https://www.pixiv.net/ 這是 P 網的連結
我可以直接先說 P 網的資料就是用 AJAX 請求並且更新的
當我在爬 P 網的時候,遇到的第一個問題是 : 有些資料爬不下來 ?
具體來說,一個搜尋結果共有 150 筆資料,但爬蟲可能只看得到 140 筆資料
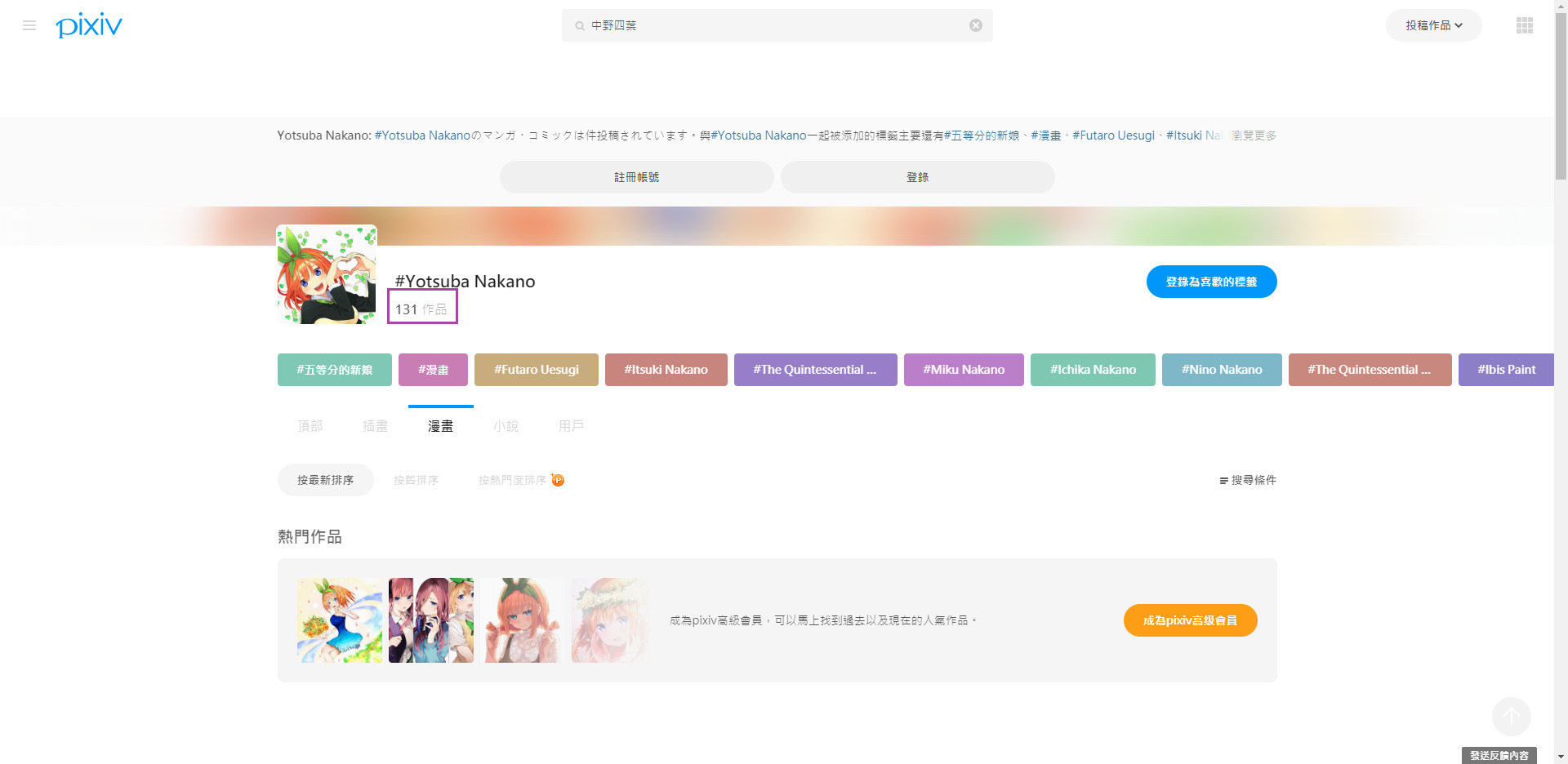
你覺得以上兩張圖有什麼不一樣 ?
