【雜談】虛擬歌手雜談(零):仿生人會夢見虛擬歌手嗎?
*這篇只是簡介
## 摘要
這篇我會講述
-虛擬歌手的定義
-虛擬歌手的運作方式(輸入、輸出、目標、架構)
-怎麼樣算是個好的虛擬歌手(為什麼「真實」的虛擬歌手不一定是「好」的虛擬歌手)
-其他一堆雜七雜八的事情
## 前言
當1940年代,最早的數位電腦被製作出來的時候,電腦還只是電腦,只是一部用來做數學計算的機器。它不會顯示圖片,不會畫圖,不會處理音樂,更不會唱歌。它只是一部沉悶的,帶著一絲近未來科幻感的龐然大物。
然而,世界飛速前進。不久,電腦學會了處理影像,處理音訊,甚至處理由連續的影像形成的影片,一切在五、六十年間發生。在宇宙,在人類文明的時間軸上,那不過是短短的一瞬間。
有天,或許是二十世紀末的某一天,某個人忽然突發奇想。
仿生人會夢見自己成為歌手嗎?
## 什麼是虛擬歌手
這篇文章是虛擬歌手雜談的「第零篇」。按順序,這該是我第三篇雜談;按道理,這篇雜談的內容,不是主講SynthV [1] 就該是講Vocaloid [2]。但我終於想通了(感謝伊亞修斯 [3] 就這一點給的建議。事實上就是他點醒我的)。我之前所寫的雜談,一直避談一些比較本質性的內容。這些本質性的內容,我最初是擔心一旦寫出來,實在有點多餘,沒有意思。但問題是,這麼做實在太過跳躍了,沒有章法可言。再說,這些本質性的事物,其實一點也不平凡。
譬如,關於一切的根源的這個問題吧──
「什麼是虛擬歌手?」
在談論一切虛擬歌手的事物之前,定義本身便是模糊不清了。譬如說吧,早期(至少在2017年以前)「日V」這個名詞的意思,毫無疑問就是「日文Vocaloid」,而「中V」則是「中文Vocaloid」。但名詞的意義是會轉變的,現在的「日V」變成是指「日本的Vtuber」了。
至於「虛擬」一詞的意義,也因為許多人的使用、沿用,而有了改變,產生了歧異性。關於「Vocaloid」、「Vsinger」、「Vtuber」之間的差異,更不是在這世上隨便抓一個喜歡ACG的人來問,都能輕易答出來的題目了。
所以,我想我必須先給「虛擬歌手」一詞做個定義才行。考慮到「虛擬歌手」這個詞,在教育部重編國語辭典修訂本 [4] 上並沒有被收錄,甚至中文維基百科 [5] 也不存在獨立的條目,那麼,姑且我就先為「虛擬歌手」這個詞下個非官方的定義吧。定義如下所示:
虛擬歌手是一種透過電腦科學技術,以合成人類歌聲為目標的軟體或硬體裝置。
「欸,這聽起來很理所當然啊。我又不會爭論初音是不是軟體」──或許看完這個定義,讀者可能會這麼想。沒錯,確實很單純。但是光是這一點就可以排除一些誤區了。其中一個最大的誤區如下──
Vtuber不是虛擬歌手,Vsinger也不是。
等等,先等一下。Vsinger [6] 是一個簡稱對吧,全名叫做「Virtual singer」。那現在竟然說Virtual singer不是虛擬歌手?
沒錯,我的定義就是這樣。這裡真的具有一些歧異性。當然,就先來後到來說,最早「虛擬歌手」指的,本來就是機器合成的歌聲,而不是什麼有虛擬形象的歌手,但這不能作為任何證據。詞語的意思本來就有歧義性,而我在這邊也沒有想一錘定音的意思。我這裡下一個非官方的定義,僅僅是希望讀者不要搞錯我這一整個系列「虛擬歌手雜談」的主軸。
## 虛擬歌手,如何運作?
擺脫了難纏的定義問題後,讓我們回到仿生人的比喻吧。仿生人要唱歌。好,但在仿生人眼裡,什麼叫作「唱歌」呢?或者更進一步,對人類而言,「唱歌」究竟又是什麼樣的意思?
