這比遊戲好玩,Stable Diffusion免費,
也不用擔心遊戲踩雷,什麼OOXX唇舌之戰。


---
我原始的文章寫在
不過以後文件維護會在這邊執行
先說明,如果你是初學,可能會無法理解Stable Diffusion、Noval AI與各家各式各樣的繪圖AI是什麼,到底差異在哪裡,其實你只要簡單知道怎麼用就可以。
他們無論背後技術是什麼,簡單來說,就兩種模式來產生圖片,txt2img與img2img,如其名:
txt2img就是文字轉影像,你輸入文字(一般又稱prompt)就能生圖
img2img就是影像轉影像,你給圖,他就參考圖與你能給的文字生圖
而各家AI生圖,其實用字大同小異,很像一個國家,各個世代語法不同而已,差異在於你給的 "關鍵" 用字她是否知道,這部分我後面會提供一些方法與文件。
一,文件
這邊建議各位大大一定要看文件,尤其是通用文件基本用字,用字不應該成為困擾!!,如果你連查詢與運用這些文件東西都不先搞懂,那你後面就會極為辛苦,常常要問題用字,用字其實是最簡單的真正難的是後面的創意變化與解決瑕疵。
通用的關鍵字問題
用字是最基本的,因為英文對我們是外語,所以你一定要先學會用工具,要不然你就會一直等人解答,還不一定是你想要的!!!
正面關鍵字:
泛指你希望他參考的你的意思部分
- 色色魔導書(英文字)
注意底下頁籤,請善用 ctrl + f
https://docs.google.com/spreadsheets/d/16wR5Zg_aQEbxLdrTOrB9cZf8QmsMrJnSGxFKbZVtrKc
- 咒語生成器
(1) https://aitag.top/
有圖解&個風格組合,可以自行上傳分享咒語,生成格式NoveAI,自己用notepad換字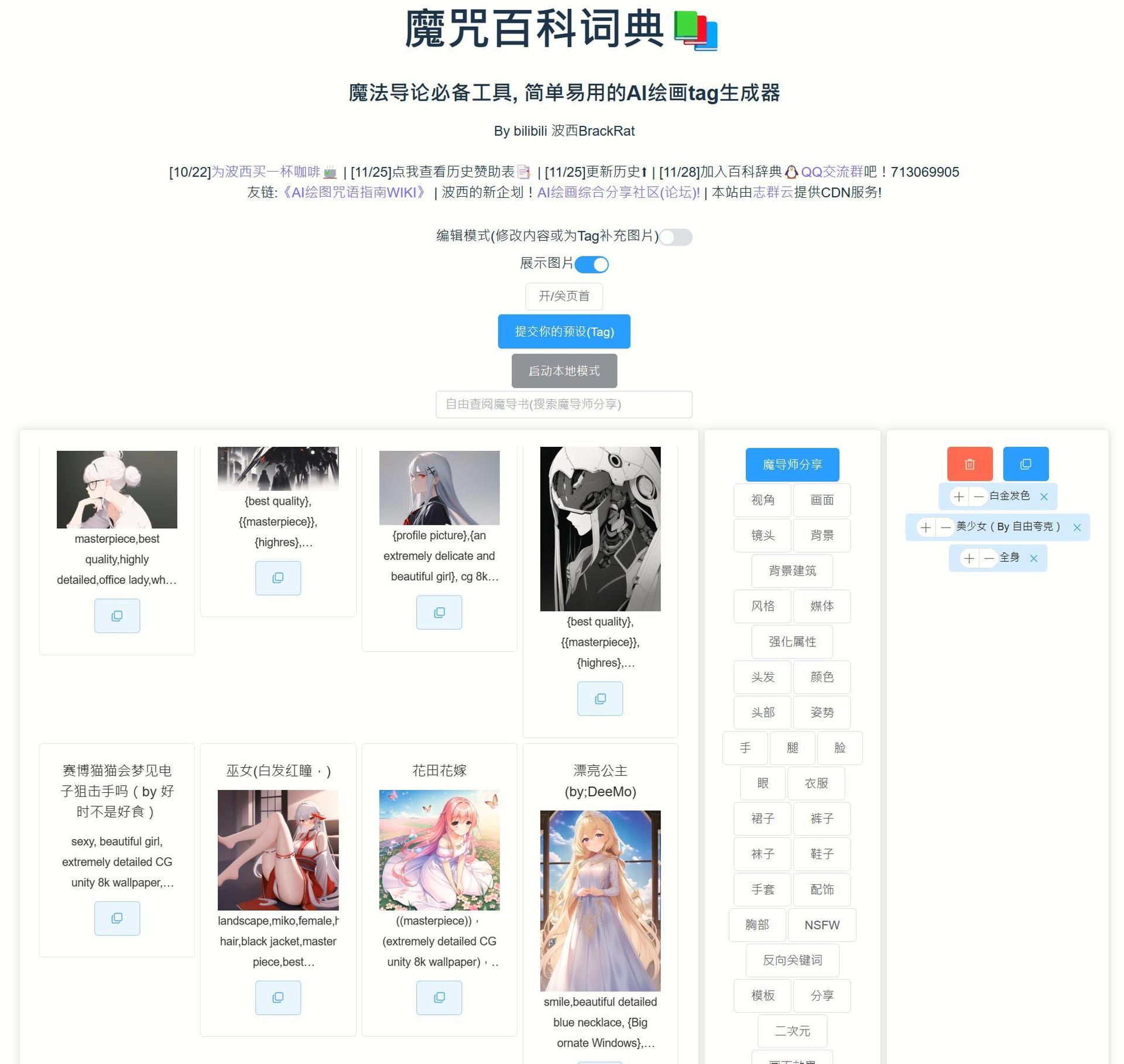
(2) https://majinai.art/zh-tw/index.php
相對於字詞組合,這更偏向查詢既有成功案例,不過這工具很直覺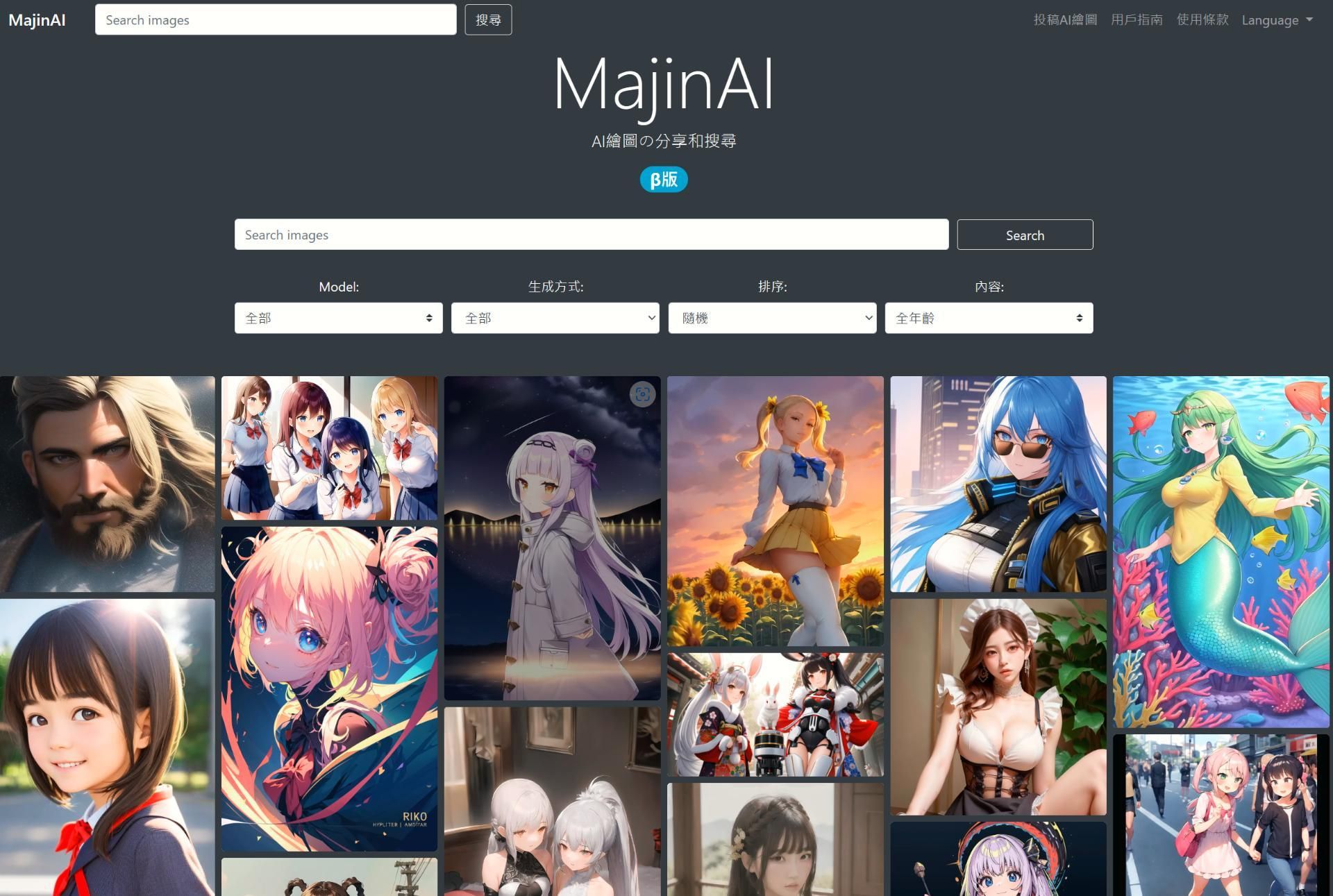
- 自動生描述文字 (by AUTOMATIC1111的SD)
這個功能在後面你學會安裝Stable diffusion (AUTOMATIC1111版本),就能操作自動產生文字,多數能用到Noval AI或其他工具上
(1) Interrogate CLIP
大多人一開始對於產生成關鍵字是不擅長。
如果你不知道怎麼輸入關鍵字,但有一張圖,可以用它內建AI解釋圖片,
精準度很高,大部分狀況她看得懂物品是什麼,他下的字,通常描述也會比你漫無目的的亂打好。可參考下圖操作
早期我靠這方式生成不少彰化吉祥物
讓AI自己形容,然後跟他說我要蘿莉的彰化吉祥物
【心得】關於彰化吉祥物用AI生成,看起來改成蘿莉也不錯
不過當時還沒有chatGPT,很多人也沒看過paper
所以大部分人並不相信AI具備理解語意或概念的功能
(2) Interrogate Deepdanbooru,自動生成tag
這個功能目前最推薦,原本有很高硬體限制,經過不斷優化,現在連低階顯卡GT1030都能執行。
其實waifu model跟NavolAI model等等,他們都有用到參考Danbooru跟類似網站的Tag,而以前就有一個github的KichangKim寫一個deepbooru的工具,他透過tensorflow訓練出能自動依圖片判斷而產生tag的AI,這套open工具已經存在一陣子,對於你完全不知道怎麼下的人很方便,而Stable Diffusion WebUI的開發者 AUTOMATIC1111,也已經整合到他的這套工具裡面。
用法:
極度簡單
web-user.bat 進行編輯,然後 COMMANDLINE_ARGS= 加入 --deepdanbooru
啟動時就會自動安裝,
進去之後你就能使用Interrogate Deepdanbooru,用法跟Interrogate CLIP一樣,自動生成對應的文字,你就不用自己亂猜字了。
其實AUTOMATIC1111提供的功能很多樣,若要認真用你能獲得很多工具建議多看他們的討論。
如果你看不懂我寫的,可以看 https://mnya.tw/cc/word/1888.html?hilite=stable+diffusion
這篇圖文並茂 - 繪圖AI資源補充
一些繪圖參考資源的補充,我會擺在這邊
https://home.gamer.com.tw/artwork.php?sn=5617043 - 使用直覺的3D工具- ControlNet
stable diffusion,其實比起prompt,看圖片進行加工的能力更強一些,
所以過去有不少會畫圖的,會使用草圖快速完成目標動作,
也有人使用3d的骨架人製作姿態,
進階一點就是用tensorflow做3d骨架辨識,
當然這些技術都不難,難在多數人看不下去程式碼,所以就不會用,
而今天ControlNet解決這套問題,直接簡單的整合到Gradio之中,方便各位使用,
可以看這篇零度解說與他影片,他是基於AUTOMATIC1111進行解說
https://www.freedidi.com/8474.html
我這裡補充一下
(1) 確保基本安裝
第一個要注意是你的python有額外裝opencv,因為他是基於opencv運作,你可以在cmd輸入:
pip install opencv-python
(2) 需要注意位置
這個影片從頭教,你如果已經有stable diffusion webui,只需要做擴充與模型的應用即可。
也就是下面兩項
https://github.com/Mikubill/sd-webui-controlnet.git
https://huggingface.co/lllyasviel/ControlNet/blob/main/models/control_sd15_openpose.pth
請注意使用 擴充 功能,--share和--listen是不允許的,須將這兩種參數拿掉。
(3) 建議全新的webui
請確保你的stable diffusion webui版本有包含 擴展插件 的功能 (若沒中文化,可以認真看零度解說影片,或看後面我介紹),如果這個功能,或者無法用,在你的資料夾下,以powershell建議進行git pull更新,若不會,建議建立全新的stable diffusion - 最後的方法
如果你都不想看任何資料只想問,問ChatGPT吧
【情報】ChatGPT能指導其他AI畫畫,也能寫程式
有很多人是靠ChatGPT + AI繪圖來完成想要的
例如
以後最可能發生的商業模式:
委託用ChatGPT + AI繪圖完成 70~80%的概念圖 → 繪師基於原圖進行美術強化或者架構修正
這是更有利於繪師直接接案,除了AI能協助你完成使用者需求確認,也排除利用溝通不良為藉口,委託者或公司從中作梗的問題,反之對於委託的消費者也是保障,因為消費者能先在電腦上達到一定程度需求,那些不太想花錢奧客當然永遠不會成為你負擔,正確使用能減少蹉跎光陰事件發生。
