創作內容
創作內容
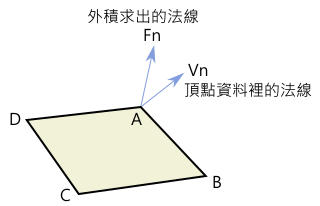
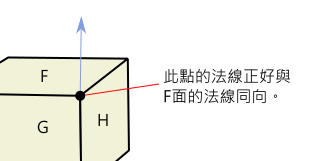
| float3 normal = cross( ddx(worldPos), ddy(worldPos) ); |
| #!/usr/bin/python3 #coding:utf-8 import sys #取得命令列參數 import os.path #使用os.path解析路徑 import math from collections import OrderedDict import struct #這兩個會在輸出PMD,PMX時用到 import array if len(sys.argv)<2: scriptName=os.path.basename(sys.argv[0]) #取得目前Python檔的名稱 print("usage:") print("%s fileName [globalScale] [offsetX] [offsetY] [offsetZ]" % (scriptName,)) print("offset will be added to each vertex coordinate before scaling") sys.exit(0) |
| D:\>objtopmd.py usage: objtopmd.py fileName [globalScale] [offsetX] [offsetY] [offsetZ] offset will be added to each vertex coordinate before scaling |
| #如果沒給命令列參數就用預設值 globalScale=1.0 globalOffset=[0,0,0] #如果參數有3個以上就設globalScale=第3參數 if len(sys.argv)>=3: globalScale=float(sys.argv[2]) #globalOffset是第4~6個參數 if len(sys.argv)>=4: for i,arg in enumerate(sys.argv[3:6]): globalOffset[i]=float(arg) |
| objFile = open(sys.argv[1],"rb") objData = objFile.read() objFile.close() #此時objData是bytearray型態 |
| class ObjFile: def __init__(self, rawData): #成員變數 #OBJ的index是從1開始,事先插入一個0可以不用每次都把index減1 self.vertexList=[0,] self.texCoordList=[0,] self.normalList=[0,] #groupDict要記錄插入的順序,所以用OrderedDict self.groupDict=OrderedDict() self.materialDict={} objLines = rawData.splitlines() nowGroup = None #目前在處理的group #還有一些其他處理,在此省略…… for line in objLines: line=line.strip() #跳過空行和註解 if len(line)==0: continue if line[0]==ord("#"): #comment continue words=line.split() |
| #Python沒有switch,只能用連續的if代替 #不然可能要用key是字串,value是函式的dict if words[0]==b"v": #位置 self.vertexList.append(makeFloatTuple(words)) elif words[0]==b"vt": #貼圖坐標 self.texCoordList.append(makeFloatTuple(words)) elif words[0]==b"vn": #法線 normal=normalize(makeFloatTuple(words)) self.normalList.append(normal) #makeFloatTuple和normalize是我自己寫的函式,不是Python內建 #把面和頂點按照material分組,因為PMD,PMX是按照material分組 elif words[0]==b"usemtl": #下一個material #檢查有沒有相同的material nowGroup=self.groupDict.get(words[1]) if nowGroup==None: nowGroup=ObjGroup(words[1]) self.groupDict[words[1]]=nowGroup elif words[0]==b"f": #面 nowGroup.addFace(words, self) #之後是其他的資料…… #mtllib、s和g不會用到,忽略 #其他method定義…… #定義好class後,建立物件 objContent=ObjFile(objData) |
| #有這些class ObjFile #整個OBJ檔 ObjGroup #同一個material的面 ObjFace #一面可能有3或4個頂點 ObjVertex Material #mtl檔的資料 #--以下是ObjFile裡的資料 #坐標 ObjFile.vertexList[] #list of float3 tuple ObjFile.texCoordList[] #list of float2 tuple ObjFile.normalList[] #list of float3 tuple #polygon資料,以階層式儲存 ObjFile.groupDict{} #material name -> ObjGroup ObjGroup.faceList[] #list of ObjFace ObjFace.vertices[] #list of ObjVertex #多個面共點的話,每個面有各自的ObjVertex ObjVertex.vid #在坐標list裡面的index ObjVertex.tid ObjVertex.nid ObjVertex.vCoord #=vertexList[vid],事先把陣列裡的坐標取出來 ObjVertex.tCoord ObjVertex.nCoord #material資料 ObjFile.materialDict{} #material name -> Material Material.name Material.diffuse Material.dissove #alpha Material.ambiane Material.specular Material.specularExp #specular強度 Material.map_Kd #貼圖檔名 |
