只要你稍微關注PC硬件的發展,就不難發現關於AMD翻身作主的論調時不時就會出現。這樣論調出現的時候,往往還伴隨AMD即將問世新品的各種謠言。從桑德斯時代開始,AMD就從未停止過對Intel的挑戰。儘管幾十年的爭奪並沒有讓AMD佔據上風,但在RYZEN發布這個重要時刻,我們依然有必要回顧RYZEN的前世今生,向處理器行業的孤膽槍手致敬。
在K7上,AMD直接沿用了來自DEC Alpha 21264架構的EV6總線,並且使用了0.25微米工藝。首發代號Pluto的Athlon處理器第一次在綜合性能上全面超越初代奔騰3處理器。 AMD Athlon的異軍突起並沒有完全撼動英特爾王朝,但在兩強爭奪下Cyrix、IDT、全美達等紛紛成為炮灰,直接導致x86處理器進入了兩強爭霸時代。“在芯片設計的核心技術上,我們同英特爾旗鼓相當。“——AMD時任CEO傑里·桑德斯(Jerry Sanders)
2003,大錘崛起
通過K7,AMD第一次獲得了完整的CPU架構和總線設計經驗。到了K7的繼任者K8上,AMD顯然需要更進一步。儘管代號Hammer(大錘)的K8處理器在微架構上與K7一脈相承,但卻突破性的將內存控制器放在了CPU內部,直接消除了前端總線瓶頸。而X86-64的引入,也讓X86的4GB內存尋址瓶頸之爭塵埃落定。
在K8身上,AMD充分展現了以小博大的智慧——通過極低成本的方式在x86平台上引入了64位支持,徹底堵死了英特爾IA-64安騰的桌面征途。同時K8桌面處理器Athlon64還將對手Intel Pentium 4處理器逼向了死角。由於Intel 90納米工藝撞牆,Pentium 4處理器止步於4GHz,最終未能取得對Athlon 64的勝利。時任Intel CEO的貝瑞特也被迫下跪道歉。
時至今日,包括Windows在內的許多軟件都對X86實現64位支持的方法統稱為AMD64或X64,而不是Intel被迫跟進的EM64T。 K8處理器的大獲成功也讓AMD從2003年起進入了前所未有的鼎盛時期。
“回首過去5年,計算領域的每一項重大創新都來自AMD,沒有一項來自英特爾。”——AMD時任CEO魯毅智 (Hector Ruiz)
2006,收購冶天(ATI)
一旦你在某個業務上獲得成功,最簡單的方法是複制這種成功到其他領域。 Intel在很早以前就擁有了圖形芯片設計和製造能力,在NVIDIA誕生以前,Intel i740圖形芯片甚至一度稱霸市場。直到今天,Intel依然牢牢佔據圖形芯片市場70%以上的份額。
在K8獲得成功之後,Intel開始通過Core 2 Duo處理器扭轉戰局。此時的AMD認為除了處理器,圖形芯片的設計製造整合能力也至關重要。 2006年7月24日AMD斥資54億美元收購了ATI冶天科技,由此獲得了高端GPU、集成圖形核心IGP,移動GPU的設計和生產能力。並迅速推出了集成顯卡的AMD K8主板芯片組Radeon IGP。
小說中蓋茨比最終無法贏取白富美,短暫輝煌的AMD迅速遭遇了Intel Core 2 Duo、Intel Core 2 Quad的反撲,CPU、GPU制霸夢想也隨之破滅。更要命的是,收購ATI帶來的巨額投資很快會遭遇報應,讓AMD跌入深淵。
“我們已經是這個領域名副其實的領導者。”——ATI冶天科技創始人、前董事長、CEO何國源
ATI冶天科技創始人、前董事長、CEO何國源
2009,斷臂求生 K7開始自力更生,K8翻身作主,收購ATi獲得GPU設計製造能力,但挑戰者AMD的營收依然遠不日老對手英特爾。收購ATI的54億美元幾乎耗盡了K7、K8競爭優勢積攢下來的家底。隨後AMD遭遇了英特爾全方位的產品反撲和價格戰。 AMD股票遭遇了斷崖式下跌——AMD股票價格從2006年2月24日的40.54美元下跌到了2009年2月20日的2.03元,股市的劇烈波動迫使AMD斷臂求生。2009年3月2日,在AMD股價達到歷史最低點的一個月後,時任AMD CEO的魯毅智依然決定將旗下的晶圓製造廠賣給阿布扎比先進技術投資公司(,Advanced Technology Investment Company)。 ATIC買下AMD晶圓廠之後,將其命名為GLOBAL FOUNDRIES(格羅方德)。至此,AMD創始人,號稱矽谷牛仔的桑德斯再也無法自豪的宣稱有Fab才算真男人了。
“如果和阿布扎比的交易沒有成功,AMD就無法生存下來。” ——AMD時任CEO魯毅智(Hector Ruiz)
在出售Fab同時,AMD還將旗下移動圖形芯片業務Imageon出售給了高通公司,隨後高通在Imageon基礎上拿出了第一代Adreno GPU。時至今日高通Adreno GPU已經制霸了移動市場,市場規模遠超x86 CPU。在斷臂求生的同時,AMD在CPU研發上也開始畏首畏腳。曾經代號K8L的CPU被AMD強行更改代號為K10。並在最後的又更名為AMD 10h(第10代處理器架構)。儘管最終奕龍Phenom相對Ahtlon64處理器有不少提升,但隨後還是被英特爾代號Nehalem的Core i7處理器打得滿地找牙。被AMD寄予厚望的融合CPU和GPU的FUSION計劃,也因為Intel憑藉海量生產能力買處理器送內置GPU的策略徹底破產。從2009年開始,AMD被迫不斷收縮,將中端以上處理器市場拱手相讓。究竟沒有沒比賣掉Fab和Imageon更好的求生之道?收購ATI是不是真的打開了潘多拉魔盒?至今依然爭議不斷。