除了ChatGPT之外,you.com的YouChat也是能回答你問題,you.com是整合google搜尋引擎,所以你搜尋同時也會直接彈出YouChat
ChatGPT:https://chat.openai.com/
YouChat:https://you.com/
負面關鍵字:
就跟人類一樣,大腦有些部位會做負面事件的預設防範,AI如果在你沒提示下,就像失去前額葉的人一樣瘋狂產生怪異的東西,當然如果他的先天訓練就很不錯,就不太需要這些動作,這後面有機會在講。
理論上,負面關鍵字用的好,能產出更細膩而高品質的作品,他與品質有非常大的關聯,
這部分我非常簡單的只針對人去做處理,所以我用的一直非常簡單:
就是https://rentry.co/8vaaa 提供的
((nipple)), ((((ugly)))), (((duplicate))), ((morbid)), ((mutilated)), (((tranny))), (((trans))), (((trannsexual))), (hermaphrodite), [out of frame], extra fingers, mutated hands, ((poorly drawn hands)), ((poorly drawn face)), (((mutation))), (((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))), ((extra limbs)), cloned face, (((disfigured))).(((more than 2 nipples))).[[[adult]]], out of frame, ugly, extra limbs, (bad anatomy), gross proportions, (malformed limbs), ((missing arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated hands, (fused fingers), (too many fingers), (((long neck)))
如果你的生常有不一樣的目標就要自己多嘗試。
另外,你後面看文件可以多注意CFG scale(prompt參考指數)跟denoising strength(重繪指數)等等操作,他們都時時影響著你的作品,這部分就如前面說的,多看文件,後面會提供。
Stable Diffusion (完全免費,算圖工具之一)
以下針對AUTOMATIC1111版本撰寫
概念上用stable diffusion才是正道,目前市面一堆XXX Diffusion其實都互相有血緣關係,
其他收費的建議少用,畢竟這東西原本就是open source,也就是研究為主,是沒必要花錢,正確之道應該是要自己去做資料訓練。
重要概念
建議一般人看1跟2,若有興趣就看3
1. Stable Diffusion WebUI
Stable Diffusion 簡單來說,就是一個基礎運作結構,她啟動的CMD(黑色視窗)是程式主體,拜託別關掉它Orz,而webUI只是基於這結構加上去的,webUI簡單來說就是你開啟網頁輸入127.0.0.1:XXXX這段,他連到你臨時建立的server,實際上後面程式才是互動關鍵,而那個網頁說到底只是幫助你方便使用,目前最有名的就是AUTOMATIC1111。
2. 最基礎應用Model概念
model中文就是模型,有人常常說,使用了什麼model圖很不錯,通常主要是指你用的ckpt檔(依訓練方法與來源不同,可能有不同副檔名,但在這裡你只要知道ckpt即可),這是一個AI通用格式之一,AI的所有運作概念就是壓縮到這上面運作的,所以通常你下載的Stable Diffusion webUI會有資安危機,而ckpt較不可能,而網路上有些pt、bin等等檔案就是要給你訓練或額外hypernetwork等項目使用的,一切看提供者的文件,不過你至少只要知道,抓不同model的ckpt檔案就能有不同的模型可以做成圖片。
一般初次使用只要注意主要的model即可。
若你有些基礎電腦知識,
這邊講的主要model,講的是Stable Diffusion v1.4或v2.0等等,也就是預訓練(pre-training),你可以當作主要的原生核心資料庫(實際上AI不能叫資料庫,它包含推理的數學層面),通常是需要數百、甚至數千個專業GPU或者ASIC晶片去進行運算,一般公司在投資,若要立足於有個基本專長,一次性基本硬體建設最低入門檻需要200~300萬美金,設備大約只足夠應付兩三年,未來要依需要增加的,另外額外電費就是每月1萬美金上下,不過如果你要到達領導地位,一般沒有一億美金進入,幾乎沒有任何機會的,而且這金額年年上升,而產物也容易出現廢物,例如不如人品質的model,但一但出現優秀的model,就是有機會改變世界,若要形容,是個方便非常暴力的產業,當然你不用擔心使用會怎樣,因為你會慢慢知道這些model後面還有很多技術秘密你是無法取得的,而他們丟出model通常是秀肌肉打廣告,此外也是在養其他依賴你model的小公司產業鏈,再者放著也是會過時,對於大公司而言,釋出並非壞事。
對於拿不出2~300萬美金的小公司,一般採用的策略比較傾向再造與服務業,當然缺點就是容易受人牽制,但不代表沒有生存空間。
對於拿不出2~300萬美金的小公司,一般採用的策略比較傾向再造與服務業,當然缺點就是容易受人牽制,但不代表沒有生存空間。
一般人能做的就是所謂微調(fine-tuning),
提供個概念,fine-tuning會依照你使用的模型方法而有品質與速度上差異,若以Waifu Diffusion現有的討論,他們使用Anifusion模型方法生成,並基於sd v1.4模型做微調,3090連續運作40 GPU-days才出現可用圖片,而後花了快兩個月慢慢調整才慢慢能穩定使用。
但最近新出來基於PEFT的RoLa模型方法也適用於微調,這些製作模型就快很多,並且也根本不需要3090,只需GTX1070即可完成。
而未來還有更多方法在發展,這速度會非常快。
3. 額外Model知識,Embedding、Hypernetworks 與 Checkpoint
這部分初期你可以不用理他,
這裡是微調(fine-tuning)完整補充,又有人稱做小模型。
其實他跟前面講的ckpt一樣,都是model,是透過訓練而成的,主要目的也是生成圖片。
你要怎麼認知這件事呢?
你要怎麼認知這件事呢?
若以擬人化來形容,大家都有上學過,上學是基本知識的訓練,而各家學校訓練不同(waifu、NovalAI或anything v30等等),出來的最基本的model擅長的推理也就不同,
Hypernetwork就像是補習,以原生基礎改變與延伸,若你基礎不好也是沒意義的,
Hypernetwork就像是補習,以原生基礎改變與延伸,若你基礎不好也是沒意義的,
Embedding就好比自學加強某項專長,並訓練到一個程度,但他技術會有範圍限制的,