| 材質1 | 156 |
| 材質2 | 156 |
| 材質3 | 144 |
| #這些要輸出到檔案,設成instance variable保存資料 self.usedMaterialList=[] self.usedVertexList=[] self.groupListByMaterial=[] self.textureNameDict=OrderedDict() #texture file name -> index self.totalIndexCount=0 #這些在函式結束後就不需要,設成區域變數 flatVertexDict={} usedVertexDict={} |
| def getVidTidNid(self): return (self.nid<<64)|(self.tid<<32)|self.vid |
| #用os.path模組分離路徑 #主檔名與obj相同,附檔名改成pmd outFileName=os.path.splitext(sys.argv[1])[0]+".pmd" outFile=open(outFileName,"wb") |
| class ObjFile: def writePmd(self, outFile, globalScale, globalOffset): PMD_HEADER=struct.pack("<3sf276s",b"Pmd",1.0,b"\0") outFile.write(PMD_HEADER) |
| #class ObjFile外面 def writeInt(file,value): file.write(struct.pack("<I",value)) |
| print("output vertices", len(self.usedVertexList)) writeInt(outFile, len(self.usedVertexList)) for vertex in self.usedVertexList: outFile.write(vertex.packPmdData(globalScale, globalOffset)) |
| def clamp(value): return max(min(value, 1.0), 0) class ObjVertex: def packPmdData(self, globalScale, globalOffset): #位置,用map()把tuple的所有元素套用相同函式 tempList=list(map(lambda x,offset:(x+offset)*globalScale, self.vCoord, globalOffset)) tempList[2]*=-1 #.obj用右手坐標系,把Z反向轉換成左手坐標系 tempArray=array.array("f",tempList) #法線 tempList=list(self.nCoord) tempList[2]*=-1 tempArray.fromlist(tempList) #貼圖坐標 tempList=list(self.tCoord[0:2]) tempList[0]=clamp(tempList[0]) #.obj的貼圖坐標是左下為(0,0),PMD是左上為(0,0),要修改Y坐標 tempList[1]=clamp(1.0-tempList[1]) tempArray.fromlist(tempList) boneData=struct.pack('<HHbb',0,0,0,0) #目前沒用到bone和edge return tempArray.tobytes()+boneData |
| #class ObjFace新增這些函式 class ObjFace: def packIndex(self): v0Index=self[0].newVertexIndex #頂點可能有3或4個,此迴圈可以把4個頂點的面拆成兩個三角形 for i in range(1,len(self)-1): data+=struct.pack('<HHH',v0Index, self[i+1].newVertexIndex, self[i].newVertexIndex) return data def __getitem__(self, key): #可以使用self[index]取得頂點 return self.vertices[key] def __len__(self): #可以使用len(self)取得頂點數量 return len(self.vertices) #class ObjFile內 print("output triangles", self.totalIndexCount//3) writeInt(outFile, self.totalIndexCount) for group in self.groupListByMaterial: for face in group.faceList: data=face.packIndex() outFile.write(data) |
| writeInt(outFile, len(self.usedMaterialList)) materialNameList=[] for material in self.usedMaterialList: outFile.write(material.packPmdData()) materialNameList.append(material.map_Kd) #列出用到的貼圖,按檔名排序 materialNameList=sorted(materialNameList) print("\nused textures") print(materialNameList) |
| outFile.write(struct.pack("<HHHBBI",0,0,0,0,0,0)) |
| outFile.close() |
| objtopmd.py stage01.obj 0.03453 -2.5 0 0 |
 活動與參展 (0)
活動與參展 (0)
└活動與參展資訊 (1)
└活動與製作後記 (11)
└販售會遊戲團調查 (14)
遊戲團隊「電子妖精實驗室」 (0)
└重要消息 (4)
└Cyber Sprite遊戲秘密 (2)
└製作進度 (26)
創作 (0)
└繪圖 (24)
└程式 (48)
└故事、劇本 (3)
未分類 (0)

pjfl20180818 給 自己:
怎覺得被騷擾了看更多我要大聲說昨天15:46