請你先點擊這個連結 : http://pythonscraping.com/pages/page1.html
如果我們想要擷取整份 HTML,可以發送一個 GET 請求
但如果我們想要擷取的是片段的 HTML 怎麼辦 ? 用正則表達式暴力擷取 ?
正則表達式雖然是一個方法,但那是最後的手段
在 Python 我們可以享受好用的函式庫
今天來介紹一下這個超強 HTML Parser ,它叫 Beautiful Soup
<html>
<head>
<title>A Useful Page</title>
</head>
<body>
<h1>An Interesting Title</h1>
<div>
Lorem ipsum dolor sit amet, consectetur adipisicing ...
</div>
</body>
</html>
|
礙於版面大小,<div> 的部分文字被我刪減掉了
假設我們想要爬取 <h1> 這個節點,也就是大標題,我們就可以使用 Beautiful Soup
假設我們最終想要拿到「An Interesting Title 」這段文字,程式碼可以這樣寫
import requests
from bs4 import BeautifulSoup
response = requests.get('http://pythonscraping.com/pages/page1.html')
soup = BeautifulSoup(response.text, 'html.parser')
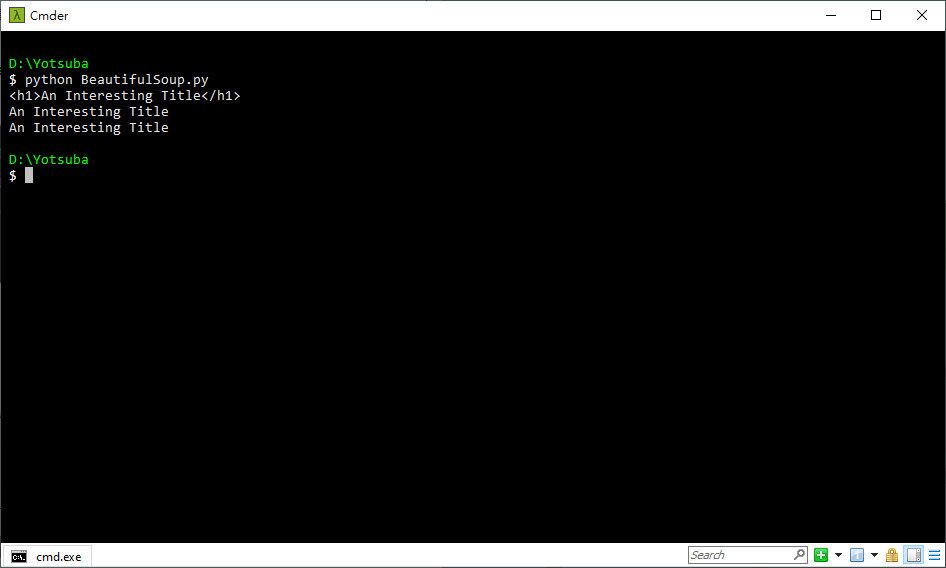
print(soup.h1)
print(soup.h1.text)
print(soup.find('h1').text)
|
執行結果
BeautifulSoup 在我撰寫文章時,最新版本是 4.x.x,所以函式庫名稱叫 bs4
使用時直接寫 from bs4 import BeautifulSoup 即可
這個函式庫還有更強大的功能,不過我單純把它當 HTML Parser 使用
所以沒有研究得太透徹,也沒有認真讀過官方文件
soup = BeautifulSoup(response.text, 'html.parser')
response.text 在這邊剛好是 HTML,第二個參數則是解析格式,參數有許多
如果填 html.parser 代表使用 Python 的 HTML Parser
其他還有像是 html5lib 的參數,專門用來解析 HTML5
或是 xml 的參數,不得不說 BeautifulSoup 真的超強,它也可以解析 xml 格式
接下來我寫了 3 個 print,我一一解釋
首先這份 HTML 裡面只有一個 <h1> 節點,所以寫 print(soup.h1) 可以直接抓到大標題
底層的行為其實是直接抓取第一個遇到的 <h1>
整個節點 print 出來就會是 <h1>An Interesting Title</h1>
第二個 print 有點變化,我寫成 print(soup.h1.text),表示只 print <h1> 裡面的文字
所以就會得到我們要的 An Interesting Title
第三個 print 我寫成 print(soup.find('h1').text),表示以 soup 去尋找第一個 <h1>
如果有找到的話就會回傳這個 <h1> 物件,然後使用 text 屬性,也順利拿到大標題了
如果 find 沒有找到會回傳空物件 (None)
乍看之下,第二種和第三種寫法差不多 ? 以這個例子來說的確差不多
但未來會遇到有 CSS 裝飾過的節點,或者有 class 屬性的節點
這時候就能利用 find 去過濾屬性,抓取我們真正想要的節點
BeautifulSoup 還有太多花俏的玩法,一時間無法全部解說完畢
可以繼續參考下一篇文章
 創作內容
創作內容








 Python 爬蟲 (34)
Python 爬蟲 (34)