Checkpoint額外訓練(不是指原本主model),就好比你就學時額外上了其他學校或雙修,最終你在工作時,會選擇使用基礎技能的比例。
以下三個功能AUTOMATIC1111的Stable Diffusion已經內建,不過使用表現不一定如自己做的好。
(1) Embedding 嵌入:
主要針對特定細節與畫風進行改變,例如僅用一個prompt就能完整描述某個作家風格、某個角色。
通常以pt檔存放,他能會幫model找到特定提示目標,然後生成以embedding訓練數據相似的圖像。原本model保持不變時,你只能得到model已經能夠做到的東西,不過使用embedding後,你能透過一個 “關鍵字(prompt keyword)”,幫助原生model內部擴展為非常精確的提示。
主要針對特定細節與畫風進行改變,例如僅用一個prompt就能完整描述某個作家風格、某個角色。
通常以pt檔存放,他能會幫model找到特定提示目標,然後生成以embedding訓練數據相似的圖像。原本model保持不變時,你只能得到model已經能夠做到的東西,不過使用embedding後,你能透過一個 “關鍵字(prompt keyword)”,幫助原生model內部擴展為非常精確的提示。
(2) Hypernetworks 超網絡:
主要讓整體風格與特徵做變化,引入之後,他會先以原先model畫好,再進行修改的動作。
在AUTOMATIC1111的Stable Diffusion的操作上必須使用setting進行預先設定引入目標hypernetworks,之後你的生成圖像都會有該hypernetworks的特徵。
主要讓整體風格與特徵做變化,引入之後,他會先以原先model畫好,再進行修改的動作。
在AUTOMATIC1111的Stable Diffusion的操作上必須使用setting進行預先設定引入目標hypernetworks,之後你的生成圖像都會有該hypernetworks的特徵。
通常以pt檔存放,在通過原本model渲染圖像後再處理的附加層。Hypernetworks是依照基於原本model參照新數據去做訓練而成,他是透過此 "改變" 原model做生成的方案,雖然訓練時你需要載入大model,通常建議顯卡VRAM超過12GB,但是後續產生的pt檔可以在非常小的檔案就能產生風格轉變。他的優勢和劣勢基本相同:hypernetworks引入後,能讓每張包含您的訓練數據的圖像,看起來都像您的訓練數據。當然這也是反效果,假如你訓練了特定的動漫作者風格與角色資料,不過你將會很難嘗試任何其他動漫角色,因為他僅依賴於模型已知的關鍵字,他的偏好也會非常明顯。
(3) Checkpoint 檢查點模型(通過 Dreambooth 或類似工具訓練):
主要目的是調整核心model,在畫之前就能預先做出更符合你訓練的目標。
這個訓練之後就是更換主要model的ckpt,
也因此,通常以ckpt檔保存,他思路就是直接從最基礎的部分下手,也因此他能產出更靠譜的項目,他的概念屬於知識層面的重新交織,也因此她所需的顯卡VRAM通常能到24GB以上,我們能訓練一些新的小東西為新的mode (ckpt檔),並且改變原本model中判斷的 "權重",因此這個model就能夠透過推理渲染與訓練數據更相似的圖像。例如之前noval AI就有手指的問題,大約半個月,又另一批人用了Dreambooth進行處理,從那之後新出的model很少有手指方面的問題。不過,你需要注意的是,它並不是以“覆蓋”方式處理現有數據,她不會像hypernetworks,任何動漫角色看起來都像你訓練的那款,他是能夠依照要求做調整的。
除了我上面講解之外,我發現也有人文章寫得不錯。
主要目的是調整核心model,在畫之前就能預先做出更符合你訓練的目標。
這個訓練之後就是更換主要model的ckpt,
也因此,通常以ckpt檔保存,他思路就是直接從最基礎的部分下手,也因此他能產出更靠譜的項目,他的概念屬於知識層面的重新交織,也因此她所需的顯卡VRAM通常能到24GB以上,我們能訓練一些新的小東西為新的mode (ckpt檔),並且改變原本model中判斷的 "權重",因此這個model就能夠透過推理渲染與訓練數據更相似的圖像。例如之前noval AI就有手指的問題,大約半個月,又另一批人用了Dreambooth進行處理,從那之後新出的model很少有手指方面的問題。不過,你需要注意的是,它並不是以“覆蓋”方式處理現有數據,她不會像hypernetworks,任何動漫角色看起來都像你訓練的那款,他是能夠依照要求做調整的。
除了我上面講解之外,我發現也有人文章寫得不錯。
使用方法
以下說明概念主要以AUTOMATIC1111的webUI為主,若不是我會額外說明,要不然一律主要講AUTOMATIC1111的運用
(一) 最基本的安裝
MacOS安裝
Windows安裝
- 事前準備
安裝上從頭到尾下一步即可
(1) NVIDIA CUDA安裝
AUTOMATIC1111因為主要設計給NVIDIA顯卡,雖然最近有增加MacOS運作,但2023的2月這個時間點,依我所知還沒加入Core ML,所以即便很快但非首選,而AMD與INTEL GPU皆不建議花時間研究,時間成本很高。
既然是NVIDIA顯卡,你需要確保你CUDA有安裝才能用,請至下面下載安裝
https://developer.nvidia.com/cuda-11-8-0-download-archive
(2) Python 安裝
目前AUTOMATIC1111需要使用3.10.6以上Python的版本為基礎,才能運作,若你是軟體工程師則可考慮conda安裝
https://www.python.org/downloads/release/python-3106/
這邊說明一下,機器學習就兩大組成,算法師跟軟體設計師,算法一般人摸不到,他們是AI的頂級,幾乎所有突破都得靠算法師,但是也是跛腳頂級,沒有軟體沒有任何能力驗證機會,就跟電腦永遠需要韌體設計師一樣,至於程式設計師設計的程式,目前常見是Python,雖然JAVA、C++與Golang都能用,但公司以外應該沒人摸得到,所以初期知道怎麼用Python即可,有很多開發甚至根本用不到其他程式語言,只有節省成本或者有特殊發展時才需要從Python考量移轉出去,要不然以生態來說,Python比較具備技術領先的可能,團隊合作工通也比較容易,尤其是算法師更不該浪費精力在學習程式碼字句專研而浪費時間,而是數學與訓練方法的努力,所以通常是Python最合適,大多數開發者習慣沒特殊需求就繼續用,這也是為什麼多數研究者不想花時間從CUDA過渡到ROCm,除非ROCm有絕對5~10倍的性價或者能耗差距,像apple silicon或TPU那樣變態,要不然不太可能投資時間下去。 - 推薦的安裝方法
補充:
因為不知道個別環境是怎樣設置,你的防毒會怎麼動作,因此建議使用管理者權限,後面我會分別附上圖片。
另外失敗,建議除了確認管理者身分是否正確外,就是webUI完整重裝。
安裝方法有二:
(1) AUTOMATIC1111 2023/01開始提供傻瓜安裝包:
