表示這個字串是從程式執行以來就一直存在,直到程式關閉:
| let my_static_str: &'static str = "Hello, world!"; |
不過這個標籤從 2017 年的 Rust 1.17 版本開始就不是必要的東西了,因為就算你省略了 'static 標籤,編譯器也可以自動推斷出這個字串是 'static 的,畢竟它本來就是個寫死的字串,而不是從其他地方讀取而來。假如你從某些文獻看到 &'static str 這種形式也不用感到驚慌,只要知道它是寫在 ROM 上面的字串就行,本質上還是個 &str。
► 為什麼字串要設計得這麼囉嗦?全都封裝成 String 不好嗎?
在許多程式語言對字串的實作當中,字串底層的資料多半是不可變的。表面上這些字串看起來都可以自由增減、取代,但實際上只要字串被修改了,系統就會在背後重新分配記憶體、重建一個新的字串去取代掉原來的位置,這並不是真正意義上的「字串修改」,它只是語言本身對於這個過程高度抽象化的結果。
若把全部的字串都封裝得讓開發者難以微調,這可能就不是 Rust 想要的方向。作為一個系統級的語言,Rust 必須提供選項讓使用者有辦法親自掌握這些細微的差異,既能選擇使用抽象的高級功能,也能按照需求使用開銷較小的做法,也就有了 String 和 &str 的分別。
除此之外,也有一個理由是基於「所有權」的設計。對於 String 變數和 &str 變數,兩者相差最大的地方就是「一個是真正被擁有的資料,一個是從其他地方借來的」,它們的有效範圍和權限在實務上有很大的不同。因為篇幅太長,打算之後再把所有權單獨拿出來說說,畢竟 Rust 也正是透過嚴格的所有權系統來阻止潛在的安全問題,這不是兩三句就能夠說得完的。
我沒提到的是,其實真要細分起來的話,Rust 的字串至少還有十種:可以存放非 UTF-8 內容的、可以共享所有權的、可以跨執行緒讀取的、固定長度的、被寫入時才複製的、作業系統專用的、檔案路徑專用的……其中有很多都要具備更多關於 Rust 的背景知識才能理解,在這之前還是先聚焦在這些背景知識吧。
HackMD 好讀版:https://hackmd.io/@upk1997/rust-strings
縮圖素材原作者:Karen Rustad Tölva(CC0 1.0)