因為實在是對 optimization 的各種方法不太熟
只知道最簡單的梯度下降,或是 powell 之類的
每次都只是無腦 call library
所以想說好好查一下 scipy 裡的各種方法到底是什麼原理,然後順便紀錄一下以免忘記
第一個是先挑了 Nelder-Mead
之後如果看完其他的就有空再寫一下
Nelder-Mead algorithm 是一種 Derivative-Free Optimization 方法
也就是它在求解極小值的時候是不需要梯度的
那它的概念其實蠻簡單的
假設 f = f(x) 是要求解的函數,其中 x 是個向量,維度是 N
那麼給定初始的猜測 x1 後,再額外生成 x2 ~ x(N+1)
那這 N+1 個點就構成了一個 "simplex"
Nelder-Mead 的做法就是在每一輪的迭代中,去把最差的點換掉,換成一個比較好的點
這樣一直迭代下去,最終這些 N+1 個點都會收斂到極小值處
(一個點最好或最差,指的就是離最小值較近或較遠)
那每一輪的迭代,步驟是這樣:
============================================================
1.
先把這 N+1 個點排序,使得 f(x1) < f(x2) < ... < f(x(N+1))
所以可以知道,現在最佳的點是 x1,最差的是 x(N+1)
2.
計算前 N 個點的中心
(不是全部 N+1 個點的中心,只有計算前 N 個的點中心而已)
3.
由前 N 個點的中心,以及第 N+1 個點,可以由這兩點拉出一條線
不同的 t ,就代表這條線上不同的點
之後的比較就是根據這個 reflection point 來看的
4.
接下來就是一大堆比較的過程
首先先算出 reflection point 和它對應的函數值
![]()
,
![]()
然後看這個函數值屬於哪種情況,有不同的處理方法:
case 4.1: f(x1) <= f(-1) < f(xn)
這種情況代表,reflection point 沒有比目前的 simplex 中最好的點更好、但也沒有比最差的點還要差
所以就直接把原本的點 x(N+1) 用這個 reflection point 替換掉,接著就直接進入下一輪迭代
case 4.2: f(-1) < f(x1)
因為 x1 是目前這個 simplex 中最好的點了,所以這個情況代表,reflection point 比現在最好的點還要更好
也就是代表往 reflection 這個方向走或許是對的
所以這時候就會再看看,如果往這方向再走更多,會不會更好
因此再計算 expansion point 和對應的函數值
![]()
,
![]()
然後分叉出兩種情況
case 4.2.1: f(-2) < f(-1)
這個情況代表,這個 expansion point 確實又比本來的 reflection point 更好
所以就用 expansion point 代換掉 x(N+1),接著就直接進入下一輪迭代
case 4.2.2: f(-1) >= f(xn)
這個情況代表,繼續延伸到 expansion point 反而沒有原本的 reflection point 好
所以維持用 reflection point 就好
因此拿 reflection point 取代掉 x(N+1),接著就直接進入下一輪迭代
case 4.3: f(-1) >= f(xN)
這個情況代表 reflection point 比 xN 還要差
但是還是有必要看看,有沒有差到比 x(N+1) 還差
case 4.3.1: f(xN) <= f(-1) < f(x(N+1))
表示雖然 reflection point 不是很好,但至少比 simplex 裡最差的 x(N+1) 好一點了
因此是可以稍微往 reflection 的方向走一點點的,但是不要走這麼多
所以這時候計算 "outside" contraction point 和對應的函數值
case 4.3.1.1: f(-1/2) <= f(-1)
這表示這個 "outside" contraction point 又比 reflection point 好一點
所以拿這個 "outside" contraction point 取代掉 x(N+1),接著就直接進入下一輪迭代
case 4.3.1.2:f(-1/2) > f(-1)
表示 "outside" contraction point 又比 reflection point 更差一點
那就跳到後面執行 case 4.3.s
case 4.3.2: f(-1) >= f(x(N+1))
這個情況代表 reflection point 反而是最差的,也就是原本的 x1 ~ x(N+1) 還算可以
因此採取的做法就是縮小原本這 N+1 個點所圍出來的範圍
所以這邊就去算 "inside" contraction point 和對應的函數值
case 4.3.2.1: f(1/2) < f(x(N+1))
這個情況表示 "inside" contraction point 有比原本最差的點還要好
所以拿這個 "intside" contraction point 取代掉 x(N+1),接著就直接進入下一輪迭代
case 4.3.2.2: f(1/2) >= f(x(N+1))
這個情況表示 "intside" contraction point 一樣更差,那就跳到後面執行 case 4.3.s
case 4.3.s:
當前面遇到 case 4.3.1.2 或 case 4.3.2.2 的話就會跳來這邊
這步就是直接把原本這些點往 x1 的方向壓縮
把 x2 ~ x(N+1) 用這個式子來替代
============================================================
上面這 4 個步驟就是一次迭代中會做的事情
不斷重複這 4 步驟直到收斂,就能把 x1 當作是發生極小值的點了
其中在第 4 步,case 4.1 就代表 Reflection,case 4.2 代表 Expansion,case 4.3 代表 Contraction,case 4.3.s 代表 Shrink
