其實從 2008 年開始寫程式以來斷斷續續的這 12 年裡,花最多時間的項目應該就是爬蟲了,不寫篇爬蟲的文章還真說不過去。
在開始之前還是要先講一下,這篇文章適用於「已經具有基本程式碼閱讀能力」的巴友,也就是說只要你通曉任何一種常見的程式語言,具有基本的函式、迴圈、陣列等觀念,這篇文章應該不算太難。
雖然我平常寫爬蟲的程式語言都是以 Go 語言(Golang)為主(畢竟可以直接編譯成 exe 或 DLL 檔案,很方便),不過考量到建置環境之類的還是 Python 比較簡單,大部分接觸到網頁爬蟲的人也都是以 Python 為主,所以這篇文章我會用 Python 作例。
。何謂爬蟲?
這裡不探討狹義的「網路爬蟲」指的是哪一種。我們如果寫出一套程式可以代替我們從特定網站上面抓取資訊,這種程式就可以泛稱為網路爬蟲。
比如說,如果你是一個巴哈姆特的使用者,你想要定期知道你的帳號巴幣增加了多少,那你可以每五分鐘 F5 一次自己的小屋,然後把你的巴幣數量記錄下來,再計算你的巴幣如何變化,就可以達到你的要求。
但是這麼做當然很麻煩,你應該也不會想為了這麼件小事情而整天泡在電腦前面按 F5 浪費時間——我們可以用爬蟲來代替我們做到這件事。
。資料從哪來?我要如何開始?
在做爬蟲以前,你應該要先問問自己:「我需要什麼資料?資料從哪來?」
以這篇的範例來說,既然我們想要追蹤特定帳號的巴幣增減情況,顯然只要找到能夠讀取到這個人最新的巴幣數量的地方就好了——直覺上應該要去讀取這個人的小屋,因為我們通常可以在小屋看到他的巴幣數量。
先不急著談如何優化,我們就從小屋開始吧。到對象的小屋,找到有巴幣的欄位,右鍵 > 檢查(檢測元素):
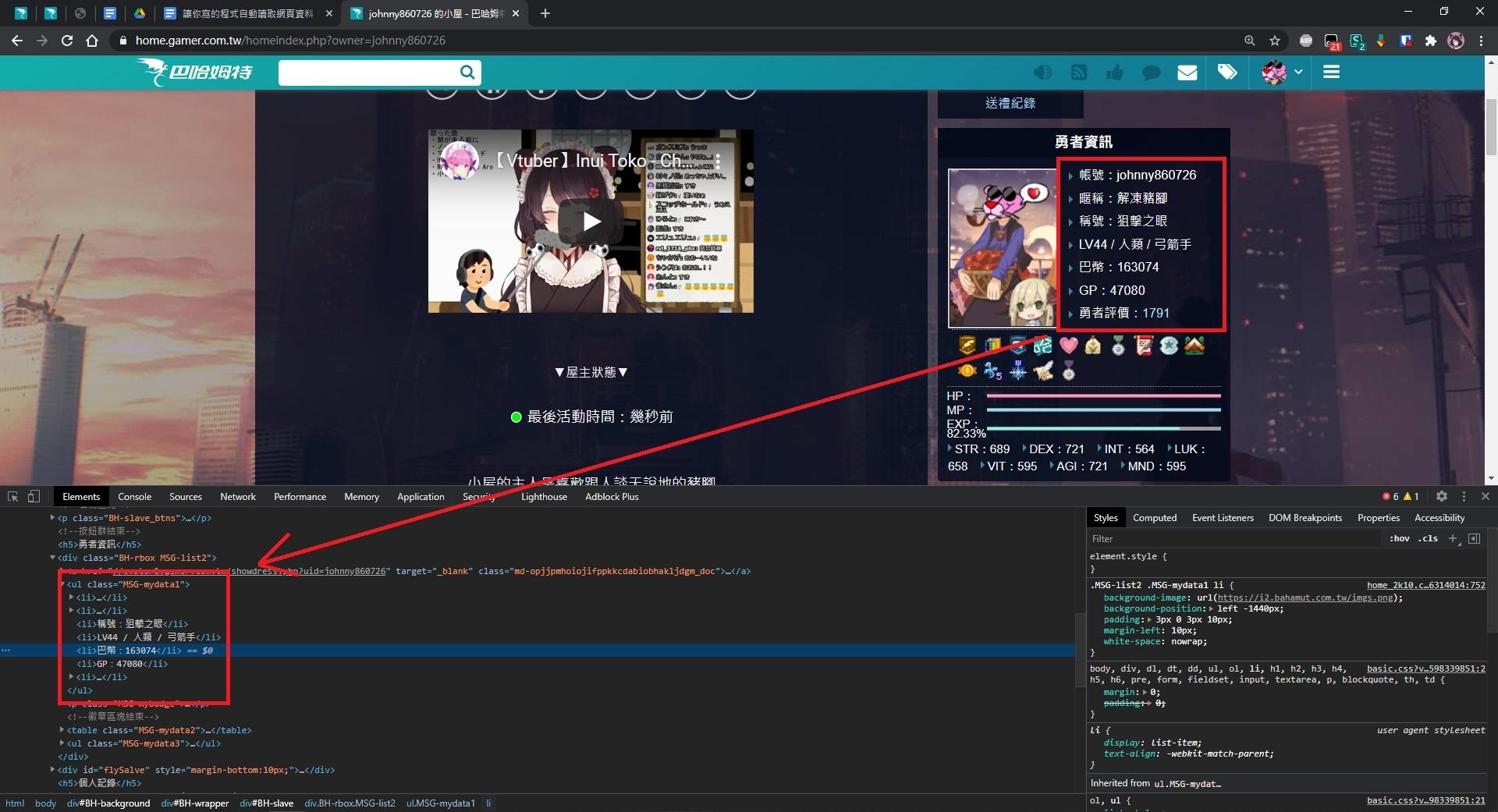
回想一下之前在《論壇是怎麼架設的?自己動手做做看!(一)》講過的基本觀念,你會知道當你在讀取豬腳的小屋時,就是向 home.gamer.com.tw 發出連線請求,告訴巴哈姆特你想讀取 johnny860726 這個帳號的小屋,接著巴哈姆特的伺服器就會按照工程師當初設計的流程,產生一個網頁並且傳回來,我們的瀏覽器就會呈現出你看到的樣子。
當我們使用檢測元素功能的時候,看到的一整坨 HTML 結構就是巴哈姆特伺服器傳回來但還沒經過視覺化的內容,這些內容我們也可以從原始碼模式(快捷鍵:Ctrl+U)看到,不過用檢測元素功能來分析網頁結構會更方便,畢竟瀏覽器都已經幫你解析好了。
我們先在 py 檔案裡準備好用來讀取網頁的工具:
from urllib.request import urlopen
from datetime import datetime
import urllib, time, json
def doGet(url, encoding='utf-8'):
url = urllib.request.Request(url)
url.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36')
res = urllib.request.urlopen(url)
return res.read().decode(encoding)
接著只要呼叫:
resp = doGet("https://home.gamer.com.tw/homeindex.php?owner=johnny860726")
得到的 resp 就是網頁的內容了。不過,當我們在使用爬蟲讀取網頁的時候,它真的就僅僅讀取這個網頁而已,即使這個頁面嵌滿了圖片,這些圖片的內容也不會被程式讀取,所以它讀取網頁內容的速度通常會比我們用瀏覽器還要快上很多。
