昨天看了羅吉斯回歸,今天換另一個在機器學習領域也常用的模型叫SVM,它的原理其實跟羅吉斯回歸很像,也是用一條線將資料分類的概念,但是在以前跑模型的時候SVM往往比羅吉斯回歸的分數還要更高,但執行時間也更久,好那下面先用圖來講一下SVM的概念。
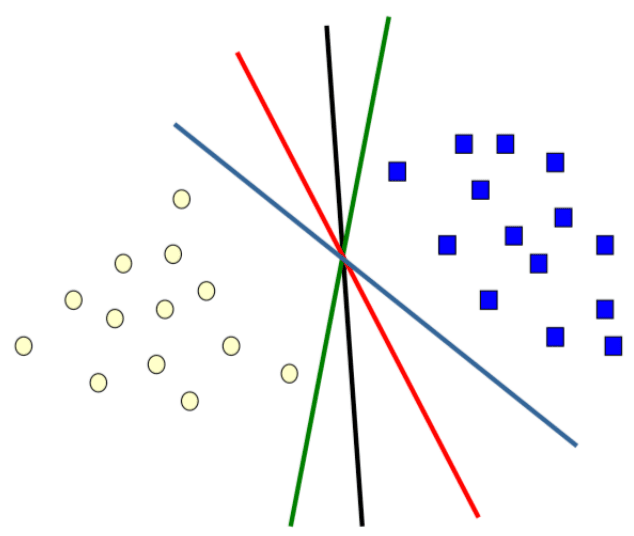
想要分類黃色跟藍色的球,可以用之前提到的羅吉斯回歸來進行分類,但是這4條線似乎都可以將黃、藍球分類出來,那應該選哪一條看起來最合理呢?
![]()
Margin指的是邊界,就是實線到虛線的垂直距離,就是離分類邊界最近的點,那一個點與分類邊緣的距離,SVM就是幫助我們找到邊界最大的那一條,能夠更加有效的區分資料,如果邊界太小,那有些微的變動就會造成影響。
SVM除了用在二維平面,也可以應用在多維度上,我們找出的那條實線叫超平面(hyperplane),超平面就是指在高維中的平面,如下圖。就能順利將藍、紅球以非線性分成兩類了。
SVM的主要目的是將有最大Margin的hyperplane之線性方程式算出來
也就是=0的那條線,那我們希望把=-1跟=1的資料落在這條線的兩側,此直線(實線)就叫分割超平面(Separating Hyperplane),此直線再往兩側延伸的兩條平行邊界(虛線)稱為支持超平面(Support Hyperplane),那兩個平行的支持超平面間的距離(Margin)越大越好。若將測試資料帶入求出的直線公式,判斷是屬於-1還是1即可。
 創作內容
創作內容









 未分類 (32)
未分類 (32)