這方法主要是協助使用者克服介面恐懼症跟一些基礎環境設定,實際上很多部分還是需要一點點程式基礎。
注意這方法僅 Windows 10且 NVIDIA only
下面網址,下載 sd.webui.zip 即可
https://github.com/AUTOMATIC1111/stable-diffusion-webui/releases/tag/v1.0.0-pre
解壓縮後如下,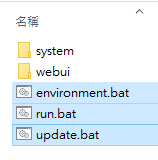
其主要功能在於增加你環境的安裝正確。
bat檔案依其內容,實際上只要開啟run.bat即可(不一定要用管理者身分),他會自動啟動environment.bat安裝好環境再執行。
如果要依序或者遇到問題,那建議以管理者身分先跑environment.bat再跑run.bat也可以,而如果你下次用,可以執行update.bat來更新程式,但不是必要。
environment.bat建議用管理員身分,方法如下。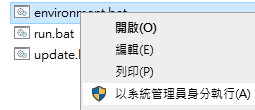
environment.bat做的動作是一些預先設定,實際上很快就完成了。
(2) 正確的安裝教學:
管理者身分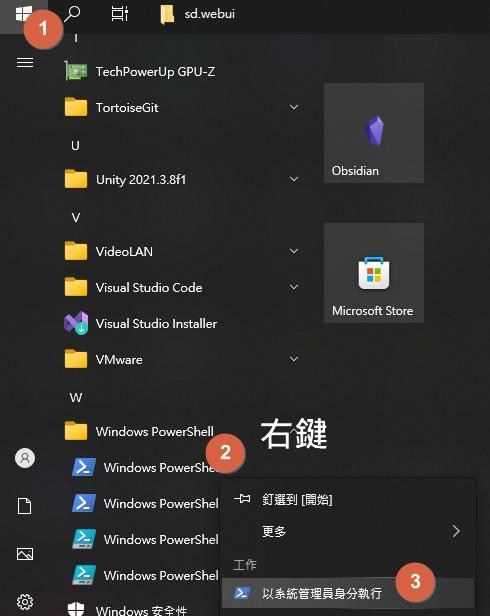
這影片的概念齊全,stable diffusion的git下載方式也是正確的,不過model下載點建議不要用中國那邊的,他們因為網路有阻擋一些東西,所以會放在他們的擺渡網站,你可以直接下載我後面提供的原版網址Model即可
另外7:43他放的hypernetworks,這部分可以多注意,其實就是其他人額外訓練的小模型 - 安裝與使用說明書
個人非常推薦
https://rentry.org/voldy
它裡面有很多重點,包含你怎麼提升品質
補充一個文件裡面,大家常常漏掉,如果你GPU不是NVIDIA,
APPLE M1可以用AUTOMATIC1111提供的文章之外,你也能一鍵安裝的DiffusionBee,
AMD要走其他方式啟動GPU協助運算,不過相對較不好做,
其中intel gpu是難以使用,
不過最終還有可以用的機會,就是走直接CPU驅動運算,你可以嘗試文件中的用法
同一張圖r5 3600大約5分鐘,而1030的3分鐘,而且CPU運算頂多吃一半性能,電力使用量則高很多,所以最差還是建議買張顯卡。
若都沒辦法,你最終還是能採用Colab去跑,後面會稍微提到。
還是還是不會用的話,世界上花錢老爺大的方法很多,其中NovalAI跟Midjourney,他們都有雲端的系統,你只要有錢跟註冊帳號,就能在上面直接用文字產生圖片。
另外中文方面,萌芽綜合天地寫得不錯
https://mnya.tw/cc/?s=stable+diffusion
個人非常推薦看他的文章
雖然比較碎片化,但多數都寫得很詳細 - 介面中文化-簡體
簡體的中文化比較簡單,也比較有維護
只要安裝git包即可: https://github.com/VinsonLaro/stable-diffusion-webui-chinese
可以看零度解說 - 介面中文化 - 繁體
中文化大約在10月就有,建議英文不擅長可以使用,但這個功能不一定是永久的,因為需要善心人維護
(1) 你需要去git下載 zh-TW.json
https://github.com/AUTOMATIC1111/stable-diffusion-webui-old-localizations
點選 Code 就能找到Download ZIP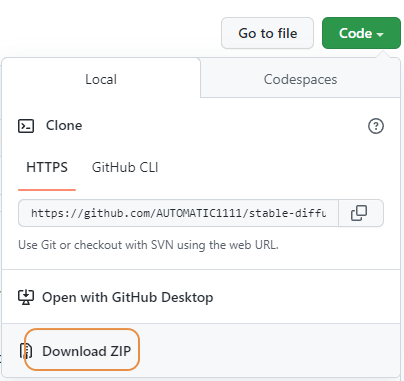
解壓縮後只拿出zh-TW.json
(2) zh-TW.json 放入 你的目錄\stable-diffusion-webui\localizations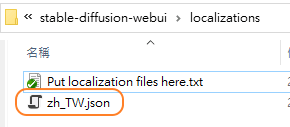
(3) 除非意外,要不然可忽略:
power shell 進行cd到 你的目錄,使用git pull進行下載更新檔,確認程式已經最新版本
(4) 啟動程式,正常能自動更新
(5) Setting > Localization (requires restart) > 選zh-TW > Save Settings > 重載入頁面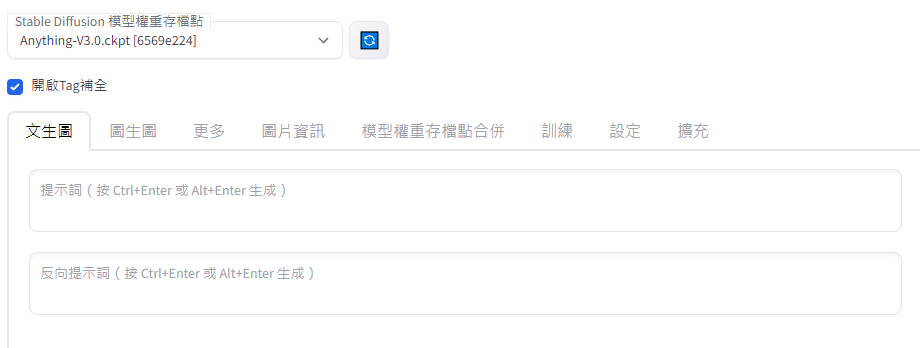
如果你有程式基礎,應該會知道這個json是可以自己維護擴充的
(二) 應看的基本文件總整理
- 安裝與各種使用不可忽略的文章(英文)
這篇文件寫得非常齊,更新也算最齊全,但初學建議看影片後,再來看它文字安裝部分補足不理解之處
https://rentry.org/voldy - 安裝與延伸使用,台灣不錯網站
如果你看不懂英文,也能看台灣有些人寫得不錯的資料,初期建議也是看安裝的部分
https://mnya.tw/cc/?s=stable+diffusion - 基本操作該知道的
如果你前面有成功按照youtube的方法安裝,
第一篇:
建議開啟介面,並看下面文件中的 "界面说明" 與 "使用说明" 對照使用一下,先有個概念,至於他的安裝使用docker,這方法不推薦使用。
https://36kr.com/p/1903272130930818
第二篇:
寫得最完整的文章,看完會對你用字很有幫助,他雖然是基於NovalAI,但有對照表你能交叉理解
https://www.zhihu.com/question/558019952 - WebUI與Model 最新資訊建議統一看 (英文)
這邊會有非常多的新資訊,包含各種資料與模型
https://cyberes.github.io/stable-diffusion-models/ - 日本人dskjal寫得不錯的文件 (日文)
不知道日文懂得人多不多,
這是少數寫得非常詳細而有規劃的,包含各種NSFW跟人物細節資料等等
http://dskjal.com/ - 其他參考文件
https://wiki.installgentoo.com/wiki/Stable_Diffusion
(三) 基本運作的架構
前面已經提供automatic1111版本的教學,不過整體簡單來分就是兩個部分,一個是運作部分,一個是模型,這邊講運作部分的基本架構,大致上分兩種,一個是視窗化,另一個是瀏覽器,整體看開發者怎麼做,不過理論上,底層都是類似的,不過視窗化通常是要做好完整整體,你可以一次就運作,但以stable diffusion的這種類型開發難度也會高一點,必須考量到各種影響。
前面已經提供automatic1111版本的教學,不過整體簡單來分就是兩個部分,一個是運作部分,一個是模型,這邊講運作部分的基本架構,大致上分兩種,一個是視窗化,另一個是瀏覽器,整體看開發者怎麼做,不過理論上,底層都是類似的,不過視窗化通常是要做好完整整體,你可以一次就運作,但以stable diffusion的這種類型開發難度也會高一點,必須考量到各種影響。
- WebUI:AUTOMATIC1111提供