可以想像,如果今天有一個字串「XXX<li>巴幣:12345</li>XXX」,如果我們要抓到中間的 12345,那當然就是抓「<li>巴幣:」到「</li>」中間的數字——利用字串的 split 函數先以「<li>巴幣:」把 resp 的內容切開取右半部(也就是「12345</li>XXX」),然後把這坨東西再以「</li>」切開取左半部,得到字串 12345,接著再用 int() 轉型就得到可以參與計算的巴幣數據了。
不過,使用 str.split(A)[1].split(B)[0] 也是有風險的。如果不巧剛好在讀取的時候發生了意外(比如說巴哈姆特伺服器當機、追蹤對象的小屋被查封),這樣 str.split(A) 的長度就只會有 1 了:
正常情況下:
resp = "ABC<li>巴幣:12345</li>XYZ"
resp.split("<li>巴幣:") → 得到 ["ABC", "12345</li>XYZ"]
異常情況下(沒有顯示巴幣欄位):
resp = "ABCDEFGH"
resp.split("<li>巴幣:") → 得到 ["ABCDEFGH"]
我們對於後者這種長度只有 1 的陣列取 [1] 的話,自然就會引發 list index out of range 的錯誤,導致程式終止。
所以我們可以適時使用 try-except 來捕捉錯誤,做相應的處理,讓程式不要在發生錯誤的時候直接停止運作:
resp = doGet("https://home.gamer.com.tw/homeindex.php?owner=johnny860726")
try:
gold = int(resp.split("<li>巴幣:")[1].split("</li>")[0])
print(gold)
except Exception as ex:
print("讀取巴幣資料時發生了錯誤:", ex)
這樣就初步達成了「讀取巴幣」的需求。
我們只要設一個變數,用來儲存目前的巴幣數量,然後每隔一段時間比較一次,就能知道這個帳號的巴幣增加(或減少)了多少:
nowGold = None # 初始化
while True: # 無條件重複迴圈
timeStr = '[' + datetime.now().strftime('%H:%M:%S') + ']'
try:
resp = doGet("https://home.gamer.com.tw/homeindex.php?owner=johnny860726")
gold = int(resp.split("<li>巴幣:")[1].split("</li>")[0])
if nowGold == None:
nowGold = gold
print(timeStr, "目前持有巴幣:", nowGold)
if gold > nowGold:
print(timeStr, "巴幣增加了", gold-nowGold)
elif gold < nowGold:
print(timeStr, "巴幣減少了", nowGold-gold)
nowGold = gold
except Exception as ex: # try 區塊的程式碼發生錯誤的情況
print(timeStr, "讀取巴幣資料時發生了錯誤:", ex)
time.sleep(300) # 等待 300 秒
注意,這個 time.sleep 要像這樣在 while 區塊裡面,不要漏掉一層縮排。
這樣一來就能初步做到「自動追蹤巴幣數量變化」的功能,只要把程式開著執行就可以知道大概在什麼時候增減多少巴幣了。
。為什麼要設定等待間隔?