那可以看出這 4 種情況,其實代表的概念就是,當極小值落在這 N+1 個點構成的 simplex以外時,它要讓這 simplex 變大,且往極小值的地方伸過去。而當極小值落在 simplex 內時,它則會讓 simplex 縮小
圖上面的 xs、xl、xh 只是代表構成原本 simplex 的三個點(也就是要求解的向量是二維的,所以simplex 有三個點,構成一個三角形)
而 xr、xe、xc 代表 reflection point、expansion point、contraction point
Reflection
Expansion
"Outside" contraction
"Inside" contraction
Shrink
那前面是用 x(t) ,然後代不同的 t 來代表不同的點
不過因為會用到的 t 其實也只有 5 種,所以也可以把五個情況都列舉出來
所以這邊就把這五個情況都列出來,順便把表達的形式也稍微修改一下
Reflection point:
Expansion point:
Outside contraction point:
Inside contraction point:
![]()
Shrink:
![]()
這邊的 alpha = 1 就等同於前面的 t = -1
beta = 2 等同於前面的 t = -2
gamma = 1/2 等同於前面的 t = -1/2
delta = 1/2 等同於前面的 t = 1/2
那邊改寫成這樣的形式,可以看出 Nelder-Mead algorithm 有這主要的四個參數:alpha、beta、gamma、delta
分別代表了reflection、expansion、contraction、shrink
而 alpha = 1, beta = 2, gamma = 1/2, delta = 1/2 的組合就稱作 standard values
那當然也可以採用不同的組合
比方說在 scipy 的實作當中,是採用
這篇的作法
所以會使用 alpha = 1, beta = 1 + 2/N, gamma = 0.75 - 1/2N, delta = 1 - 1/N 這樣的組合
其中 N 就是維度大小,當 N=2 時就會跟 standard values 是一模一樣的
另外還有一個沒有提到的是
一開始有個初始的猜測 x1 後,再額外生成 x2 ~ x(N+1)
那後面 x2 ~ x(N+1) 這幾個點到底要怎麼生成?
看了一些文章大部分都是用這樣的作法:
第 i 個向量 xi,它的第 i-1 個 element = x1 的第 i 個element 乘1.05
不過如果x1 的第 i 個element 是0,那就直接令 xi 的第 i-1 個element 是 0.00025
舉個例子,假設 x1 = [1; 2; 0] (Matlab 的 column vector 表示方法)
那麼會需要生成 x2 ~ x4
分別是:x2 = [1.05; 2; 0]、x3 = [1; 2.1; 0]、x4 = [1; 2; 0.00025]
那 Nelder-Mead algorithm 的優缺點大概是這些:
優點
1. 它常常在前幾次迭代就能夠有很好的改進,很快的達到令人滿意的結果
2. 在一次的迭代中,除了 Shrink 的情況以外,Reflection、Expansion、Contraction 都只需要計算一或兩次左右的函數值。因此如果函數值的計算會花很多時間的話,這個特點很有幫助
缺點
1. 較缺乏完整的收斂理論。而且它有時候甚至在一些 smooth 的函數都沒辦法正確找到極小值
2. 有可能在非極小值的地方,進行了大量的迭代,但是每次迭代的改變量都不多
3. 在高維的情況下,這個方法的效率會較差
另外有趣的事情是
Shrink 這個步驟在實際上很少會遇到
所以大部分還是以其他三個為主
而
這篇提到了,在 uniformly convex 的情況下,Expansion 和 Contraction 這兩個步驟可以有很好的 "下降" 效果
而因為 Shrink 很少遇到(在uniformly convex 的情況下根本不會用到 Shrink),因此如果發生了很沒效率的情況,很可能是因為迭代時用了太多次了 Reflection 了,尤其如果是在高維的情況
作者畫出了這張圖
x 軸代表維度大小,y 軸代表迭代時使用了 Reflection 的比例,越高代表大部分的迭代都是使用Reflection
那可以看到當維度越來越高,Reflection 使用的比例就越高,所以也顯示了 Nelder-Mead 在高維的情況下缺乏效率的原因
而如果改採用 alpha = 1, beta = 1 + 2/N, gamma = 0.75 - 1/2N, delta = 1 - 1/N 這樣的組合
得到的結果變這樣
很明顯的看到情況改善很多了
所以可能因為這樣,scipy 的實作就採用這個方式
Reference
1. Jorge Nocedal, Stephen J. Wright: Numerical Optimization, Second Edition.
2. Nelder-Mead algorithm
3. Implementing the Nelder-Mead simplex algorithm with adaptive parameters
4. Nelder-Mead 算法
http://wuli.wiki//online/NelMea.html
5. scipy source code
https://github.com/scipy/scipy/blob/adc4f4f7bab120ccfab9383aba272954a0a12fb0/scipy/optimize/optimize.py#L456
 創作內容
創作內容
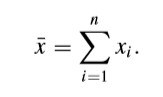

 ,
, 
 ,
, 
























 未分類 (164)
未分類 (164)