目前使用最大的項目
因為大部分的人架設是用這個,遇到問題就建議看這邊的討論
https://github.com/AUTOMATIC1111/stable-diffusion-webui - WebUI: 流水線產圖ComfyUI
個人有寫一篇文章說明這東西
繪圖AI - ComfyUI 流水線生圖工具
大部分功能都漸漸能取代automate1111,不過目前automate1111插件還是比較多
- WebUI:其他
我有找到其他項目,不過用起來如何還沒時間嘗試,有時間會補充
https://github.com/sd-webui/stable-diffusion-webui
https://github.com/invoke-ai/InvokeAI
https://github.com/CompVis/stable-diffusion
https://github.com/hlky/sd-enable-textual-inversion
https://github.com/devilismyfriend/latent-diffusion
https://github.com/Hafiidz/latent-diffusion
https://github.com/AbdBarho/stable-diffusion-webui-docker - 視窗:MochiDiffusion (apple silicon ARM晶片推薦 )
介面是中文化,主要針對macOS,尤其有NPU的Apple silicon,他能採用CoreML運作,能跑出更大張的圖片,而且還滿快的
他的github網站是:
https://github.com/godly-devotion/MochiDiffusion/blob/main/README.zh-Hans.md - 視窗 : DiffusionBee
針對 macOS (如M1/M2),安裝方式是這裡面最簡單的,直接執行即可。
他使用Electron+VUE去整成一包,使用不像webUI需要碰到底層,但是反之就是可塑性低很多,不過他開放原始碼,是可以自己改造。
運作速度按照reddit討論,16GB的M1可以近似於2060 super速度,
此外,如果你的Mac是INTEL,若僅有INTEL GPU那會非常慢,
但如果是AMD GPU,按照討論,理論上他會走Mac的MPS加速,所以Mac的AMD GPU理論上能加速,黑蘋果我不確定。
有Mac,並且是M1跟AMD GPU的人可以玩玩看。
下載安裝位置 :
https://diffusionbee.com/
可以討論的空間:
https://github.com/divamgupta/diffusionbee-stable-diffusion-ui
https://www.reddit.com/r/StableDiffusion/comments/xbo3y7/oneclick_install_stable_diffusion_gui_app_for_m1/
(四) 各家基本Model
這裡需要補充注意一下,2023年之後,建議使用safetensors的命名的大模型,他能更有效的遏止惡意程式碼的執行,雖然理論上ckpt並不能做太多不正常的運作,但是只要你了解ckpt他能加載隱藏程式的能力,就很難無視,一般惡意攻擊防毒是相對僅有支援作用的存在,建議還是要務實的更新作業系統,以消除惡意攻擊的可能。
不過2022年之前,Stable diffusion相關的UI普遍還沒有支援所謂safetensors,雖然automatic1111有討論過這問題,並且有引入檢查的py,不過那是那個時期不得已,而現在大部分都有支援,因此建議一律找safetensors。
- Model:model風格查詢與下載工具 推薦
相對於rentry,下面這網址更加完整而直覺,不過這網址主要專注於ckpt,比較少理論介紹,下面途中全是AI模型生成的圖片。
https://civitai.com/
- Model:model之塔
所有model可以來這裡找,數量多到你摸不完,祝你玩得開心
https://rentry.org/sdmodels - Model:Waifu
這是最早能接觸到的模型,他的風格偏向比較細膩的人物作畫,如其名,生產waifu(老婆)為主要目的,最早打響名號的維多利亞風格油畫巨乳美女就是用waifu diffusion弄得。
下載位置
https://huggingface.co/hakurei/waifu-diffusion-v1-3/blob/main/wd-v1-3-full.ckpt - Model: Hentai
若你沒有辦法用novalai,可以考慮用這個model,是能跑出不錯的日本動漫R18圖片,詳可看4chan,看有不少人技術不錯,可以近似NovalAI一些表現,但是終究是NovalAI好用很多。
下載位置
https://huggingface.co/Deltaadams/Hentai-Diffusion/tree/8397ec1f41aeb904c9c3de8164fec8383abe0559 - Model:noval AI (簡稱NAI) 推薦
他是某個團體訓練出來的Model,原本用在Noval AI雲端的收費網站之上,後來有駭客直接到取下來分享(*Opensource的匿名者都是分享主義,既然Stable Diffusion起於Open,自然後面營利者還是要Open,要不然就會有匿名者發動攻擊),目前品質非常好,不過也可以考慮使用Anything V3.0
NovalAI模型下載方式有二
(1) BT (你可以抓到各種額外訓練資料)
https://cyberes.github.io/stable-diffusion-models/#novelai
(2) 網路載點
https://pub-2fdef7a2969f43289c42ac5ae3412fd4.r2.dev/animefull-latest.ckpt
兩個模型應該是有些差異,4.7gb應為壓縮最終版本,7.7gb應為原始版本 - Model:Anything V3.0 推薦
應該跟Noval AI屬用同樣模型往下訓練,他最大優點是五隻手指變得非常穩定
下列網址進去後,直接下載Anything-V3.0.ckpt 這個7.7GB的即可
https://huggingface.co/Linaqruf/anything-v3.0/tree/main - Model:AbyssOrangeMix2
沒有色色
https://civitai.com/models/4437/abyssorangemix2-sfw
有色色(要登入)
https://civitai.com/models/9942/abyssorangemix3-aom3
(五) 別人額外訓練模型增加作品姿色
- embedding
推薦參考embedding大樓
Stable Diffusion Textual Inversion Embeddings
(六) 自己額外訓練
建議先把基本的關鍵字玩的來去自如再來用訓練,要不然會兩頭空。