你可以想像一下:現在你處在一個公共場所,這裡有一個非常巨大但流量有限的水龍頭。水龍頭的建設者最初預期大家都會拿來做些洗手、洗臉這樣簡單的事情,然而你把這水龍頭接上水管,將水龍頭開關開到最大,就這樣一直開著讓水流不停,即使浪費水資源也不管。
這樣會造成大家的困擾嗎?不一定,也許這個水龍頭的流量還堪你一人這麼做,對大家並不會造成影響——那如果大家都這麼做呢?
伺服器就忙到爆了。使用爬蟲如果不設定時間間隔,讀取完一次網頁之後馬上又接著讀取一次,就會導致伺服器加重負荷。對方的網站伺服器架在那裡,平時就要花時間應付成千上萬次來自一般使用者的連線請求,要是大家都使用沒有頻率節制的爬蟲,就會導致伺服器壅塞、回應一般使用者的速度變得更慢(甚至停擺),這也是 DDoS(分散式阻斷服務攻擊)的基本原理。
某些防護較為嚴格的伺服器,一旦發現你有多次異常高頻率發出連線請求的情況,還可能會乾脆把你的 IP 封鎖掉,讓你不能使用該網站。
除此之外,使用沒有節制的爬蟲也會導致你的電腦網路速度也跟著變慢,因為你大部分的網路頻寬都用在發出連線請求上面了。所以,一般來說我們使用網路爬蟲,宜取數十秒到一分鐘的間隔,而要是這些資料沒有那麼重要,你可以再把讀取資料的頻率降低到好幾分鐘一次。
。它是最好的資料來源嗎?
顯然不是。我們在選擇來源的時候,最好確定這個資料來源專一又穩定。
怎樣算是專一?比如說,我們讀取對方的小屋的時候,必然會出現很多(對我們來說)無關緊要的東西,像是個人相關資訊、訂閱聯播、上站日期、最新創作、大聲說……。為了不要花太多時間去抓取這些我們根本用不到的資料,我們最好找到一個更簡潔的來源。
怎樣算是穩定?比如說,對象帳號如果因為小屋違規或是永久禁貼而導致小屋被查封,那現行的方法就會變得沒有效用。
