終於邁入30天了,這個暑假過得還算充實吧
![]()
,開學後接了兩科助教加上論文、專題那些,應該是沒甚麼空更新了,不過還是會不斷學習新知的。
正如前面幾篇所說, Actor-Critic是結合Policy-based與Value-based,Actor-Critic是由兩部分所合起來的Actor跟Critic,Actor的翻譯是演員,Critic則是評論家的意思,Actor的部分是由Policy Gradient演進而來,Critic是Q-learning演進而來。也是因為policy-base的可以輕鬆地在連續動作空間内選擇合適的動作,如果是value-base的Q-learning或DQN就會當機,但是Actor的學習效率又比較慢,所以才有Actor-Critic演算法的出現,改進兩者的缺點。
由一個Critic先去學習獎懲的機制,再來Actor 基於概率選行為, Critic 基於 Actor 的行為評判行為的得分, Actor 根據 Critic 的評分修改選行為的概率,Critic 通過學習環境和獎勵之間的關係, 能看到現在所處狀態的潛在獎勵, 所以用它來指點 Actor 便能使 Actor 每一步都在更新。
Actor Critic 方法的優勢:可以進行單步更新,比傳統的Policy Gradient 要快。
Actor Critic 方法的劣勢:取決於Critic的價值判斷,但是Critic難收斂,再加上Actor的更新,就更難收斂了。
但是這樣還不夠,因為Actor-Critic牽扯到了兩個神經網絡,Actor一個,Critic一個,而且在連續的情況下學習,使得這兩者具有相關性,讓神經網絡學不到東西。所以之後又出現了一個演算法叫Deep Deterministic Policy Gradient (DDPG)由DeepMind所開發,另一個比較有名的還有A3C演算法。
30天的更新就到這告一段落了,基本上是想到什麼就更新什麼,一些以前聽過的,但不太懂的就趕快找資料、文章來補足一下,其實有時候真的想不到要更新啥
![]()
,看了半天的數學公式,還是不太好理解,所以文章內大多都是演算法的想法,因為大多數的套件都已經寫好了,要自己手刻一個還不一定比別人的好,所以懂這個演算法在做甚麼,我覺得比較重要
![]()
。
 創作內容
創作內容

 ,開學後接了兩科助教加上論文、專題那些,應該是沒甚麼空更新了,不過還是會不斷學習新知的。
,開學後接了兩科助教加上論文、專題那些,應該是沒甚麼空更新了,不過還是會不斷學習新知的。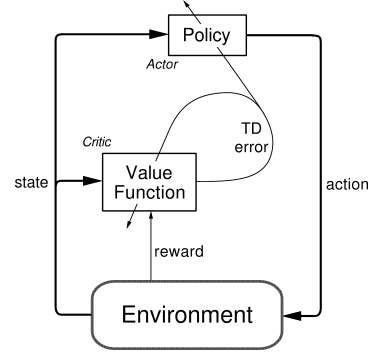
 ,看了半天的數學公式,還是不太好理解,所以文章內大多都是演算法的想法,因為大多數的套件都已經寫好了,要自己手刻一個還不一定比別人的好,所以懂這個演算法在做甚麼,我覺得比較重要
,看了半天的數學公式,還是不太好理解,所以文章內大多都是演算法的想法,因為大多數的套件都已經寫好了,要自己手刻一個還不一定比別人的好,所以懂這個演算法在做甚麼,我覺得比較重要 。
。




 未分類 (32)
未分類 (32)