2011,誤入歧途
從AMD K7開始到K10,我們都可以深刻看到Jim Keller以及其團隊從DEC Alpha帶來的大量傳承。 2008年,整個處理器行業開始廣泛討論多線程的未來究竟是CMT還是SMP/SMT,Intel毫無意外的在X86上選擇了SMP+SMT,通過超線程(SMT)、增加相同架構的處理器核心(SMP)來提升處理器的多線程處理能力。而AMD似乎從CMT上看到了彎道超車的機會。代號推土機Bulldozer的AMD Phenom繼任者拋棄了K7~K10的代號,直接以推土機、打樁機等工程機械命名。
事實上推土機並非AMD臨時起意,根據AMD內部人士透露,推土機這樣的CMT架構處理器在AMD內部已經研究許久後放棄,之所以在K10之後又拿來推向市場,除了受到同是CMT架構的SUN UtraSparc T1處理器鼓勵外,還看重了CMT處理器更小面積更低成本的優勢。
( 當時候AMD官網論壇多少人反對卻一意孤行,推出多模塊CMT推土機架構死也不該死的板廠竟然推超便宜的760G主機板但是官方有說過最低標準是8XX晶片而不是7XX晶片)
SUN UtraSparc T1
和任何其他X86處理器不同,AMD推土機架構以及後來的打樁機、挖掘機架構都採用了基於CMT理念的單處理多模塊設計。在AMD推土機內部,每2個整數執行單元才配有1個浮點處理單元,同時2個浮點單元還需共享解碼器和調度器。 AMD的理由是日常PC應用有80%的運算是整數,只有20%的運算是浮點。隨著GPU的發展,以後所有浮點運算都有可能卸載到GPU上。
2個整數單元共享1個浮點運算單元的設計,讓AMD推土機上來就宣稱自己是首個8核心桌面處理器,而在實際表現上功耗更大的推土機被4核心8線程的Core i7 2600K完全壓制。許多消費者甚至將AMD告上法庭,認為其宣稱的8核心處理器存在欺詐。理想很豐滿,現實很骨幹,同樣採用CMT架構的SUN UltraSPARC T1遭遇滑鐵盧直接導致SUN破產保護,AMD選擇的CMT道路也走進了死胡同。
“AMD是說到做到的公司。” ——AMD時任CEO Rory Read
2017,來去之間
從2007年開始,AMD就遭遇了英特爾的全面打壓。推土機選用了CMT架構更是斷送了隨後多年的反擊機會。從2007年開始,AMD已經的生存空間在迅速縮小。產品競爭力也日漸下降。 I3秒全家的場景不僅出現在段子裡,還在現實中天天上演。
當年K7是他如今的Ryzen也是他(Jim Keller)
推土機徹底失敗後,AMD找回處理器架構老將Jim Keller。 Jim Keller是CPU設計領域天神Daniel W. Dobberpuhl的嫡傳弟子,Daniel設計的DEC Alpha(ALPHA ISA)、StrongARM(ARM ISA)、PWRficient(Power ISA)處理器架構至今依然深刻的影響整個處理器行業。
1998年前Jim Keller還在DEC工作,參與設計了Alpha 21164/21264處理器,為處理器設計積累了寶貴的經驗。然後其在1998年加入了AMD,首先是小試牛刀,參與設計了K7設計,然後又主導了K8微架構的設計,而x86-64指令集和HyperTransport總線技術則是K8微架構的副產品。毫無疑問Jim Keller的設計將AMD帶到了巔峰,改變了PC CPU業界的力量對比格局。
既然已經到了巔峰,英雄需要功成身退。在99年K8設計大體完成之時,產品上市之前,Jim Keller離開了AMD,追隨Daniel W. Dobberpuhl加入SiByte 研究基於MIPS的Gbps網路接口界面,2000年SiByte 被博通(Boardcom)收購,他出任首席技術官到2004年。
隨後Daniel W. Dobberpuhl於2003年創辦PA Semi,Jim Keller在2004年加入了PA Semi,出任工程技術副總,在2008年Apple為了增強自己的芯片研發能力,花費278億美元高價收購了PA Semi這家無晶圓廠的輕資產公司,很大程度就是為了收購以Daniel W. Dobberpuhl、Jim Keller為核心的研發團隊。
Jim Keller和他的設計團隊也不負眾望,為Apple設計了A4/A5 SoC,讓Apple擺脫了對三星蜂鳥處理器的依賴。 Jim Keller團隊在設計A4/A5 SoC的同時順帶將處理器從標準ARM Cortex A8微架構遷移到Apple自主微架構SWIFT,使其在擁有更好的性能/能效比。雖然iPhone成功的核心是卓絕的工業設計、交互設計和生態,但Daniel W. Dobberpuhl和Jim Keller主導的SoC也是立下了汗馬功勞。