所以從上面兩點來看,直接從小屋讀取這個人的巴幣不是最好的方法。做爬蟲的時候應該要想想:「這是最好的資料來源了嗎?我們還有哪些更好的來源可以選擇?」
單以巴幣的數據而言,我們會注意到除了小屋以外,我們可以從「滑鼠移到勇者造型頭像的時候,顯示出來的面板」看到這個人當下的巴幣數量:
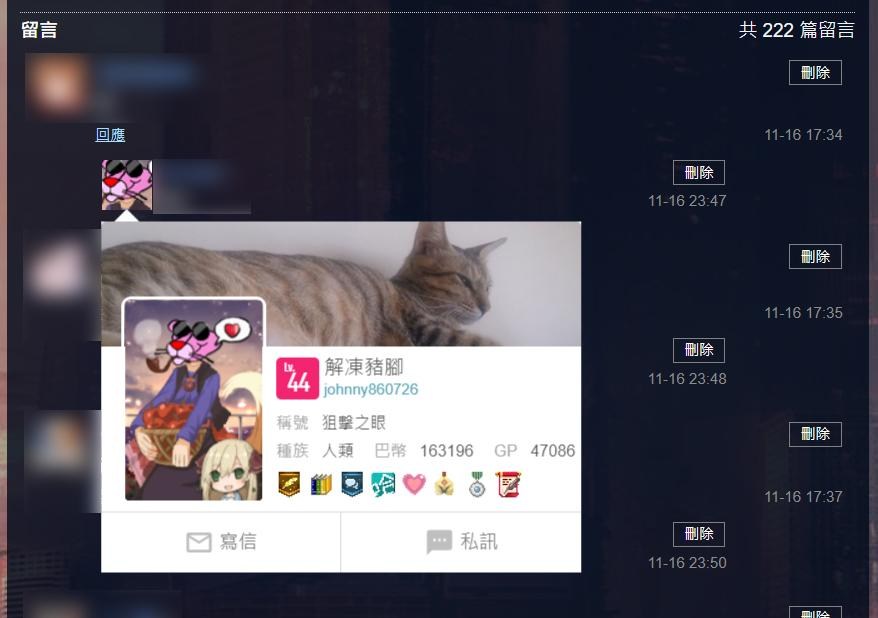
不過問題來了:「我們要怎麼從這裡取得資料?」
通常這種互動式顯示出來的視窗,都是在使用者把滑鼠移上去的時候才另外發出連線請求、讀取資料,而不是預先把整個頁面所有人的勇者資訊通通讀取完才發過來,這種技術就是所謂的 AJAX。
我們就可以再次利用 F12,選擇 Network(網路)標籤來監聽瀏覽器發出的連線請求,然後把滑鼠移到勇造頭像上面,看看有沒有新的連線請求發出:
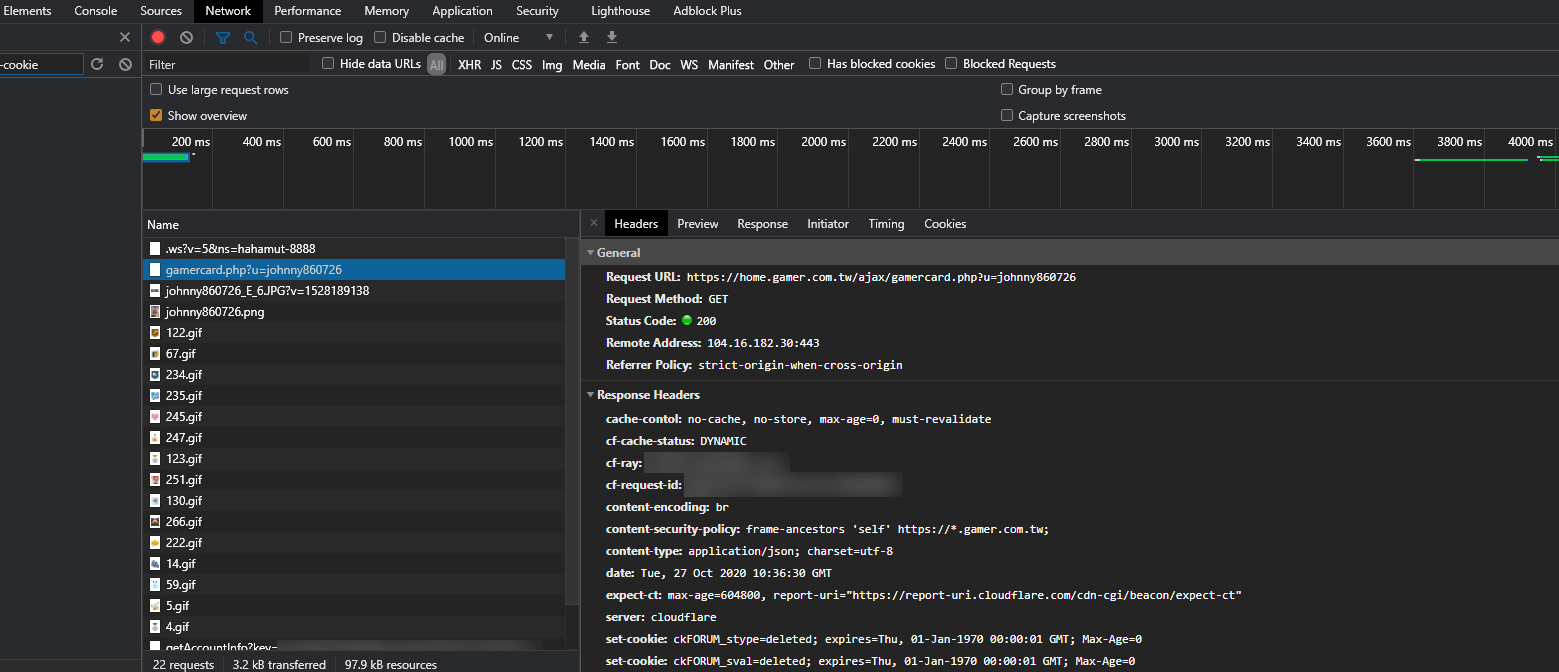
看看它的內容:
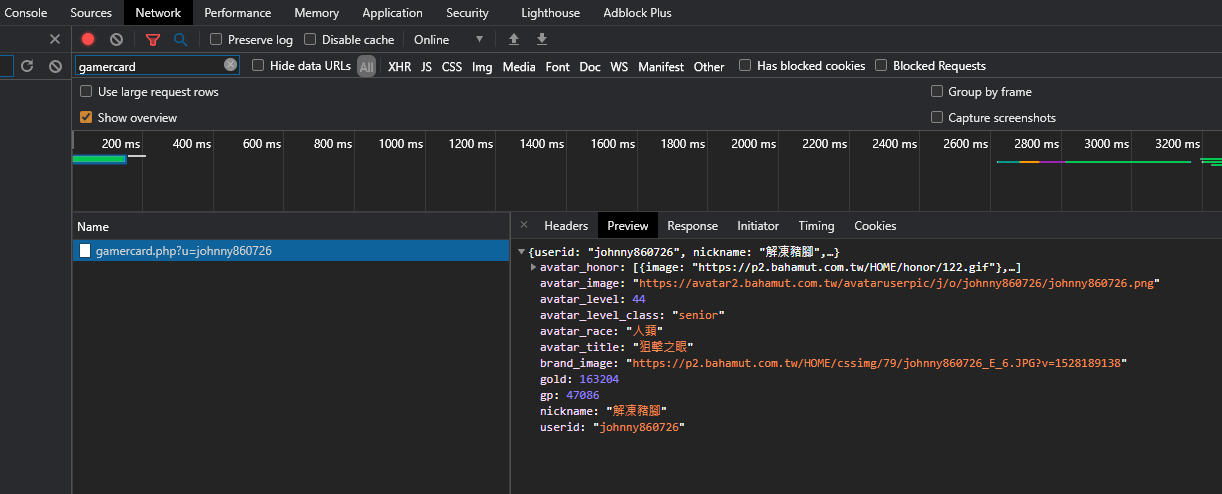
確實是我們想要得到的資訊,因此我們找到了:
得到結論:這個網址就是讀取巴哈姆特勇者基本資訊的 API。這個 API 包含了勳章、勇者造型網址、等級、等級類型、種族、稱號、小屋區塊圖片、巴幣、GP、暱稱、帳號等資訊,而且資料內容非常輕盈,甚至不到 3 KB——而要是我們像前面那樣直接讀取小屋主頁的話,傳送的資料可能會多達 50、60 KB,在讀取大量內容的時候就會有效率上的差別了。
現代的網頁技術,一般都會把要傳送過來的的資料架構像這樣變得更輕量化,整理一下可以發現真的很乾淨:
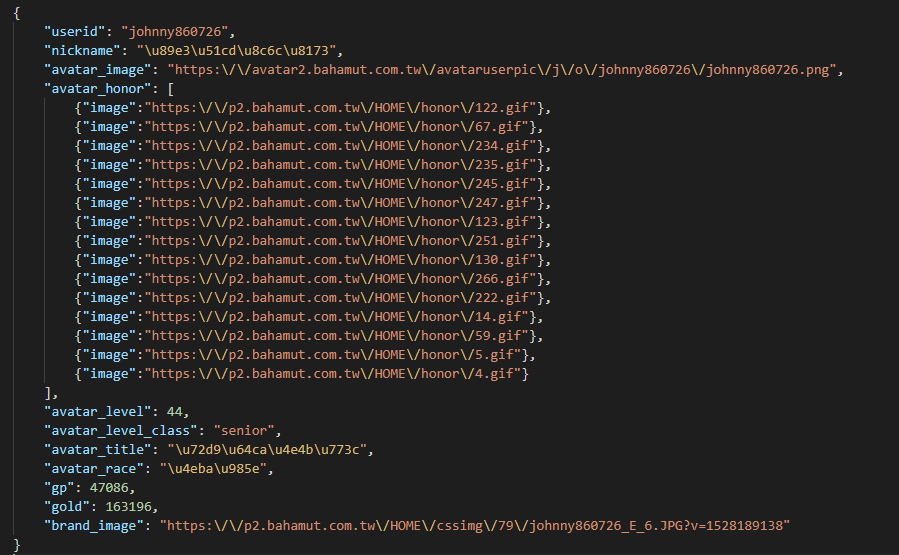