論點1a. 歌唱,或唱歌,是指人類透過發聲器官產生音樂的過程。
遇事不絕,就問維基百科。上述是中文維基百科「歌唱」[7] 條目的第一個句子。它聽起來很合理。只是,機器還是不太容易讀懂這句話的。就算先不談「發聲器官」是什麼,說到底,音樂從何而來,又該產生怎樣的音樂?
稍微修改一下定義後,我想大家會理解這之間的差距:
論點1b. 歌唱可以被視為一個函數。輸入的資訊是樂譜,輸出的資訊是歌聲。這個函數應當能夠根據樂譜的資訊,產生包含某個特定音色的歌聲。
於是我們定義了輸入與輸出。這乍聽之下有點奇妙。唱歌就唱歌,人人都會。我們不必時時看著一張滿是五線譜的紙張,甚至連樂譜本身的存在,也不一定是必要的。有些古早的音樂,可是沒有樂譜的。
只是,我們確實是根據樂譜唱歌的,雖然那可能是廣義的樂譜。我們聽一首歌,喜歡這首歌,進而記住了歌曲的旋律。隨後,我們用自己的聲帶,重現了歌曲的主旋律和歌詞──其中,那所謂的「主旋律和歌詞」,正可被視為廣義的樂譜。沒錯,我們就是在做把樂譜轉換為歌聲的工作。
既然我們可以,仿生人為何不行?
1997年,Yamaha [8] 公司找上了當時在MTG-UPF [9] 的Jordi Bonada [10]──就和我在虛擬歌手雜談的第一篇講的一樣 [11]。最初他們想合作發展的技術,不是現在我們熟悉的「虛擬歌手」,而是想建立一套卡拉OK的系統,把使用者的歌聲,轉換成任何一個歌手的聲音。譬如你走進卡拉OK,想唱〈アスノヨゾラ哨戒班〉[12],但是卻想要讓你的歌聲聽起來像Lia [13]?沒問題。於是你對著麥克風唱歌,但「唱出來的」卻像是Lia在唱這首歌的歌聲。
聽起來有點不切實際。我們不能真的去找Lia來錄這首歌。就算真的找來了,那改天我要她唱〈アヤノの幸福理論〉[14],那豈不是又不行了?就算都行好了,今天我不要唱得像Lia,而是要唱得像藤田咲 [15],那又怎麼辦?
於是2000年左右,他們改變了主意。好吧,那要不然,我只想合成同一個人的聲音呢?就像是MIDI合成器一樣。我們可以合成鋼琴的聲音,合成吉他的聲音,那能不能合成Lia的聲音?
也就是說,他們想要設計一個程式,可以做到:
給定樂譜作為輸入的資訊,輸出類似某個歌手唱這張樂譜的歌聲。
而結果就如大家所知。我們有了Vocaloid,我們有了初音ミク [16] 和IA [17],前者是模仿藤田咲,後者是模仿Lia的虛擬歌手。而前面舉出來的這兩首歌,原唱都是IA。當然,坊間必定也不乏初音ミク的翻唱(或說是翻調)版本。