2012年,Jim Keller毅然離開了收入頗豐的Apple,又再次回到老東家AMD的懷抱。他就像AMD的救世英雄一樣,擔負起全新微架構處理器的開發,這個全新架構就是Zen,除了Zen,Jim Keller還主導了AMD的ARM64架構K12的開發。
2016 年初,Zen的架構已經基本定型,Jim Keller就如一個打完胜仗的將軍,再次隱退,從AMD離職,加入Tesla,出任自動駕駛硬件部門的工程副總,在全新的領域開始自己新的征途。 Zen的後續掃尾工作則交給了CTO Mark Papermaster(紙面大師……)
Ryzen(ZEN)的誕生我們不能僅僅記得領袖Jim Keller,還有更多基層的Staff,如左前的Mike Clark, 團隊Leader Suzanne Plummer,後排從左到右依次是Teja Singh, Lyndal Curry, Mike Tuuk, Farhan Rahman, Andy Halliday, Matt Crum, Mike Bates 和Joshua Bell,他們的工作也同樣值得尊敬和讚美。
“隨著我們步入2017年,AMD做好了充分準備,在未來十多年中,將按時推出最強的高性能計算和圖形產品組合。”——現任AMD CEO Lisa Su蘇姿豐
現任AMD CEO Lisa Su蘇姿豐
禪,萬物的平衡
所謂的微架構(microarchitecture),是指 CPU 或者芯片中算術、邏輯、數據傳輸等單元的設計,相較而言,大家時常提起的架構在計算機科學中其實是指指令集(ISA)。微架構和硬件(具體的物理設計、封裝技術等)是架構實現的兩個 層面)——例如 x86 是架構,Zen 是支持當前 x86 指令集及擴展指令的微架構,RYZEN 是 Zen 的硬件實現。
按照AMD 的資料,Zen 最大的變化是摒棄了Bulldozer 引入的CMT(集簇式多線程),轉而採用Intel 的SMT 多線程技術,如果你經歷過當年的K8 vs P4 之爭,相信在看到Zen 的時候或多或少都有點時光錯亂的感覺。
CMT 並非 AMD 獨創,更早之前由 Sun (後被 Oracle 收購)推出的 UltraSPARC T 系列(代號 Niagara 或者說尼亞加拉),就是 CMT 處理器。它的單核性能非常弱(2007 年發布的UltraSparc T2 在單核性能上只是相當於90 年代早期的水平),CMT 玩的套路就是想憑藉大量低耗電弱核的弱核來和傳統強核處理器抗衡。
Sun 的T 系列從設計伊始就是完全衝著低功耗服務器而來,主打多內核、大吞吐、高周邊集成,而AMD 的主要市場還是在桌面上,Bulldozer 的設計理念並不符合桌面市場的應用需求,加上一系列的產品實現失誤,Bulldozer 及其衍生產品是碰了一鼻子灰,導致AMD 不僅喪失了桌面市場連帶服務器市場也統統淪陷。
Bulldozer 系列的失敗是多方面(例如包括cache 速度、耗電等具體的產品實現、周邊配套、產品策略、軟件生態等)的,但是CMT 被認為是最大問題所在,最後AMD 還為此被人告上法院說其有詐騙之嫌。
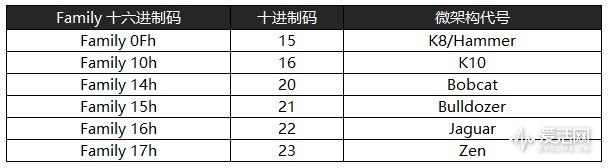
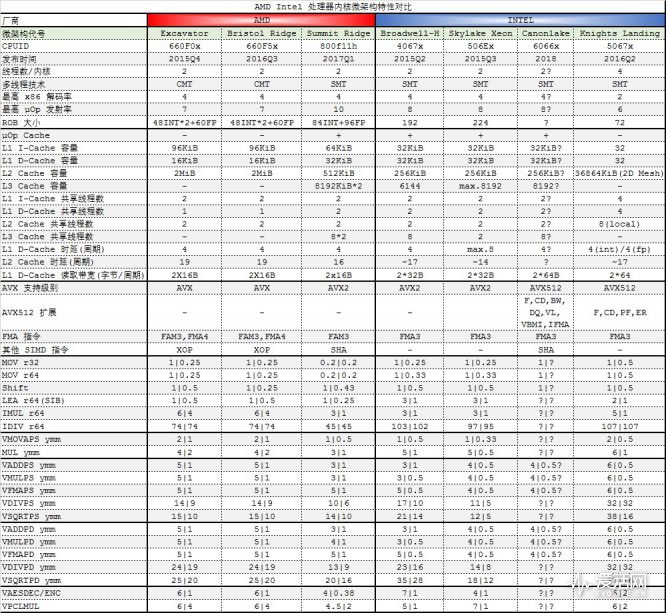
下面先讓我們看看過去10 年裡AMD 處理器的微架構簡圖(簡圖就是指減少了部分單元的繪製,因此並非100% 精確,例如分支預測單元在Bulldozer、Steamroller 以及Zen 裡都是脫耦式設計,也就是和L1 指令高速緩存並不直接相連),透過這幾張圖我們可以大致了解Zen 的變化。
AMD 的Bulldozer(推土機,2011 年) 屬於K10 微架構的接替者,它衍生了三個後續的微架構,分別是Piledriver(打樁機,2012 年)、Steamroller(蒸汽壓路機,2014 年)、Excavator(挖掘機,2015 年)。
Bulldozer 以及其後的三個衍生微架構同屬於AMD 的Family 15h 系列,其中Bulldozer 系列的CPUID 型號編碼為00h-01h,Piledriver 系列是02h 和10h-1Fh,Steamroller 系列是30h-3Fh,Excavator 系列有60h -6Fh 以及70h-7Fh。
Bulldozer 和 Piledriver 的微架構基本相同,後者主要是增強了指令集的支持以及個別單元的增強;而 Steamroller 則是 Bulldozer 的真正改進版,例如:
Steemroller CMT 模塊內有兩個 4 路 x86 解碼器,解碼器不再共享以提高單線程性能;
Steamroller 在解碼器後引入了loop buffer(循環緩存器),裡面存放已解碼的循環微操作可跨過解碼器,只要循環內的指令不超過4 條,Steamroller 就可以在一個週期內完成一次迭代,不過這樣的技術在Intel 2004 年代號Dothan 的微架構版Pentium M 上已經引入;
整數指令調度器的條目數(或者說項數)從 Bulldozer 的 40 條微操作增加到 48 條(浮點指令調度器維持在 60 條),可提升亂序執行的可調度微操作數量;