傳回來的資料沒有包含任何多餘的 HTML 標籤,輕盈又整齊。這樣的做法除了減輕伺服器處理資料的負擔以外也省掉很多流量,這些資料傳送過來以後只要交由使用者的瀏覽器來處理就行了。
這種格式很靈活,可以儲存字串、數值、布林代數、空值(null)、陣列(array),而且物件底下還能再包一層物件,稱為 JSON 格式。
不過傳回來的整串資料不經處理的話終究只是個字串,JSON 格式的字串我們利用開頭 import 進來的 json 函式庫,就能把這堆字串解析(parse)成可以被輕易讀取的格式:
resp = doGet("https://home.gamer.com.tw/ajax/gamercard.php?u=johnny860726")
respJson = json.loads(resp)
gold = respJson['gold']
因為這裡的 gold 本來就是以數值的方式儲存,所以我們不需要再另外用 int() 轉型,直接拿來用就行了。
。根據得到的資料模式,要用相應的解析方式
但也不是所有的網站都會全部使用 JSON 格式來傳送資料,而且你想要的資料也不會總是出現在 JSON 格式的 API 裡。
比如說,假如你想要抓取特定帳號的最後上線日期,那(就我所知)真的就只能從小屋主頁來讀取了:
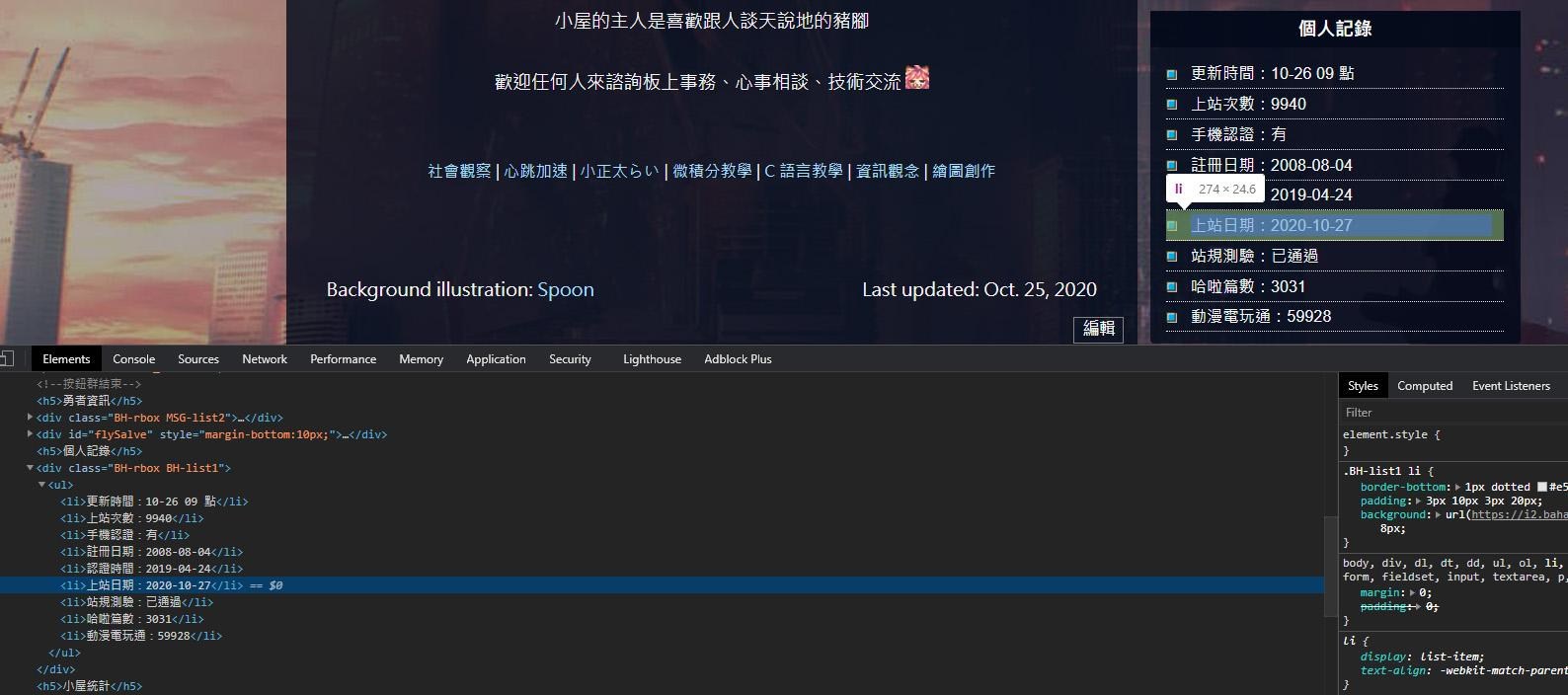
實際上,剛才最早提到的 string.split 方法是很粗糙的,我們在網頁上爬資料的時候不見得這些欄位都是唯一的,比如說我們抓到的 response 內容有很多個符合的欄位:
resp = "<div>創作名稱:霸道總裁豬腳</div><div>創作名稱:瘦瘦可愛的男孩子豬腳</div><div>創作名稱:昏睡惡臭豬腳</div>"