## 具體來說虛擬歌手如何運作?
前面的一切講得都很輕鬆,但那卻是空泛的。所以具體來說你要怎麼實現虛擬歌手?這才是個問題。
但是既然我們給定了目標,又有了輸入和輸出的定義,一切就可以被拿來認真思考了。事實上,早在1990年代以前,人們已經在思考著該如何合成「類似真人說話」的聲音了,相關的研究也一直有在進行。當然,那已是十分古老的研究,而我自己對這些上古時代的方法,老實說也不熟。但這邊至少可以拿Vocaloid [2] 這個虛擬歌手引擎來當個例子。
對於Vocaloid來說,具體的運作方式是這樣的:
根據輸入的樂譜,Vocaloid從某個歌手事先錄好的聲音庫(Voicebank)當中,抽取出最適當的歌聲片段,根據給定的資訊,進行若干修飾、調整,最後拼接在一起,合成歌聲。
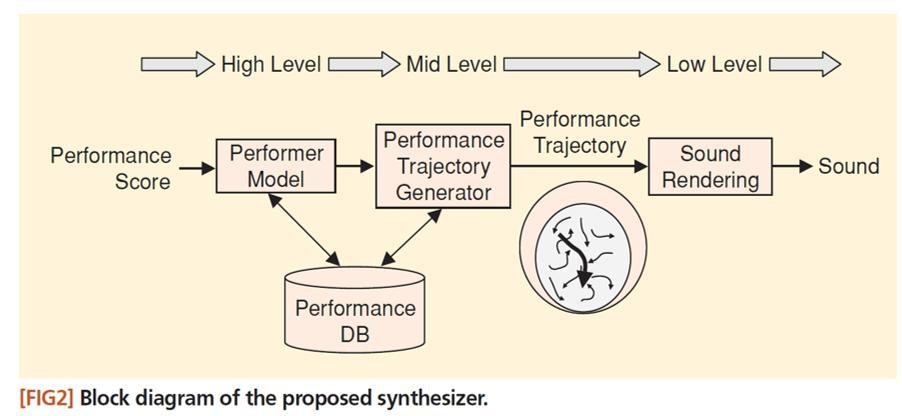
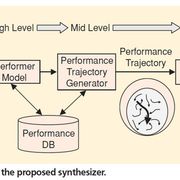
上圖是2007年Jordi Bonada在描述當時Vocaloid系統的論文 [18] 中的一張圖,正好可以貼上來做個講解。Performance score(廣義的樂譜,包括歌詞、音符,與一些表現的細節資訊,譬如音高、歌聲亮度的細節變化等等)會被輸入一個Performance model。這個模型會根據輸入的樂譜,去「查詢」Performance DB(也就是我前面所說的聲音庫Voicebank)。Performance DB裡面有一大堆事先錄好的音檔,而模型將從中找出最適當的一些音檔。
取出音檔之後,模型再做Performance trajectory generation(可以簡單看成是,計算出「該如何處理這一些音檔」的方法,譬如把某個音檔拉高四分之一個半音呀,音量拉大三個分貝,高頻部分往上拉一個分貝等等)。最後,模型根據這些方法,處理並拼接聲音庫裡面的音檔(sound rendering),湊來湊去,就合成了我們所聽到的歌聲。
相似的架構在2000年代以前已經被提出,但Jordi Bonada與Yamaha在這些架構之上,又做了許多的改良,達到了在當時(2000年代前、中葉)絕無僅有的合成效果。讀者可能很難想像,Vocaloid 2(2007年發布)的歌聲明明就充滿著機械音,怎麼會說那已是「絕無僅有」的效果?但在那個有些遙遠的,連智慧型手機都還不存在的過去,這樣的歌聲,已經足以震撼世人。
於是,舞台已經設好。2007年的那個夏天,初音ミク [16] 粉墨登場,劃開了一個時代的序幕,而剩下的都是歷史了。於是,仿生人真的唱起了歌──從niconico到Youtube,從日本到台灣,從網路上到現實的演唱會。
那一年,米津玄師 [19],一位從Vocaloid歌曲發跡,如今紅透半邊天的創作者,只有16歲;花譜 [20],著名的「可不」(CeVIO AI)[21, 22] 的音源的提供者,不過只有4歲;至於1973年出生的Jordi Bonada,那年34歲 [23],正值研究者的黃金歲月。
## 如何評價虛擬歌手
好吧,那麼一切都很好,我們有了Vocaloid,而人們以此為基礎,還創立了獨特的文化,一路影響至今。所以還有什麼問題嗎?
當然有。人們總要進步。我們不會希望讓2007年的Vocaloid 2定義了虛擬歌手的天花板。所以問題來了,怎麼樣才是一個好的虛擬歌手?
聽起來那並不是什麼大哉問。如果虛擬歌手能唱得更像真人,那自然就更好了。少數人可能會聲稱虛擬歌手就是要不太像真人才好,這樣才能與真人區分開來。但這說法與前面的論點並不互斥,因為我們可以輕易透過後製,讓「很真實的虛擬歌手」唱得像是帶有機械音一樣。
不過,真實的程度就是一切嗎?當前面那聽起來理所當然的正論,被轉換成這樣一個反問句,似乎便沒有那麼理所當然了。試想,小弟我自己的歌聲,當然很像真人,因為我自己就是真人,但我可不覺得自己的歌聲很好聽,所以我才會想讓虛擬歌手唱我的填詞,而不是我親自下去唱!
