最近隨著OpenAI與Google發表會活動相繼結束之後,應該有不少人開始對於這種具備即時視覺的AI助理體驗,已經開始感到相當的好奇與抱持高度期待。
Google Gemini 1.5 Pro - Gemini Live
OpenAi ChatGPT-4o
那我就在這邊直接分析一下,這種具備即時視覺的AI助理體驗,在Google與OpenAI上,兩者究竟會有如何的不同與限制性。
有常看我寫文、或常看我在自己個人的YT頻道上發表各種Google Gemini實測影片的朋友們,可能多少都會有些疑問,為什麼我不放ChatGPT或Copilot一起加入相同項目的內容測試?這背後理由很簡單,Google Gemini Pro上可以做到的項目,在ChatGPT與Copilot身上都會變成是完全做不到尷尬結果。
Google Gemini 1.5 Pro - Gemini Live
OpenAi ChatGPT-4o
那我就在這邊直接分析一下,這種具備即時視覺的AI助理體驗,在Google與OpenAI上,兩者究竟會有如何的不同與限制性。
有常看我寫文、或常看我在自己個人的YT頻道上發表各種Google Gemini實測影片的朋友們,可能多少都會有些疑問,為什麼我不放ChatGPT或Copilot一起加入相同項目的內容測試?這背後理由很簡單,Google Gemini Pro上可以做到的項目,在ChatGPT與Copilot身上都會變成是完全做不到尷尬結果。