如前面所言訓練其實並沒有想像困難,主要是因為AUTOMATIC1111已經把很多功能他加到介面裡面了,只要你願意花點時間搞懂,就能訓練出自己的tag,不過內建的訓練,雖然便利不算差,但機能還是偏低,如果你要讓AI有自身的獨創性,那就要多看其他文件與方法,這邊初學就不詳寫,不過後面有推薦的youtuber,可以多看他們的教學。
內建訓練達成的效果有幾個
- 特定人或物
- 特定動作
- 特定風格
訓練目前因為有版權未定的癥結點問題,如果你只是二創或者自己娛樂,那就不用擔心,
但是商用的話,通常建議以下兩種方式使用
- 自身是繪師或者建模師,自己做特定目的的繪圖或3D model,這應該是最簡單的部分,尤其3D建模已經簡化不少,資源也非常多。通常目的是能對你的作品簡化手工的部分,尤其你手繪到一個程度,他是能讓作品維持品質與優化。
- 若你就是無法自創圖片,目的是直接生成,那關鍵是不保留圖片,並且避免擬合,
如果你是擅長自動化的工程師,你可以用自己的方法,在不保留圖片的方式下取得圖形的訓練,一般最簡單方案就是參考網路上推薦的訓練網址,讓瀏覽器自動抓圖訓練徹底刪除一次做到底,
因為說到底,目前類神經網路就跟人腦神經元運作近似,所以他們學會之後,你是不能像database或者任何壓縮檔案這樣拆解分析,ckpt僅有4GB能畫出不同風格,不是因為ckpt裡擷取了那些圖片後能做簡單剪貼,而是他能用神經元的推理模式產生對應影像,也因此你只要讓他學會之後砍掉圖片,就等於你只是讓模型在訓練時見過圖片而已。
其實還有很多花招可以自己想,例如你讓爬蟲,針對真實世界圖片做瀏覽,後面控制擷取螢幕並取得圖片後,利用OpenCV 或 第三方轉動漫的AI進行二次重繪圖片,網路上有很多重繪各風格工具,不過通常還在GAN的方法,你也能混合其他技術,諸如現在容易取得的自動2D to 3D建模等等,這種方式通常已經改變圖片風格與特徵,就算別人質疑你,但因為那些圖片都是有大幅度變動過,就算保留下來也很難反向追尋原圖。
最終你要透過數據去確認一下是否過擬合或欠擬合,過/欠擬合問題簡單來說就是AI model在訓練過程中,他學到的是錯誤的組合或者偷機取巧,例如一張圖,他就擅長某個臉與組合,你要換關鍵字產生新邏輯時,她不能換個方式畫出來,例如NovalAI就明顯有擬合問題,他不能像Dall E2這種比較訓練完善的AI,能自行腦補推理缺少的,或者產生更特別的圖片,不過這裡有個矛盾的問題點,擬合問題對於初期訓練的人可能會遇到,但有時候並非絕對壞事,所以你不得不承認他是非常便利的應用,但長遠來說,是不好的。
教學影片
如果聽不懂英文就只能看對岸講的,還不錯,最簡單作法
【【AI绘画】AI不认识人物怎么办!强大的Textual Inversion【NovelAI】】
不過通常影片是最簡單的,建議要多看一些文章,因為個別情況非常百百種,看別人經歷是最快的,而且有很多方法,要自己慢慢累積,若有空就分享,但要人解答應該是很難給你答案,這東西組合性很高,你應該要先確立好自己在用什麼,並控制好他,並不然,就是沉住性子看些文件慢慢試。
(七) 顯卡與運算選擇
1. 速度測試與加速教學
如果你是建立在自己電腦,就會有運算考量,我這邊寫得主要是基於AUTOMANTIC1111的Stable diffusion版本
我會教你怎麼樣啟動一些自己顯卡的加速:Stable Diffusion 性能測試與加速方法
除了看我後面文章,可以多看Reddit,那邊資訊很豐富
除了看我後面文章,可以多看Reddit,那邊資訊很豐富
2. 應注意事情
- DRAM:建議至少16GB以上,據說2023年1月以後已經不能用低於14GB的DRAM。
GPU與VRAM:建議1060 3GB以上(實測預設參數,prompts用cat 約21~25秒),發現3GB可以設medvram,已知1050 2GB以下都會超過1分鐘以上。
CPU:目前最低INTEL G1820都沒問題,推測任何低階CPU都可以用,只要有顯卡。 - 非所有NVIDIA顯卡都完整支援,1660~1630是FP16有問題
- 加速建議要開啟xformers
- 記憶體使用量與圖片生成大小
- Colab是個很好的雲端資源
- 已經有人採用TPU,大量生成圖片性能比起GPU快很多
- APPLE ARM晶片意外的越來越好用
分兩個方向
1. GPU運算
如StableBee
若你自己弄gradio,pytorch版本正確,開啟MPS會加速表現非常不錯,要看你運算項目,但算圖表現,M1最低階GPU大約GTX1060 ~ RTX2060顯卡性能,M1 MAX大約介於RTX 3050 ~ 3070之間變化,性價比與能耗比都非常優秀,尤其能耗比,一個15~35w晶片能算出超過100瓦顯卡的表現,算是非常不錯。
2. NPU運算
這比較麻煩,前面有介紹,MochiDiffusion,他比MPS省電而快一點,軟體還沒完善開發,以我觀點大概就是m1最低接用低電壓晶片的內顯水平接近RTX 3050,在沒風扇的情況下全程沒超過60度,所以,OK,NPU真的猛,以前看人走NPU這路子還不敢想他有多好,現在用了真的整個人都好了。
所以我更加肯定ARM在AI推理真的很猛,之前也有研究過,一些ARM開發板使用NPU的表現在學術研究上的分享,確實都很不錯的表現。 - 我是很支持AMD顯卡,作為遊戲競爭,他保持了一定競爭。但做為科學運算,目前AMD的弱項就是軟體與韌體,跟APPLE或NVIDIA的差距非常遙遠,那差距即便你花費大量時間補齊了軟體層面,他韌體還是有非常大的瑕疵,若你有AI需求,這之前的顯卡不建議急著購買AMD,我有嘗試使用過,目前調用ROCm遠遠不如使用APPLE ARM晶片MPS簡單而有效率,尤其你有開發手機AI運算時,當然,目前最簡單方案還是使用NVIDIA或者Colab。
另外Stable Diffusion是基於pytorch,所以你必須知道Pytorch在ROCm僅有Linux支援,你可以到Pytorch網站理解,實際上有趣的是,目前所有測試,MacOS還是很好用的一個選擇,畢竟他就一條路,MPS支援會慢慢跟上
https://pytorch.org/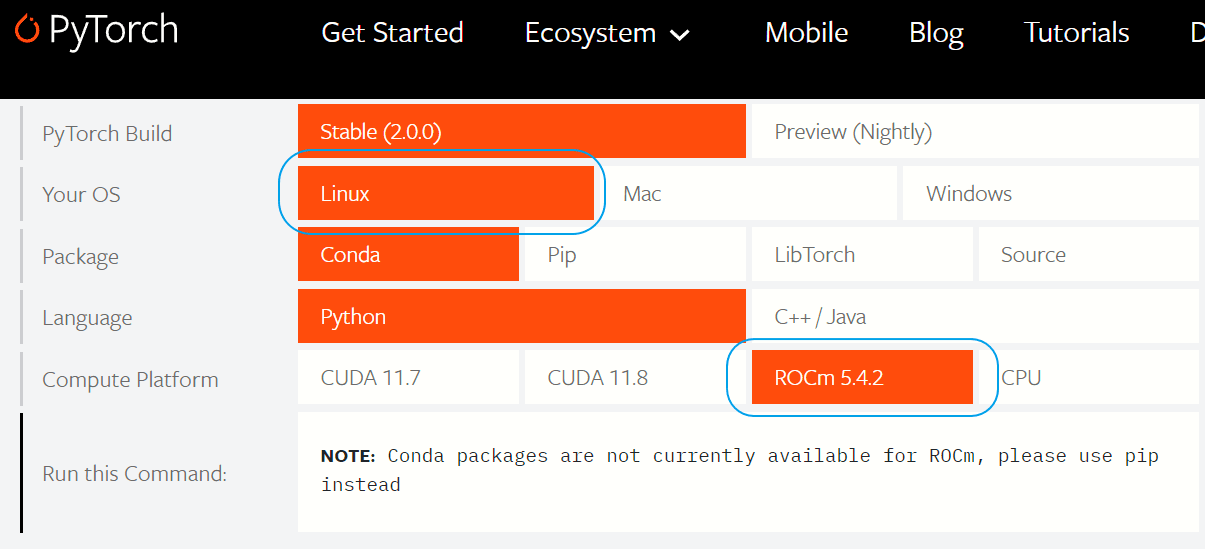
圖像ML,VRAM通常是主要瓶頸,GPU則要看你運算是否有要特殊算法,一般來說是不會考慮閹割特殊版本GPU做運算,這主要是NVIDIA會做的事情,像是1660~1630就是FP16有問題,黑圖無解,AMD因為放生GPU非常久,所以也要避免拿來做科學運算,並不是AMD性能差,反倒是AMD很多硬體基礎很好,軟體亂作一通,所以沒人用。
可以參考這篇
自己顯卡建議要開xformers
若單純生txt2img 512^2 圖片,一般2~4GB RAM足以
若要img2img 1024^2 圖片,建議6~8GB起跳
內建的訓練圖片,一般8GB就能跑,但是速度會不快,建議要12GB
但要更大張,商業使用,建議買colab pro,除了VRAM與彈性很高,主要還是他終究比你買顯卡來跑划算,尤其電費與保固方面你完全不用擔心,pro+ 的RAM大小更是你買顯卡辦不到的。