所以我們必須修改一下前面的論點,以容納這個明顯的反例。
論點2a. 一個好的虛擬歌手,需要能夠唱得很像真人,且唱得很好聽。
進一步來說,這個「很好聽」可能有點模糊,我們該進一步去修正這個說詞。怎麼樣才叫好聽呢?我認為這有兩種,其一是音色本身很好聽,而這某種程度上可能是天生的;其二則是唱功很好──透過日積月累,歌手會懂得該如何演唱一首歌曲,且能夠準確地執行這些演唱技巧。譬如音量、抖音、滑音、抑揚頓挫等等。好的歌手總是能做出好的判斷,且能夠執行得很好。
音色的部分,那是沒辦法,有時候那就是天生的,跟歌聲的提供者有關。但如果一個虛擬歌手程式能夠對演唱方式做出好的預測,並且有能力根據這些預測結果做出調整,那麼,肯定就能輕易合成「好聽」的歌聲吧。
論點2b. 一個好的虛擬歌手,需要能夠唱得很像真人,且能夠預測出好的演唱方式,並且準確地表達出這些演唱方式。
值得注意的是,上面的這個論點,如果把「虛擬歌手」代換成「歌手」,同樣也有合理之處。當然,我們不會說一個歌手很會「預測」演唱方式,而會說他「懂得詮釋歌曲」,但意義上是類似的。
好吧,上面的論點2b或許已經足夠充分,容納了所有會讓虛擬歌手更好的條件。但這些真的是必要的條件嗎?試想,Vocaloid引擎並不會「預測」很多的演唱技巧。根據Vocaloid的設計,該不該用某些演唱技巧,大部分都是使用者需要指定的。使用者要告訴它什麼時候要抖音,什麼時候要滑音,什麼時候歌聲要唱得清亮一些,什麼時候演唱的力度要強。
但Vocaloid真的就這麼爛嗎?
從另一個角度想,只要被能夠做出神調教的人使用,Vocaloid是可以唱得很好的。這樣一個厲害的人,能夠靠自己,便很好地做出歌唱技巧的判斷。而接收到這些判斷之後,Vocaloid只負責執行,但結果同樣好聽。
當然,如果使用者不懂得如何調Vocaloid,那麼Vocaloid也就不會生出多好聽的歌聲來。相較之下,一個懂得做出好的判斷的虛擬歌手引擎,在任何人的手上都能合成好的歌聲。在任何意義上,後者應該還是能勝過Vocaloid這種「靠工人智慧判斷,自身只負責執行」的模式吧。
根據這一個觀察,我們再改寫論點。
論點2c. 一個好的虛擬歌手,需要能夠唱得很像真人,且能夠準確地表達出給定的演唱方式。並且,它需要能夠
(1)預測出好的演唱方式,或
(2)容納足夠多關於好的演唱方式的指示
其中,(1)的重要性大於(2),(2)只是(1)的替代方案。
這樣的論點引入了調教(調聲)的重要性,並將可調教性(容納演唱方式的指示),也就是「能讓使用者調教的空間」的多寡列入了考量,但同時也將這一點置於預測演唱方式之下。對於某一個演唱方式,譬如音高的細節變化好了,虛擬歌手引擎若能自動自發預測好,那當然最好;其次,至少也要能提供使用者自己做出判斷,自己做出調整的空間;至於既不能自行預測參數,又不能容納任何調整的虛擬歌手,那就是最差勁的了。
考慮到上面的論點,其實有個詞就需要向大家介紹了,就是「ベタ打ち」。這個詞原先似乎是指在寄電子郵件的時候,沒有對文字格式(字型、字體、顏色等等)做任何調整的情況。在虛擬歌手這邊,指的就是什麼調教都沒做,純粹把歌詞和音符打進去,由此合成出來的音檔。
也就是說,「ベタ打ち」合出來的音檔,代表排除了調教的因素,純粹讓程式自行預測演唱方式,自行合成的效果。因此,人們通常會用「ベタ打ち」的結果,來判斷一個虛擬歌手引擎的地板。譬如這個影片 [24] 就是比較了三組同樣的虛擬歌手、同一首歌,但使用不同虛擬歌手引擎,ベタ打ち的結果,可以從中看出這些虛擬歌手引擎(Vocaloid、CeVIO、CeVIO AI [22])的地板。