首先第一張圖是未登入的,只看得到 131 份作品
第二張圖是有登入的,還有我個人化的暗色背景,看得到完整的 149 份作品
當時我靈機一動,直接把 Cookie 餵給爬蟲就能完整拿到 149 份作品了
這是爬 P 網的一個坑吧,先提早告訴大家
解決辦法有兩個,一是寫一個登入的功能,二是直接帶入 Cookie
由於登入的表單實在太麻煩了,我研究了很久真的實做不出來
上 GitHub 看別人的原始碼都是實作 App 的登入,而非 Web 版本的
這個待會會提到
在撈封包的頁面鎖定 xhr type
搜尋一個關鍵字 (我婆) 的時候,會跳出 4 個 AJAX 的請求
仔細看一下網址內的字串就知道我們要的是哪個,就是有 manga (マンガ) 的那個
我們可以得到這一個網址 :
https://www.pixiv.net/ajax/search/manga/%E4%B8%AD%E9%87%8E%E5%9B%9B%E8%91%89?word=%E4%B8%AD%E9%87%8E%E5%9B%9B%E8%91%89&order=date_d&mode=all
&p=1&s_mode=s_tag_full&type=manga&lang=zh_tw
由於網址是有被編碼過的,可以找那種 URL Decode Online 解碼一下得到 :
https://www.pixiv.net/ajax/search/manga/中野四葉?word=中野四葉&order=date_d&mode=all&p=1&s_mode=s_tag_full&type=manga&lang=zh_tw
實際上真正的網址是 :
https://www.pixiv.net/ajax/search/manga/中野四葉?
而後面那一坨都是 Query String Parameters
寫成程式碼會是 :
import json
import requests
params = {
'word' : '中野四葉',
'order' : 'date_d',
'mode' : 'all',
'p' : '1',
's_mode' : 's_tag_full',
'type' : 'manga',
'lang' : 'zh_tw'
}
response = requests.get('https://www.pixiv.net/ajax/search/manga/' + params['word'] + '?', params = params)
print(json.dumps(response.json(), sort_keys = True, indent = 4, ensure_ascii = False))
|
執行結果
當我們搜尋「中野四葉」,並且點選「漫畫」的時候
跳出的結果其實都是由 AJAX 去請求到這些資料,再替換上來的
程式碼的部分就是直接去請求這個 API,並且印出來
不過終端機畫面太小了,我們用 JSON Beautify Online 印出來看看
可以看到 data 是一個陣列,裡面就是第一頁的搜尋結果
直接去請求這個 API 就可以拿到我們要的資料了,而且 JSON 格式非常好處理
如果想要拿到第二頁的話,就是把 params 的 p 改成 2 就好
Pixiv 的搜尋一共有 5 個 Tag 分別是 : 頂部、插畫、漫畫、小說、用戶
選擇不同的 Tag,AJAX 的網址跟 Query String Parameters 會有點變化
不過只要善用撈封包的技巧查看內容,再自己微調即可
Query String Parameters 這個東西我常看到它在 AJAX 的表單中出現
它的概念就像 POST 的 Form Data,只是是放在網址裡面
但是 AJAX 表單通常是 GET 而非 POST,因為只是要向伺服器要資料而已
所以就會用 Query String Parameters 這樣的機制
就可以達到不用 POST 又可以傳送資料的方法,我的理解是這樣
總而言之 AJAX 的範例到這裡就結束了,這份 Code 只是拿來讓我做文章而已
我並不希望大家真的拿這份 Code 去使用,因為 Pixiv 的爬蟲有蠻多坑的
像光是登入頁面的表單我就處理很久,不登入又不能拿到完整資料
雖然可以靠 Cookie 處理,不過不夠優雅
如果你真的有爬 Pixiv 的需求,我建議直接上 GitHub 找別人寫的 Pixiv API 直接用
前面有提到,別人寫的都是 App 版本的登入,而不是 Web 版本
我猜可能是因為 App 版本的 API 比較好寫吧 ?
而且在框架下工作會比較輕鬆,不用自己手刻
 創作內容
創作內容













 Python 爬蟲 (34)
Python 爬蟲 (34)