當然colab也不是完美的,他有一些限制,不過他之所以越來越常見,是因為便利性與品質都不錯,尤其開發python與運用上。
目前免費的就是提供 15GB的VRAM,只是你能調用的運算跟GPU較差
目前免費的就是提供 15GB的VRAM,只是你能調用的運算跟GPU較差
想想你的電腦要16GB VRAM得花多少錢,就會花錢用他
Colab上面執行Stable Diffusion的教學很多,例如可以看下面這篇
目前有些人已經開始嘗試使用TPU,TPU運作速度理論比起GPU更快,目前也比較不搶手,
看一些文件測試,我自己對應Colab pro使用V100,8張近似的圖我要40多秒,但他們TPU可以壓到不到6秒,不過資料不多我也沒嚴謹測試,僅供參考,不過8張圖不到6秒,完全輾壓大多數顯卡,我的3090也沒這麼快,唯一缺點是她就很單純的Stable Diffusion,WebUI可能就要你自己用Gradio架設。
相對應的引用網址
(八) custom scripts
需要基本python開發經驗會比較好用一點
其他Stable Diffusion,看各家製作看狀況,這邊講AUTOMATIC1111
這邊若要形容,就是類似Blender或者各類opensource必然會提供的 "插件" 擴充可能性,
雖然AUTOMATIC1111使用Gradio又是opensource,意味著提供你很大改造彈性,
不過如我你不喜歡進行大改造,只是希望尋求一些別人寫好的特殊插件,或者自己寫一些小程式,是能從他的Custom-Scripts去找。
主要資源可看:
相對應教學youtube很多,如果youtube沒有,reddit也能找到他們發布程式的公告,若有問題可以在reddit問
OpenAI DALL.E2(收費)
有免費額度
OpenAI這間公司在Transformer model的技術上非常突出,因為致力於免費公開技術,所以論文與一些程式非常好找。不過DALL E2多少被認為具備代表性的主因是CLIP的方法打響整個AI繪圖市場,這種自然語言(NLP)應用到與AI溝通並繪圖的手段,實際上一直都有存在,當然,不得不承認CLIP是個好方法,市面上目前常見的Diffusion程式拆開程式碼來看,多少會整合了CLIP與diffusion model的方法。
Midjourney(收費)
記憶中有免費額度
記憶中有免費額度
https://www.midjourney.com/
這個項目同樣是非常方便不擅長使用的人,主要做藝術作畫,最近也能生成日本動漫風格的人物作品,不過不能NSWF色色圖,你必須使用Discord,所以你要有Discord帳號
這個項目同樣是非常方便不擅長使用的人,主要做藝術作畫,最近也能生成日本動漫風格的人物作品,不過不能NSWF色色圖,你必須使用Discord,所以你要有Discord帳號
- 基本操作
可以看阿達的教學
https://www.kocpc.com.tw/archives/453331 - 額外技巧
主要起手式容易,讓中文可用
https://docs.google.com/spreadsheets/u/0/d/1GuAeSFtICsjQEwsRP2f--IayDxW9Dl0SCLOVov56FMc/htmlview?fs=e&s=cl# - 英文推薦文件
這文件非常方便於風格融合上的選定
https://docs.google.com/spreadsheets/d/1cm6239gw1XvvDMRtazV6txa9pnejpKkM5z24wRhhFz0/edit?fbclid=IwAR0QDSSyFfrIOvHPo4WT-G0z0t4Y6-x7AjPu0Q_71dV5DCakn58Fh2fc4JQ#gid=438712621
Noval AI (收費)
有免費額度
這個項目同樣是非常方便不擅長使用的人,並且是製作動漫R18相關的圖片,你只要在他網頁上註冊並付費就可以使用,他的調配比起你自己架設Stable diffusion簡單很多。

- 基本超做與各類使用方法
https://docs.google.com/document/d/1MtCr_Zo2xLUO2g2MuVEGlLhzx6BJUgN7ve5XGjPHR_I/edit - 據說外流的項目
(1) cyberes的BT種子
https://cyberes.github.io/stable-diffusion-models/
全世界的人都在載,下載速度倒是還不差,不過part1有點久
使用方法請服用,安裝文件:
https://github.com/AUTOMATIC1111/stable-diffusion-webui/discussions/2017
如果還是不懂就去看前面stable diffusion的youtube中文安裝教學
這文件其實與colab放的是一致,主要最大差異在於它有hypernetwork可以使用。
(2) google colab放的
https://colab.research.google.com/drive/13k72ModViWq4ftj1gSME5eSf7UDUDSU6?usp=sharing#scrollTo=NigXzayKZCsn
個人建議抓她的ckpt這個人工智慧的檔案,直接放到SD底下即可,因為colab會要求你開放google drive存取權限才能正常運作,雖然無腦,但也有隱憂,你要自行評估
目前測試,他能非常精準繪製
相對waifu記憶體也很節省,原本可能只能跑512^2,但他能上1024^2
NovalAI缺點就是他只能畫動漫最精簡的圖稿
當然你也能直接用colab跑
另外也有其他人做好的colab可以嘗試
https://colab.research.google.com/drive/1Gbzf9TEjr7yQ26lkC9NMV3G5dlzp7ICp?usp=sharing#scrollTo=kUCjBAdUndLo
實際上這些都會用到你的Drive權限,因為程式碼我們不可能全部review,安全起見,建議創一些不重要的帳號來跑
二,社群
社群媒體:
討論前建議摸熟系統,例如你是用WebUI 是AUTOMATIC1111製作的,建議要摸過一遍裡面的所有項目再去討論,建議右鍵翻譯成中文,大概正常不用半天你就知道各個頁籤在做什麼。
- Reddit,有很多很深入討論:https://www.reddit.com/r/StableDiffusion/
- Discord :
我發現邀請碼會過期,請以以下名稱尋找
(1) 場外AI繪圖討論區
(2) AI算圖研究社 - FB,討論還滿豐富的:https://www.facebook.com/groups/526007639164475/
- 巴哈,世界和平就靠 AI 了,好像還沒什麼研究,多半是分享。https://guild.gamer.com.tw/about.php?gsn=15593
- Twitter,用標籤找,例如#aiart
https://twitter.com/search?q=%23aiart&src=typed_query - Komica