這時候你使用 resp.split("<div>創作名稱:")[1].split("</div>")[0] 就只會得到霸道總裁豬腳了。雖然這樣的問題不是完全無解,但這種從字串直接提出內容的方法可以說是土法煉鋼,而且還很不便於鎖定某個小區域(比如說你明明只想抓 A 區塊的創作名稱,但這麼做就可能連同 B 區塊的創作名稱也一起抓進來了)。
既然剛才針對 JSON 格式的時候我們使用 JSON 的 parser 來處理,那麼當我們遇上 HTML 格式,我們自然就應該用 HTML 的 parser 來處理。
在命令提示字元(你執行 Python 程式的地方)輸入「pip install pyquery」指令然後執行,你的 Python 開發環境就會有 PyQuery 的函式庫了。接著在你的 Python 程式碼前面引用函式庫的地方把它 import 進去:「from pyquery import PyQuery」就可以使用 PyQuery 來解析 HTML 的格式。
假設我想要把我的小屋創作名稱和網址列出來,我就應該要先到我的小屋創作列表,去研究「小屋創作的名稱應該會用什麼形式出現?」這樣的問題:
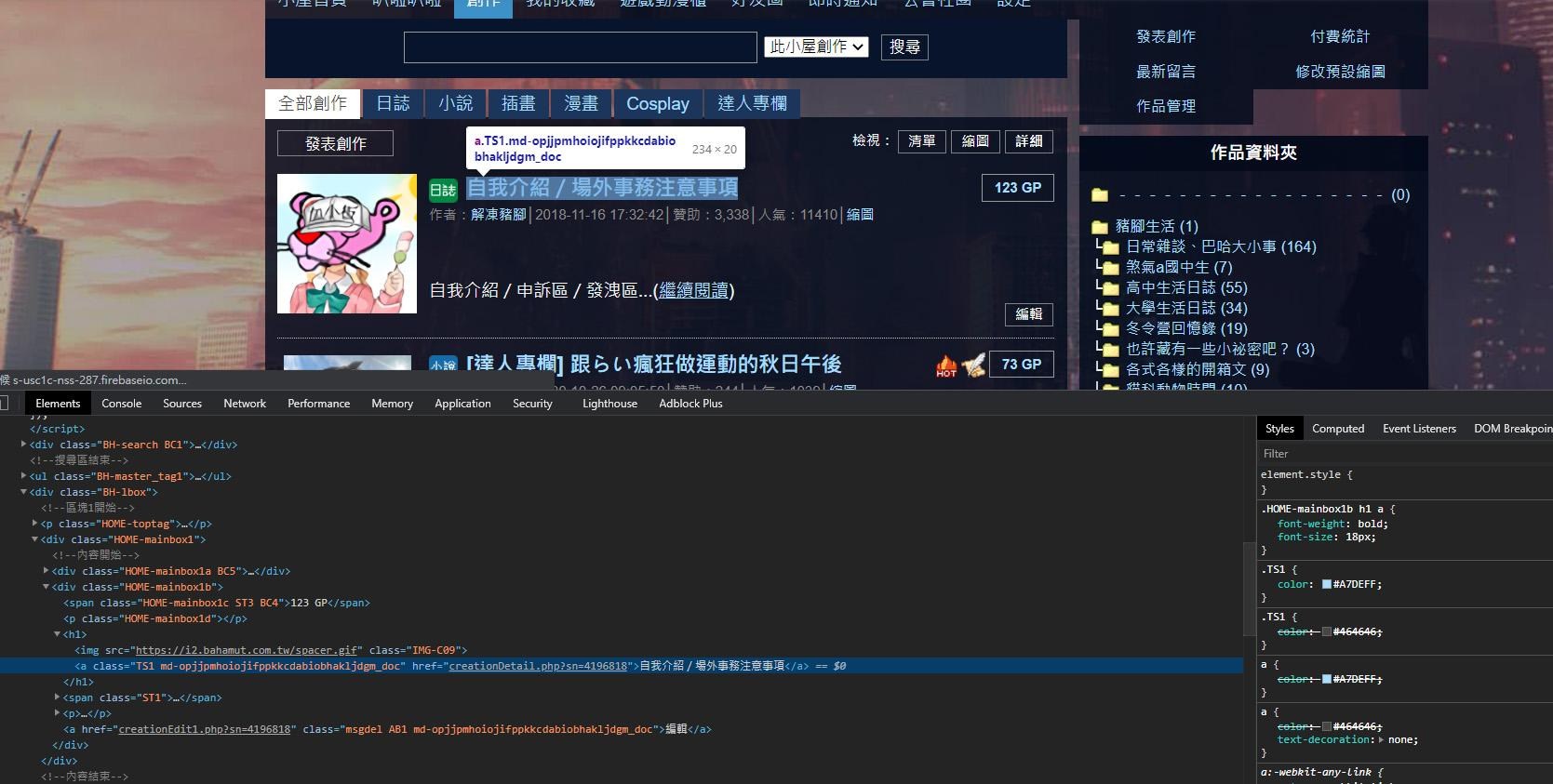
我們做爬蟲的時候,必須摸清對象頁面的特性。通常同一個 class 的元素,代表是同一類的東西,所以我們可以猜測這個頁面 class 為 TS1 的元素都是創作文章標題。
使用 PyQuery 解析 HTML 格式的時候,你必須弄懂 CSS selector:
div 代表標籤名稱為 div 的元素(比如 <div>...</div>)
.div 代表 class 為 div 的元素(比如 <span class="div">...</span>)
