主題
我覺得很幹....最幹的那種...
之前實習要爬這個網頁
還有同網頁的其他頁面,都是table
要把table爬下來
然後當然就用beautiful soup這類static webpage的爬蟲軟件,把tags都爬下來,然後再多謝幾句code讓他們對齊format
搞了我兩個星期!!!!!
其他部分沒問題,就是因爲format那些對不齊,總之就很煩
那時候心態是ok的,畢竟對爬蟲&coding不熟練,beautiful soup 基本上沒用過,而且經過不斷的嘗試,把大部分常用的code跟方法都記住了,那也算是有不少收穫
老闆那邊也不用擔心什麽,畢竟前面做的快,就這個task慢一點也沒什麽問題
然後事件過去幾天后,也就是今天
我無意中看到了這個網頁...
抱著好奇的心情點了進去
他説是static webpage的table都可以用 pd.read_html(url) 去爬下來
那就試試吧
結果...
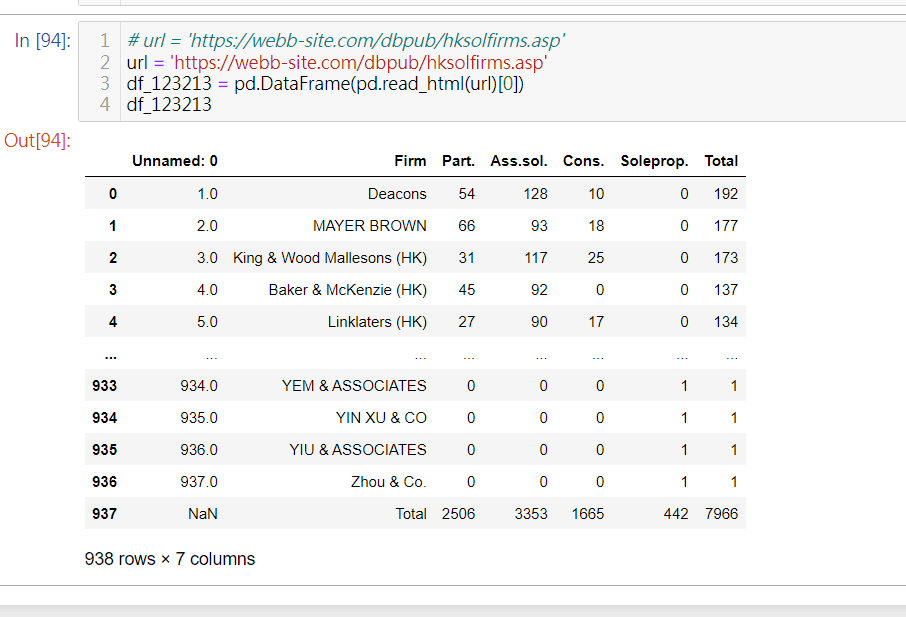
.............
.....
...
..
後來想想,其實也合理
既然excel都能scrap html tables了(只是基本上沒人用,能用的都會用code解決),那理論上python也會有這種功能才對...用bs前應該先上網查一下的QQQQ