https://komica2.net/
推薦youtuber:
- Olivio Sarikas
有各種使用手段與方法,推薦看他,可以省去很多手工測試的時間
https://www.youtube.com/c/OlivioSarikas/search?query=Stable%20Diffusion - Aitrepreneur
他的方法多半是比較有啟發的使用想法
https://www.youtube.com/c/Aitrepreneur/search?query=stable%20diffusion
查閱藝術家與創作:
- Pixiv
https://www.pixiv.net - Danbooru (若是動漫,強烈建議從這邊找圖片後拿你要的Tag)
https://danbooru.donmai.us - Gelbooru
https://gelbooru.com/index.php?page=comment&s=list - yande
https://yande.re/post - behoimi
http://behoimi.org/comment - konachan
https://konachan.com/ - 反查工具
http://www.iqdb.org/
https://saucenao.com/
藝術創作相關資訊網站:
- huggingface可以找到各種AI
https://huggingface.co/ - Github這年頭就算不是工程師也會知道,他有開放各種程式碼使用與討論
https://github.com/
自由軟體整合
既然他open 自然就有plugin整合優勢,在Stable Diffusion 推出短短一個月,幾乎所有自由軟體都有對應的plugin,而且實用性很高
不過plugin因為是私人開發,如果有github,建議至少1000個star再使用,而且要查閱一下他過去有沒有黑歷史,有閒有空有能力就幫他code review一次再自己package。
不過plugin因為是私人開發,如果有github,建議至少1000個star再使用,而且要查閱一下他過去有沒有黑歷史,有閒有空有能力就幫他code review一次再自己package。
- Blender
大多數看到是生成材質與UV等等
https://www.blender.org/community/
https://www.reddit.com/r/blender/search/?q=stable%20diffusion - GIMP
類似Photoshop,也是不少黑科技
目前看到是在Krita直接生成圖片的功能
https://www.reddit.com/r/GIMP/search/?q=stable%20diffusion - Krita
已經有草圖立即生完成稿的功能,不用特地上AI網站
https://krita-artists.org/search?q=stable%20diffusion
以上youtube都能看到不少人分享使用心得
三,其他生成圖片AI

四、額外補充
最近的大部分繪圖都是CLIP的Diffusion發展過來,明後年已知有更新更好的AI要推出來,所以不一定能繼續解釋,不過至少要知道現在狀況。
對Stable Diffusion的應用原理,可以看這個人說明的,稍微理解一下運作的原理,其實他還是沒講清楚組合那段,但他至少能講出生成圖片的概念與原理。
聽不懂英文,可以聽對岸,有些講得不錯,簡單有趣,也滿有依據,只是沒這麼科學
【【深度解析】AI绘画大变局!画师失业还远,但AI武器化和版权争议很近】 https://www.bilibili.com/video/BV1ed4y1g7PN/?share_source=copy_web&vd_source=7d375288444bf11f7095cfe59801b3ff
更學術一點則可以聽
【15【3分钟AI】CLIP这“脑子”是怎么长的?】 https://www.bilibili.com/video/BV16e4y127Kt/?share_source=copy_web&vd_source=7d375288444bf11f7095cfe59801b3ff
XXXX Diffusion 出現對於有些族群衝擊很大,而人類會因為情感上的因素,常常會直接批判他一波再說,例如最常見的曲解就是說Stable Diffusion不知道圖與文字之間關係,有些人甚至認為是剪貼或隨機拼湊,GAN時代確實是認知概念後,圖片靠拼湊出來,做生成對抗來修正,所以大部分人認知在這時期出現偏頗,不過CLIP搭配diffusion變化並不同於GAN,首先diffusion是DDPM衍生出來的,所以根本運作方法就不能算是GAN的方法,即便所有深度學習還有擬合問題產生的誤解,例如novalAI普遍認為就是過擬合產物,但回顧CLIP方法下的diffusion特色有兩個 1.從發展一開始就是追求讓模型能對文字產生對應概念,所以你咒語越長,只要模型能應付,他就越能搞懂你要畫的細節,2. 他繪製方式,是把隨機打散的點(或叫做noise),有辦法重新依照深度學習的基礎,一步步重新畫起來,所以更有創造爆發力,而不是剪貼,除非你訓練壞或方法不好,他就類似人類在思考方式,你說具有維多利亞風格的兔子站在梯子上,人類會從腦中隨機抓出三個概念,並且慢慢從模糊去噪形成一個清晰的圖片,這就是所有以神經元概念運作方法,都會使用類似的方法,並沒有誰比較高大尚,差別只在於認知範圍。
畫圖的AI,僅會用在繪圖,正面一點的人會拿它做點什麼做點正面事情,有這項技術,結合UE5與2D to 3D高模自動建置,你要創造自己宇宙級別的世界將不是夢
比較麻煩的還是負面的人,這種人真的很煩,他們會浪費時間糾結他能不能叫做繪圖或藝術,最糟糕的是,有些人從沒想過自己用繪圖軟體,已經做了各種輔助,你叫這群人真實拿起紙筆,能畫的好的是少數。
大家花時間、金錢與精力,如果只是做出一個隨機產生搭配的紙娃娃,如果只是photoshop都能做到的事情,那不需要這麼多人努力去發展,更何況隨機不可控是最不可能讓企業或學術掏錢繼續研究,你自己就能寫的小程式那還需要國家跟科學單位去研究麼?
而這只是剛開始,如果才剛踏出第二三步這樣就毀天滅地,那未來變化會越來越大,那要怎麼辦,對不?
目前業界認為會慢慢出現大量AI輔助自動生成的順序
1. 圖形 (含建模與影片)
2. 程式碼
3. 聲音
4. 遊戲或元宇宙的自動開發與互動
當然這東西,並不需要強迫彼此理解,時間還是會慢慢改變一些人想法,檯面上看到的也只是冰山一角,繪圖AI說破只是輔助藝術家創作的工具,你如果沒有繪圖或製作3d跟AI模型整合能力,那你會無法超越時代,你也無法做大規模創作,其實網路上大家不謀而合,都認為這類AI應用,對於未來藝術家跟工程師創建元宇宙,會越來越容易。
關於版權問題,以後慢慢增加,目前已有的版權資料我會整理在下方。


























