由於減少了浮點單元,因此 Steamroller 犧牲了一些浮點吞吐性能。
相較之下,Zen 微架構採用了SMT 多線程技術,每個內核都有完全獨立的資源(例如L1/L2 高速緩存、分支預測器、微操作高速緩存、浮點單元等),在擁有比K8/K10 更多的資源情況下,SMT 技術可以確保有效使用這些資源,下面這個簡表反映了Zen 微架構的主要改進點。
Zen 這個名字直譯過來就是“禪”,據聞是由AMD 的高級院士及領銜架構師Michael Clark 選定,其內在含義是微處理器中萬物的平衡:晶體管配置/管芯面積、時鐘/頻率約束、電力約束、新指令等諸多因素的平衡實現。
無獨有偶的是,華碩公司也有採用 Zen 來命名的產品,例如 ZenBook,同樣是取“優雅平衡”之意。
在內核方面,Zen 引入了 µOp Cache(微操作高速緩存),該模塊可以有效提升大多數指令流性能並且繞過潛在的大量重複性長周期操作。更大的微操作派發、更大的結果回退、更大的調度器、更好的分支預測,使得 Zen 可以維持更持久的高吞吐率並以最高效的序列實現亂序執行。 Zen 引入的硬件雙線程以及能讓功能單元保持充分利用的全序列化同樣會提升多線程應用的性能。
在高速緩存方面,Zen 擁有更快的預拾取器,確保線程可以高速緩存中獲得所需的數據。 Bulldozer 時代最被詬病的問題就是高速緩存子系統,這次 AMD 表示 Zen 的 L1-L2 Cache 帶寬提升了一倍,L3 則是提升至 5 倍。
AMD 在2015 年推出了基於Excavator 微架構的Carrizo APU,該處理器採用了大量激進的節電措施,Zen 也引入了這樣的節電措施甚至在更多的供電平面上採用,例如其中的前端(拾取、解碼等工位)以及後端都能按需實現門控,例如µOp Cache、棧操作引擎、傳送指令消除(透過調整指向寄存器的指針而非以往那樣透過高耗電的調度器執行Move 指令)。
上圖是 WikiChip 提供的 Zen 微架構細節圖,基本上是按照 AMD 在 2016 年第 28 屆 Hotchips 技術大會上公佈的資料繪製,類似的版本還有後藤弘茂在 pcwatch 上繪製的版本。
從上圖可以看出,Zen 採用的分支預測器和Bulldozer 類似,採用脫耦式設計(分支預測器與指令高速緩存沒有直接鏈接),它的每個BTB(分支目標緩存,存放著一條分支之後下一條指令的預測地址,讓CPU 可以在無需進行計算跳轉地址的情況下知道要跳轉的地址,直接執行載入指令,簡單來說就是為了減少分支預測失誤導致的性能懲罰。不過如果出錯的話,BTB 會被刷新,所有的指令都被清空,重新執行載入操作)條目存放有兩個分支,但是具體多少條目目前尚未有公開的資料。
可以參考的是,Bulldozer 的 L1 BTB 具備 128 組 4 路條目,合計 512 條目;L2 BTB Bulldozer 是 1024 組 5 路條目,合計 5120 個條目,至於 Steamroller 的 L2 BTB 被認為合計大約 10240 個條目。當然,Zen 現在是每個內核都有自己的分支預測器,而上一代則是兩個內核共享一個預測器。
Zen 的指令調度器採用整數、浮點分離式設計,這是K7 以來就一直秉承的風格(AMD K6 以及現在的Intel 處理器是整數浮點都是同一個調度器),其中整數調度器的指令或者說微操作數重排序緩存(I-ROB)有6*14 = 84 個條目(Steamroller 是48 個,Bulldozer 是40 個),重命名寄存器規模是168 個;浮點調度器的重排序緩存也從Steamroller 的60 個增加到96 個。
Zen 可以每個週期實現 8 個運算結果返回或者說寫回,達到 Steamroller 的兩倍。
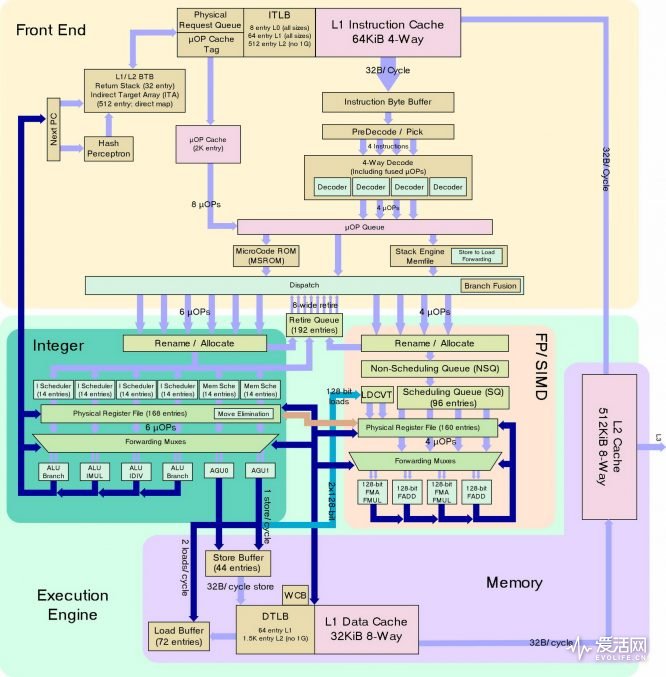
Zen 微架構探究——前端(Front-End)
對現在的CPU 來說,所謂的前端(front-end)就是指流水線中取指(fetch)、解碼(decode)、分發(dispatch)三個階段,其中取指包含的單元一般有L1 指令高速緩存、TLB(轉址旁路緩存器)、分支預測器等。
取指
前面提到Zen 採用脫耦式的分支預測器,預測器並不直接掛到代碼或者說指令高速緩存,這樣的好處是可以對即將到來的指令指針進行推測將其存放到一個隊列中,同時也能嗅探出直接和間接目標。
前面提到,AMD 並未透露Zen 的分支目標緩存(BTB)大小,只是說它屬於大BTB,每個條目可存放兩個分支。
分支預測器中的轉址旁路緩存(TLB)會存放最近的物理與虛擬內存地址的轉譯,用來就縮短載入時延,Zen 的TLB 分為指令TLB(ITLB,見上圖)和數據TLB(DTLB,稍後會介紹)。
指令TLB 採用了三級層次,其中8 條目的L0 以及64 條目L1 支持任意頁面大小,而512 條目的L2 TLB 就支持4KiB 和25KiB 大小的頁面但是不支持1GiB 的頁面。
TLB 對性能的影響不容小覷,當年AMD Phenom 的B2 版本存在一個TLB 瑕疵,為此AMD 弄了個軟件補丁來修復這個問題,但是性能會下降10% 到30%,直到後來B3 版才徹底修正了這個問題。