至於天花板,那自然是那些優秀的調教過的歌聲了──通常出自一些很會調虛擬歌手的大手。當然,介於天花板和地板之間,或許還是得看「平均值」之類的東西,那就得要多聽幾首才能知道了。或者,讀者如果有心,也可以直接把那些虛擬歌手引擎弄來調調看,就能簡單看出可調教的空間多寡了。
可想而知,具體這些地板呀,天花板呀,平均值之類的分數,彼此不一定相關,也有可能出現「有一好沒兩好」的狀況。這便是大家自由心證,自行權衡輕重的時候了。好在我們畢竟不是研發虛擬歌手引擎的人,不必嚴謹地做出判斷。而我這裡寫出這些,也只是想給大家一個概念,解釋到底評價虛擬歌手,會有多少不同的層面而已。更進一步來說,我也想試著解釋,那些研究虛擬歌手的人,究竟想做出怎麼樣的虛擬歌手,又正眺望著怎樣的未來。大概就這樣吧。
## 結論
其實我很難想像,假如我置身在2000年的巴塞隆納(Jordi Bonada所屬的MTG-UPF [9] 所在的地方。他原先在MTG-UPF,之後才成立Voctro Labs [25]),聽人說要研發虛擬歌手的時候,自己會怎麼想。那肯定是很荒謬的事情吧。那時網路才剛開始發展,電腦螢幕還是笨重的映像管,硬碟空間連個100GB都不一定有。然後遠在日本的Yamaha公司告訴我,他們想要讓電腦唱歌?
哈哈哈,笑死。
假如我置身在2007年末的東京,聽說一個叫做「初音ミク」的玩意兒……那啥,動畫角色?不懂啦,但那人物唱著詭異的歌聲,「メルト/溶けてしまいそう」(ryo〈メルト〉[26])。噁,那聲音這麼怪,還有人喜歡聽?
笑死,那些喜歡聽的人都是死肥宅啦,根本只是喜歡那張人設圖罷了。
假如我置身在2022年的台北,聽著一首又一首的歌曲。聽初音,聽IA,也聽可不。有的歌曲聽起來就像真人,有的歌曲聽起來則充滿著特性,充滿著深刻的情感。有美好的追憶,有尖銳的悲鳴,有動人的愛情,也有輕快的,彷彿像遠方的樹一般,隨風翩翩起舞的樂句──
噢,不,事實上,我確實置身在2022年的台北。
於是我終於能理直氣壯,向不曾聽過虛擬歌手的,我的一位朋友宣告:沒錯,仿生人不僅夢見了虛擬歌手,事實上它成為了虛擬歌手──而且還將超越昨天的自己,成為更加優秀,更能把人們心中的感情全數唱出來的虛擬歌手。
它將承載人們的夢繼續前進。
至於我該做的,則是把這些關於虛擬歌手的故事,用自己的筆寫下來。那不一定是獨特的,也不一定是最棒的,但我想說些什麼,那是確實的,就像十多年來依託著虛擬歌手而創作的,那些我無法望其項背的大人物一樣。
## 歌曲推薦(並沒有)
因為這次已經寫夠長了,我不推薦歌曲。但是,既然這次正好是提到虛擬歌手的概述,我想推薦這個「Vocaloid達人挑戰」https://reurl.cc/Np7X25。
裡面基本上就是一堆關於虛擬歌手的知識,不限於Vocaloid──雖然主要還是Vocaloid。今天看到這個東西,做了一下(不過只得46分,以我聽了快8年V家歌曲來說,或許不太及格)。不過,我確實十分感慨。那裡面橫跨了15年來各種虛擬歌手的歌曲、創作者等等。我想那正適合放在這個地方,作為結尾。歡迎大家聊聊自己得了幾分~
## 參考資料
[18] J. Bonada and X. Serra, “Synthesis of the Singing Voice by Performance Sampling and Spectral Models,” in IEEE Signal Processing Magazine, vol. 24, no. 2, pp. 67-79, March 2007.