#div 代表 id 為 div 的元素(比如 <a id="div">...</a>)
當然 CSS selector 還有更多功能,只要 Google 搜尋 CSS selector 就有很多範例了。
要讓 PyQuery 把所有 class 為 TS1 的元素遍歷一次,我們用 '.TS1' 來搜尋:
resp = doGet("https://home.gamer.com.tw/creation.php?owner=johnny860726")
for title in PyQuery(resp).find('.TS1').items():
print(title.text())
print(title.attr('href'))
執行看看:
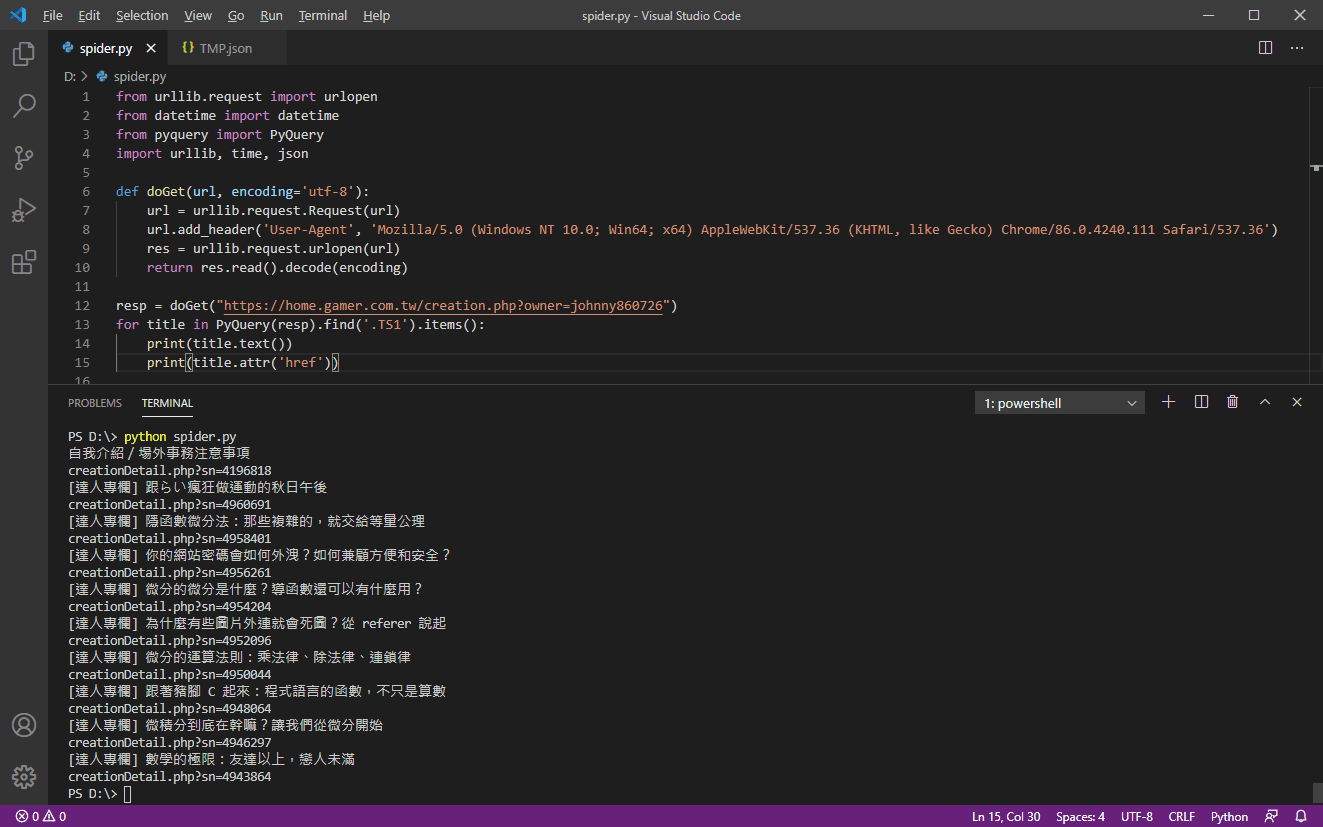
成功了!光用這四行,就已經達成了把特定帳號的創作(第一頁)基本資訊抓下來的目的。
。掌握資料的流向
爬蟲可以做的事情太多了,只要你能掌握資料的流向。
比如說,我們如果想要把這個人的「每篇」公開創作都列出來,我們就要先知道他的小屋創作總共有幾頁,於是到他的創作列表研究,可以發現「頁數按鈕區的最後一顆鍵就顯示了這個人的小屋創作總共有幾頁」,接下來利用:
PyQuery(resp).find('.BH-pagebtnA > a:last-child').text()
先抓到總頁數(得到 73),然後再從第 1 頁開始抓,抓到 73 頁:
respA = doGet("https://home.gamer.com.tw/creation.php?owner=johnny860726")
maxPage = int(PyQuery(respA).find('.BH-pagebtnA > a:last-child').text())