在取指階段時,如果指令是最近被使用過的,就會配上一個微標籤並由微操作高速緩存(µOp-Cache)設定,否則的話,該指令會被放置在指令高速緩存中以備下一步的解碼處理。
其他指令需要透過L/S 單元放置以便在接下來的周期執行,L1 指令高速緩存可以以每個週期32 個字節的帶寬從L2 高速緩存獲得這些指令。
解碼及分發
指令高速緩存接下來會將代碼發送至解碼器,後者最快可以實現每個週期四條x86 指令的解碼。解碼器可以在快速路徑裡將微操作進行融合處理,如此一來雖然傳輸到微操作隊列(µOp Queue)裡是一條微操作但是實際上可能是兩條指令組合而成,但是這些微操作會在抵達調度器後,重新拆開成兩條微操作。這樣的目的是讓微操作隊列可以塞更多的微操作從而盡可能提高吞吐能力。
棧引擎(Stack Engine)位於微操作隊列和分發器(Dispatch)之間,對於像push、pop 等棧操作,棧引擎可以在知道上一個週期的地址,就以低耗電的方式生成地址,讓系統節省掉AGU 計算地址和往返高速緩存的電力。
Zen 的分發器可以實現最高每個週期6 個微操作的派發,其中給整數調度器是每週期6 條,給浮點調度器是每週期4 條,整數操作和浮點操作可以在同一個週期裡進行派發以實現派發吞吐率最大化。
Zen 內部用於µOp-Cache 的操作碼非常緊湊,在大多數的情況下和x86 操作相當,這意味著µOp-Cache 的空間可以被充分利用。
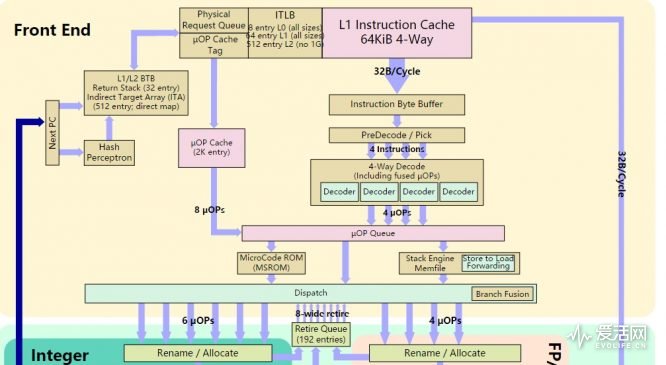
Zen 微架構探究——後端(Back-End)
處理器的後端包括了調度與執行、載入/存儲等模塊,和英特爾的設計不同,Zen 或者說AMD 自K7 以來處理器的整數和浮點執行資源是分離式的,有各自獨立的調度器和執行流水線。
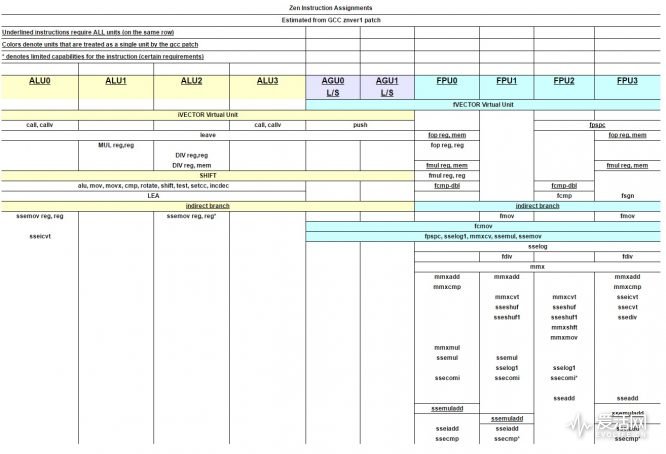
下圖所示是根據AMD 提交的GCC 補丁信息而推測的Zen 各個執行端口指令執行能力圖:
現在的亂序執行處理器會在解碼器和執行單元之間設置一個重排序緩存(ROB),可以讓指令亂序執行,然後依照程序原有的順序遞交計算結果,在寫結果的時候,指令的結果會暫時存放在ROB 裡,之後指令執行的結果再被存儲到寄存器或者係統內存中,如果其他指令急切需要該結果,那麼ROB 就可以直接為其傳輸所需的數據。
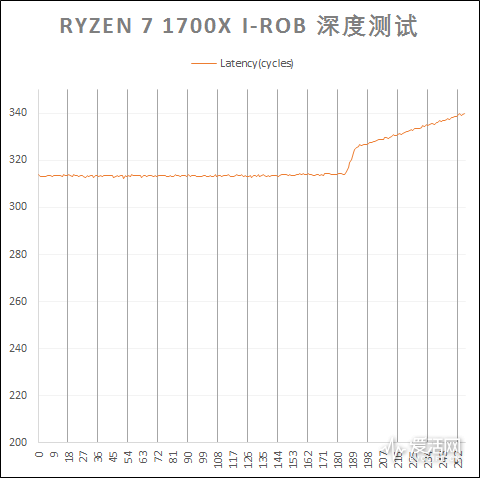
我們對Zen 和KabyLake 的ROB 進行了測試:
從測試結果來看,Intel KabyLake 的ROB 時延要比Zen 快差不多100 個週期,而在容量上兩者的測試結果符合官方的資料(Zen:180 條目,KabyLake:224 條目)。
整數單元
其中整數執行具有一個168 條目的物理寄存器堆,可以提供給4 個算術邏輯單元及兩個地址生成單元使用(例如重命名),這樣可以讓Zen 的內核每個週期進行6 個微操作的發射調度,每個整數執行端口具有自己的14 個條目的調度深度。作為對比,Intel 的KabyLake 整數物理寄存器堆大小是180 個。
四個算術邏輯單元中只有兩個可以跑分支指令,另兩個中的一個可以跑IMUL(帶符號乘法)操作、一個指令能跑CRC 操作,不過4 個整數執行流水線的具體差別需要待AMD 的優化指南或者類似資料出來後才能確定。
Zen 還包含了可以用來追踪分支指令的差分檢查點以及傳輸消除和冗餘值消除等增強特性。
浮點單元
Zen 的浮點單元可以每個週期從分發單元獲得4 個微操作,擁有160 個物理浮點寄存器堆(英特爾的Skylake/KabyLake 的向量寄存器堆有168 個)。
在浮點微操作抵達調度隊列之前,會先抵達Non-Scheduling Queue(NSQ),這個NSQ 是一個等待緩存。這是因為浮點指令通常需要較長的時延,因此在分發單元的時候就會有一堆待命的微操作。NSQ 會嘗試透過浮點指令隊列化來減少這些排隊,從而讓分發器可以保持類似提供給整數流水線的分發水平。
此外,NSQ 還能提前對浮點指令內存組元進行處理,使其在抵達調度器隊列的時候就已經就緒。
Zen 的浮點引擎有一條單獨的流水線進行128 位載入操作。
浮點調度器有4 流水線(比Excavator 多一條),都可以支持128 位浮點操作,AMD 對Zen 的浮點流水線設計也是依照128 位來優化的。
SSE 系列以及AVX 1/2 都獲得了Zen 支持,其中的256 位指令是拆開成兩個128 位操作一次執行,然後重新將其融合。這樣的實現方式讓Zen 在類似操作上落後於英特爾,後者現在都有專門的256 位處理電路。Zen 還支持SHA、AES 指令,透過兩個AES 單元實現,用於改進加密性能。
內存子系統
載入/存儲單元由兩個可以同時執行L/S 指令的AGU 管理。Zen 具有和KabyLake 一樣大(72 條目)、支持亂序載入的載入隊列,而在存儲隊列方面Zen 擁有44 個條目(KabyLake 是56 條目)。