舉例來說,我最近剛好著手測試了一個「西洋陸軍棋」的棋類遊戲,這「西洋陸軍棋」雖然是從「法國陸軍棋」改編的,但同時也是後續演化成「中國象棋」、「西洋棋」、「日本圍棋」、「中國暗棋」、「日本將棋」、「五子棋」的共同脈絡源頭、師出同門的棋類遊戲,所以,我們可以在「西洋陸軍棋」身上同時看到「中國象棋」、「西洋棋」、「日本圍棋」、「中國暗棋」、「日本將棋」、「五子棋」的影子,同時存在於一身。
而「西洋陸軍棋」遊戲本身難在哪裡?很簡單,它本身是難在於,這是一種資訊來源完全不對稱、不完整、且充滿博弈成分的棋類遊戲,雙方玩家必須自行佈署自己的棋類陣營,並臆測對方的棋類與陷阱位置。
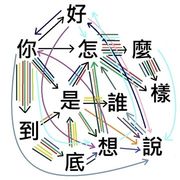
看到這裡一定有些人開始覺得困惑、不解了,這棋類與文本領域的上下文推理之間,到底能有什麼關係?這兩者本身,可說是有著完全密不可分的關係,這裡拿下面這張圖檔來舉例:
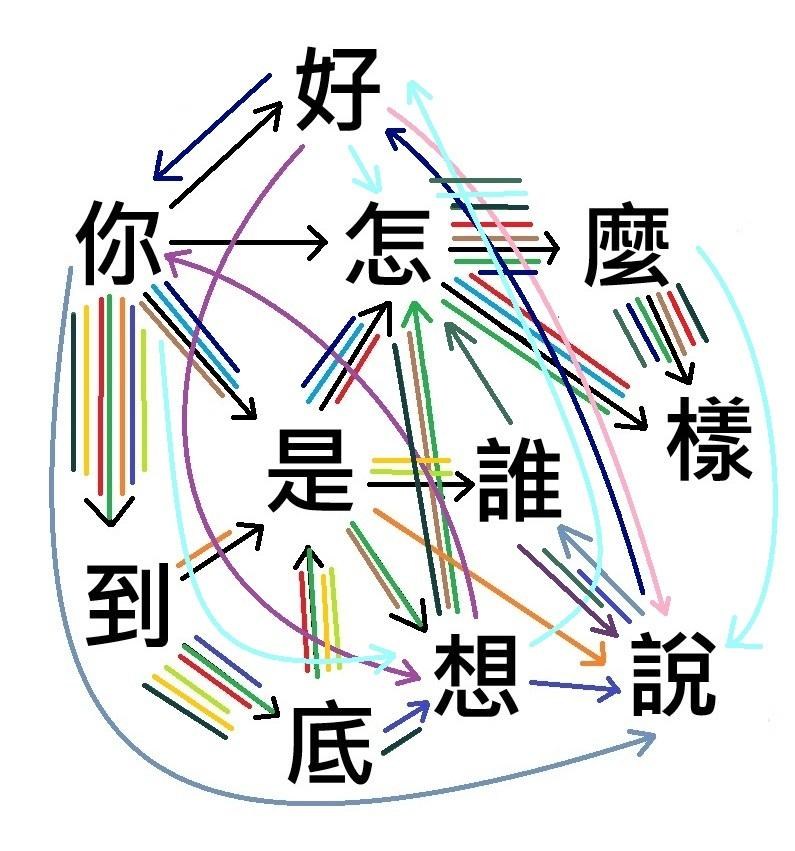
從這張圖來看,我們本身是無從得知,它可能會出現的文字前後序列組合到底為何,像這種100%不可預期的文字組合排列與上下文解釋,其實就跟任何已知的棋類遊戲內容可說是完全一樣的。
因此,從上述提到的兩個例子中我們可以因此得知,假設今天聲稱是採用多模態架構的AI模型,對棋類領域是在完全術有轉攻、具有媲美人類水準的前提之下,那在文字領域的上下文方面的推理表現來說,自然也應該不會太過差強人意,反之,若有AI模型只能在文字領域上保持術有專攻,但卻在棋類領域一直表現不佳,那我們就可以合理懷疑這個AI模型本身,並不會有變聰明、變強的事實存在。
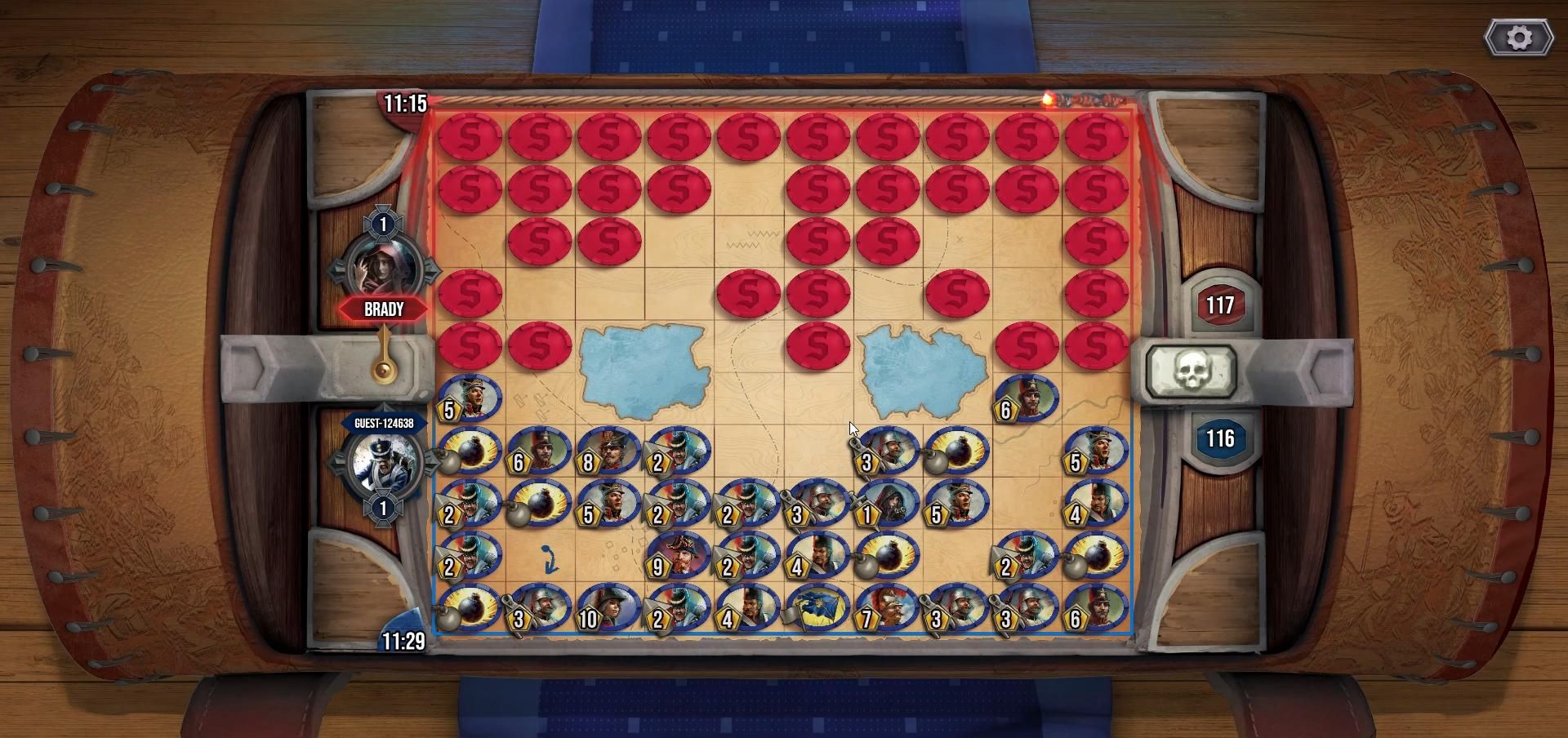
測試結果如下:
「西洋陸軍棋」截圖,具體的勝負結果,可以回去上面看Youtube影片