for page in range(1, maxPage+1):
respB = doGet("https://home.gamer.com.tw/creation.php?owner=johnny860726&page="+str(page))
for title in PyQuery(respB).find('.TS1').items():
print(title.text())
print('https://home.gamer.com.tw/'+title.attr('href'))
time.sleep(3)
這裡的迴圈就相當於把這 73 個頁面讀取一次(間隔 3 秒):
…
我們就實現了整個流程的自動化。
做爬蟲的時候,除了要瞭解這個網站的 HTML 結構如何安排之外,也要知道這個網站的網址裡各參數代表了什麼意義。比如說我們透過觀察可以發現,巴哈姆特小屋的 creation.php 其中的 owner 參數代表小屋主人的帳號,page 代表頁數(諸如此類)。
因為每個網站的設計模式都不一樣,所以爬蟲並不是遵照 SOP 做出來就能適用於所有網站的東西。如果你想設計一套能夠代替你做事的自動化流程,那你就要學會去觀察、研究。開發爬蟲很大程度必須依賴程式開發者利用瀏覽器的開發者工具(F12),自行從中找到規律。
像今天舉的例子看起來好像沒有什麼用,但實際上只要稍微修改一下再加上檔案讀寫的功能,它就成了一個能夠自動備份小屋所有創作的程式,至於如何實現就等有機會再來說吧,當然你也可以自己試著做做看——總之不要忘了在 request 之間加上時間間隔。
當你把網站研究得足夠透澈的時候,任何大規模的重複動作就都難不倒你了。