Zen 採用了分離式的TLB 數據流水線設計,數據高速緩存被填充的時候可以訪問TLB 標籤,確定數據是否可用然後發送其地址到L2 高速緩存開始提前進行預取。
Zen 可以每週期進行兩條Load 操作(每條可以處理2*16 字節)以及每週期一條Store 操作(1*16 字節)。
L1 TLB 可以支持所有頁面尺寸,深度為64 條目,L2 TLB 缺乏1GiB 頁面支持,深度為1536 條目。
Zen 擁有4 路組相聯64KiB L1 指令高速緩存以及8 路組相聯32KiB L1 數據高速緩存,兩高速緩存都能夠以32 字節/週期的帶寬從L2 高速緩存獲取指令或者數據。
Zen 每個內核有自己獨立的L2 高速緩存,大小是512 KiB,採用8 路組相聯,具有統一化(不區分指令和數據)、包容化(裡面存放有L1 高速緩存的指令和數據)、代碼私有化的設計。
Zen 的內核之間有一個共享的L3 高速緩存,L2 高速緩存可以每週期32 字節的帶寬從L3 高速緩存讀取和寫入(雙向總線,各向各週期32字節)。
同時多線程(SMT)
Zen 最大的改進就是引入了同時多線程(Simultaneous MultiThreading,SMT,也有人翻譯作同步多線程)支持,該技術類似於Intel 15 年前首次在NetBurst 微架構體系的Xeon 所引入的Hyperthreading(原代號是Jackson)技術。從技術角度而言,Zen 是一個正確的SMT 處理器,各個內核均可以全程同時執行兩個線程。
SMT 的目的是透過執行多線程實現資源的充分利用。
在單線程模式下,所有的資源都可以被該線程所使用,採用SMT 後,Zen 的內核同時有兩個線程,它會嘗試為兩個線程共享盡可能多的資源以平衡吞吐需求,並且按照軟件的需求為每個線程提供適當的單元分配。
Zen 的各個單元可以根據執行的負荷動態地切換其資源。被兩個線程競爭共享的資源(上圖紅色標記)包括有執行單元、調度器、寄存器堆、解碼器、高速緩存(包括微操作高速緩存)。
以青色標記的載入隊列、ITLB 以及DTLB 等單元同樣是競爭共享,但是需要SMT 標記,也就是說,資源(例如隊列深度)可以被兩個線程共享,但是條目值(例如地址)只能被具有指定標記的線程訪問。
以藍色標記的分支預測器以及兩個寄存器重命名/分配單元是以優先度算法來進行競爭共享的。Zen 提供了一個邏輯機制,可以讓某個線程臨時獲得比其他線程優先度更高的資源分配。例如某個線程要對分支預測器進行清空,被賦予臨時優先度的線程可以拾取到足夠再次重新開始的指令數。此外,在分發器中也有類似的邏輯機制,可以確保兩個線程具有高吞吐率以及執行單元的高使用率。
微架構實現細節對比總結
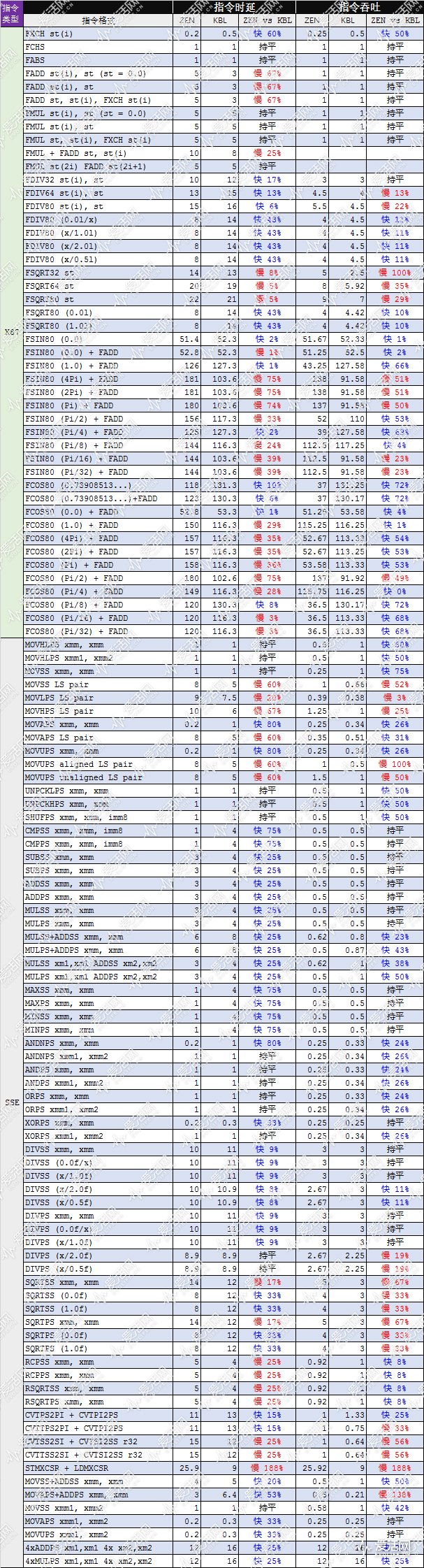
我們採用AIAD64 5.8 4072 版進行了Zen(Ryzen 7 1700X,這個微架構通常也被稱作ZenVer1)的指令時延、吞吐率測試,上表中的MOV r32 到VPCLMUL 等20 條指令就是從其中2000 多條指令中取出具有代表性的指令的測試結果,時延和吞吐率分別位於豎線的兩側,單位為周期。
時延,就是指一條指令所需的數據如果是需要等待另一條指令計算出來的,那麼這個等待的周期數就是指令的時延(latency)。例如,如果一條指令的時延是6 個週期,則意味著它需要等待另一條指令6 個週期才能獲得所需的數據。吞吐,就是指一條指令需要花多少個週期來執行。如果吞吐是3 個週期,那就意味著這條指令所需要的計算時間是3 個週期,大家平時常說的每秒多少條指令,就是用處理器的頻率除以這個指令吞吐週期數獲得的。上表中涉及到ymm 寄存器的測試都是AVX 指令,有PS 後綴的表示單精度緊縮方式,有PD 後綴表示雙精度緊縮方式。
從測試結果,我們得出以下結論:
1、Zen 的MOV 指令比Skylake 略快
2、整數除法(IDIV)指令只需要45|45 個週期,而Excavator 需要74|74,英特爾這邊的IDIV 落後不少。
3、AVX 加法、乘法、FMA 指令吞吐性能要比Skylake 慢50%。
4、AVX 除法指令和SRQT 速度不錯。
5、AES 指令比Intel 更快。
接下來,讓我們看看Zen 和KabyLake 在x87 和SSE 指令方面的時延、吞吐對比:
SSE 是遊戲中比較常用的多媒體指令,從測試結果來看,SSE 加法、乘法指令兩者相當,在有些情況下還有點優勢,是在SQRT 指令方面,Zen 要比KabyLake 慢不少。
在Pentium 4 或者說Netburst 時代,大家經常提到的一個名詞就是流水線深度,也就是流水線中細分了多少個工位,NetBurst 當時採用了20 級流水線了,相較於同期也就是10 級左右的其他處理器來說,採用這麼長的流水線可以做到快很多的頻率。
不過隨之而來的問題是,較長的流水線深度對於亂序處理器而言,在遇到分支預測失敗的時候,需要整個流水線清空,20 級流水線的分支預測懲罰一般是20 個週期。
我們使用Zen、KabyLake 以及Broadwell 進行了分支預測失誤懲罰的測試,結果如下:
上表中的左側是以偽代碼方式提供分支程序測試片段,以第7 個測試(Test 6)為例:
Test 6, N= 1, 8 br, MOVZX XOR ; if (c & mask) { REP-N(c^=v[c-256]) } REP-2(c^=v[c-260])
這段內容包含了一個MOVZX 內存載入操作指令,它需要額外的5 到6 個週期來執行,在支持亂序執行、亂序L/S 的處理器中,這個動作通常會被掩蓋掉。
從上圖中可以看到,這個Test 6 的Zen 測試結果是12.36 個週期,加上MOVZX 的5 個週期,那這個測試的有效結果17 個週期。
從測試結果我們得出以下結論:
1、Zen 的分支預測懲罰在17 到21 個週期左右,KabyLake 是16 到20 個週期,Broadwell 是15 到21 個週期。總體來說Broadwell 的分支懲罰普遍更低些,大概是15 個週期左右,KabyLake 略高,為17 個週期左右,Zen 的預測懲罰值普遍在19 個週期左右。
我們通過測試推斷 Zen 的流水線工位數應該是在19 個左右,不過由於µOp-Cache(微操作高速緩存)等因素,最低可以低至17 個週期左右。
Zen 的CPU 複合體(CPU Complex)
Zen 採用名為CPU 複合體(CPU Complex,簡稱CCX)的形式進行內核組成,每個CCX 包含有4 個內核以及一塊L3 高速緩存,L3 高速緩存的容量是8MiB,採用16 路組相聯和獨占(相對L2 高速緩存)設計。
L3 高速緩存以低序交錯地址的方式被切為4 塊,每個內核配有2MiB L3 高速緩存,內核在訪問各個L3 片塊的時候時延都是一樣的,不過Zen 的L3 採用的是犧牲式(類似於K8)。
就具體的處理器型號而言,一個8 核處理器,是由兩個CCX 結合而成。需要注意的是,在Zen 中,L3 高速緩存並非最後一級高速緩存(Last Level Cache,LLC),因為16MiB L3 高速緩存是由兩塊分離的L3 高速緩存組成,兩個CCX 之間不存在統一的L3 高速緩存,
![]()
不過AMD 表示兩個CCX 之間有專門設計的一致性線路實現CCX 以及內存控制器和周邊IO 的連接。
上圖是Zen 管芯圖中單個內核的佈局圖,它的面積是7 平方毫米,其中L2 高速緩存大約是1.5 平方毫米。圖中標註了分支預測器、指令高速緩存、解碼器、調度器、浮點單元、整數單元、載入/存取單元以及L1 數據緩存以及L2 高速緩存。
CCX 的面積是44 平方毫米,其中8MiB L3 高速緩存面積是16 平方毫米,由14 億晶體管組成。與之相比,Intel 同樣是14 納米工藝製程節點的SkyLake 內核部分(不考慮Uncore)的面積是49 平方毫米。如果這樣比較的話,Zen 四個內核的CCX 比Skylake 四內核小大約8.3%。理論上Zen 內核部分成本也會低10.2%,但是這樣的比較其實並沒有多少意義(如果說這是為了表明成本更低,但是芯片的成本絕對不是這麼簡單的事情,例如銷量,冗餘分裝等都是絲毫不亞於面積的因素,此外兩個處理器本身在功能實現上也有很大差別,例如Intel 的CPU 還支持Zen 目前尚未完全對等特性的vPro)。
上圖是Zen 處理器8 核版的管芯圖,面積大約是195 平方毫米,英特爾14 納米的Broadwell-E(包括足本的10 核版i7-6950X 以及屏蔽兩核的8 核版i7-6900K /i7-6800K 等)管芯面積是246.3 平方毫米,後者的原生內核規模是10 內核並且是4 內存通道,所以如果考慮功能特性的話, 8 核版Zen 在芯片成本潛力上並沒有特別的優勢。
1億美元分手費的背後,AMD和他的女友
在製程方面,AMD Zen 採用格羅方德(GLOBALFOUNDRIES,由於縮寫是GF,所以有網友戲稱為女朋友)的14 納米FinFET 製程生產,從線寬上而言和英特爾屬於同一代製程節點。
當然這僅僅是在線寬上,英特爾早在2015年的boardwell就已經是14nm。英特爾早期是Tick-Tock策略,交替迭代升級架構和工藝。2015年的Boardwell是升級工藝,而2016年的skylake是升級架構,繼續維持14nm工藝,但隨著晶圓廠生產線的成本大幅攀升(當然還有AMD的不給力),英特爾將Tick-Tock放緩,變成了Tick-Tock-Refresh,那麼今年的Kabylake僅僅是Refresh? 其實不然,今年的Kabylake採用全新的14FF+工藝,具體特性和性能與2年前的14nm不可同日而語。
GF的14nm和英特爾的14nm不是一個層級,AMD自己也深知,在ISSCC的PPT上其也坦誠的將Zen的工藝同競品A進行了對比,在CPP、Fin Pitch和Metal Pitch上依然差距明顯。
從這張圖看就更為明顯,英特爾的2015年的第一代14nm密度就遠遠要高於同代的三星/GF 14nm工藝。更不用說台漏電的16FF了。而Kabylake改進的14FF+雖然線寬未變,但在性能上按照英特爾的說法又有12%的提升,這樣的提升最為明顯的就是頻率的提升,7700K的睿頻頻率從6700K的4.2GHz一舉提升到4.5GHz,而超頻能力的提升僅僅是工藝提升的副產品,現在英特爾的工藝又將AMD和他的女友又再次拋離。