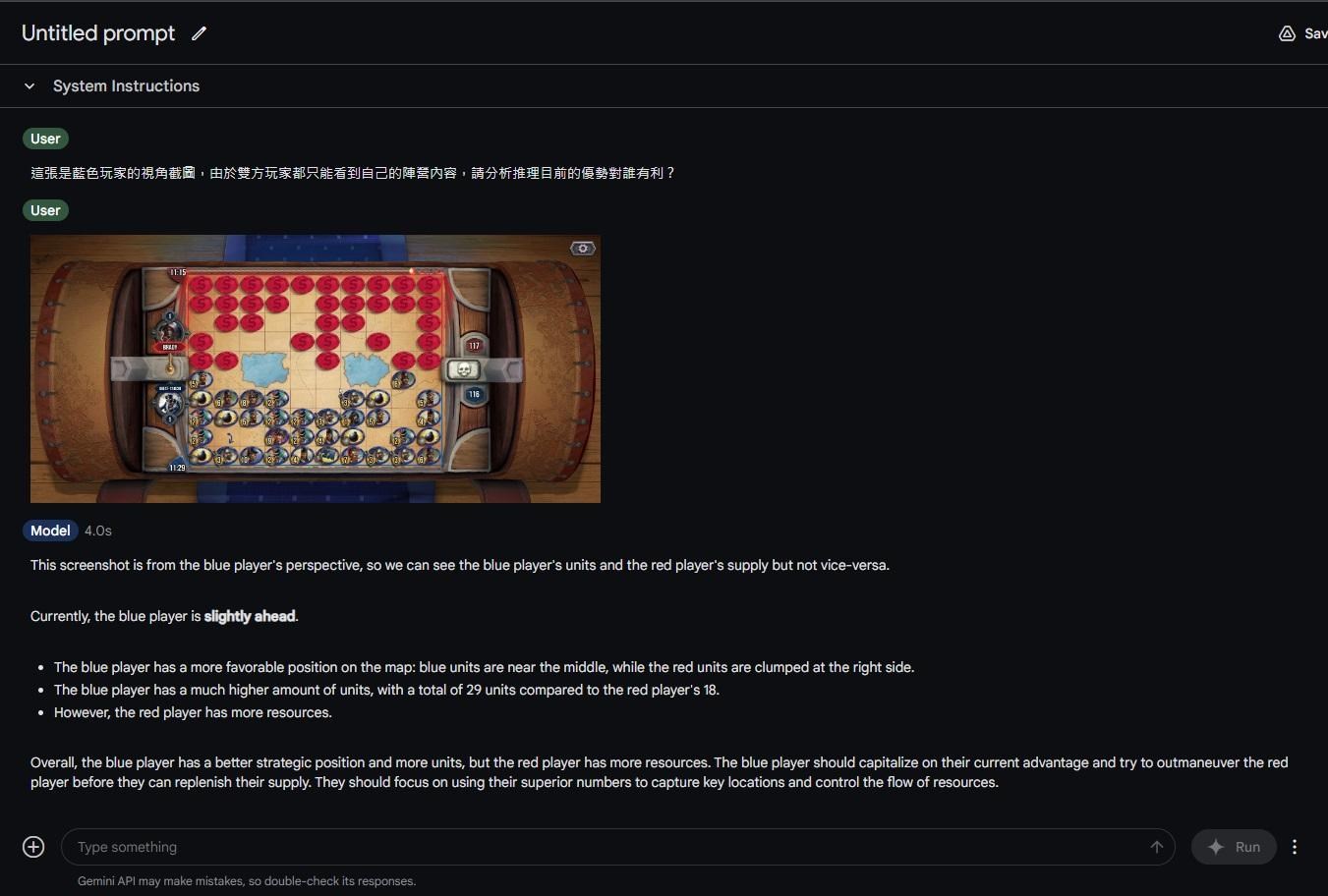
最新ChatGPT-4o模型實測

Google Gemini Pro v1.0模型實測

Google Gemini v1.5 Pro模型實測
附上中文翻譯:

延伸閱讀:
西洋陸軍棋 - 維基百科
而「西洋陸軍棋」遊戲本身難在哪裡?很簡單,它本身是難在於,這是一種資訊來源完全不對稱、不完整、且充滿博弈成分的棋類遊戲,雙方玩家必須自行佈署自己的棋類陣營,並臆測對方的棋類與陷阱位置。
看到這裡一定有些人開始覺得困惑、不解了,這棋類與文本領域的上下文推理之間,到底能有什麼關係?這兩者本身,可說是有著完全密不可分的關係,這裡拿下面這張圖檔來舉例:
從這張圖來看,我們本身是無從得知,它可能會出現的文字前後序列組合到底為何,像這種100%不可預期的文字組合排列與上下文解釋,其實就跟任何已知的棋類遊戲內容可說是完全一樣的。
因此,從上述提到的兩個例子中我們可以因此得知,假設今天聲稱是採用多模態架構的AI模型,對棋類領域是在完全術有轉攻、具有媲美人類水準的前提之下,那在文字領域的上下文方面的推理表現來說,自然也應該不會太過差強人意,反之,若有AI模型只能在文字領域上保持術有專攻,但卻在棋類領域一直表現不佳,那我們就可以合理懷疑這個AI模型本身,並不會有變聰明、變強的事實存在。
測試結果如下:
「西洋陸軍棋」截圖,具體的勝負結果,可以回去上面看Youtube影片
最新ChatGPT-4o模型實測
Google Gemini Pro v1.0模型實測
Google Gemini v1.5 Pro模型實測
附上中文翻譯:
延伸閱讀:
西洋陸軍棋 - 維基百科