由於製程和英特爾還是存在差距,AMD在芯片設計上也為性能和功耗做了很多細節上的優化。AMD在RYZEN上佈置了超過1300個關鍵路徑監視器,48個片上高速電源監視器,20個熱量二極管和9個高速下落檢測器,通過這些傳感器的監測數據,RYZEN的AFVS自適應頻率電壓系統會對電壓和頻率進行快速調節,對性能和功耗進行優化。並且這樣的調節是可以針對每個核心的不同負載/溫度進行調節,更為靈活。
AMD和GF雖然已經離婚,降級成為女友,並不是一家人,但其之間的關係還是緊密異於常人。但由於Zen的誕生。AMD就開始擔心GF並不能完全滿足更為膨脹的需求。因此AMD在稍早前向GF支付了一億美元,用來修改代工協議,從原有的排他代工全部產品,改成不再獨占,使得AMD可以找其他廠商代工芯片。AMD之所以願意付出一億美元的巨大代價,也要修改這個協議,很大程度也是看好Zen的未來預期,認為GF的現有14nm產能並不能滿足Zen未來的巨大需求,究竟除了AMD現在的CPU和北極星,還要代工即將到來的VEGA和部分高通驍龍821,因此我們可以發現,AMD對於RYZEN是信心滿滿。其他第三方代工廠可能是三星半導體,究竟三星和GF在工藝和技術上有比較多的共通(都來自IBM),產能遷移比較方便。
初見ZEN 銳龍RYZEN 1700、1700X、1800X
按照AMD 的計劃,Zen 不僅用於取代Family 15h 的Bulldozer 微架構家族,而且還將取代完全針對低功耗市場的Family 16h Bobcat 微架構家族(這個系列的微架構代號都是貓科動物,最新的微架構代號是Puma 或者說美洲豹),這意味著為Zen 不僅要考慮性能提升,而且還必須將耗電問題擺在非常重要的位置,因此Zen 這個名字是充分體現了這個微架構系列的主要設計思想。
在Zen 微架構下,根據具體的內核數和集成的模塊,AMD 定下了4 個內核代號,分別是:
其中,Summit Ridge 是Zen 的第一波(3 月2 日)上市產品,商標品牌名稱為RYZEN,分別為RYZEN 7、RYZEN 5 和RYZEN 3。
服務器版本的Snowy Owl 據聞會集成Vega GPU,在今年年第二季度推出,而Naples 預期會在上半年推出,主要競爭對手是Intel 基於SkyLake-EX/EP V5 微架構的Xeon V5 服務器/工作站處理器,後者確定和英特爾第二代Xeon Phi(x200 系列,代號Knight Landing/KNL,騎士登陸灣)一樣支持桌面版Skylake 尚未支持的AVX512 擴展指令集(SkyLake-EX/EP 的AVX-512 版本是3.2 ,版本號看上去比XeonPhi x200 的3.1 更新一些,但具體的細節並不是這樣的,它們都不能支持完整的AVX512)。
針對桌面版本的RYZEN 支持AVX2,但是不支持AVX512,Naples 和Snowy Owl 可能也不會支持AVX512。AVX 指令集是英特爾在2008 年推出的x86 指令集擴展,Sandy Bridge 是首款支持AVX 的微架構,它將單指令的數據處理位寬從SSE2 的64 位提升到128 位,而後來的AVX2 更是提高到了256 位並且支持FMA 指令,RYZEN 可以支持AVX2。
RYZEN 在擴展指令集基本和相同定位的Intel SkyLake/KabyLake 相當,例如SSE、SSE2、SSSE3、SSE4.1、SSE4.2、AVX、AVX2、FMA、AES、SHA(SkyLake 不支持SHA)以及AMD 特有的SSE4A,而20 年前的3DNow! 在Bulldozer 時代已經不再支持,3DNow!是當年剛剛興起3D 遊戲時候的產物,由於不遵循IEEE754 的單精度要求,沒有獲得廣泛支持。
在操作系統方面,AMD 表示RYZEN 不再支持Windows 8 以及版本更舊的Windows 版本,畢竟是10 年前的操作系統,Windows 必須是Windows 10 以上。在Linux 方面,RYZEN 需要內核為Kernel 4.1(初步支持)或更新的版本,例如2015 年11 月發布Fedora 23(Kernel 4.2)。從指令集的角度而言,Zen 跑舊版操作系統是沒有問題的,不過由於舊版操作系統已經越來越少人使用,而硬件驅動程序的編寫又相當複雜,驗證測試耗時,因此RYZEN 放棄舊操作系統是合情合理的。
前面說了這麼多“廢”話,開始進入正題,來看看RYZEN的實物。
上面三個就是本次測試的“豬腳”,RYZEN 7處理器1700X 1800X和1700。
 創作內容
創作內容



















 不過AMD 表示兩個CCX 之間有專門設計的一致性線路實現CCX 以及內存控制器和周邊IO 的連接。
不過AMD 表示兩個CCX 之間有專門設計的一致性線路實現CCX 以及內存控制器和周邊IO 的連接。












 未分類 (3)
未分類 (3)