在看文之前,由於步驟流程多
想學的再繼續看下去吧
從第二篇開始我會放一些中文化的工具上來
最好先下載天使組教程--入門篇來看看
熟悉下漢化的概念原理等,本文只從實際出發,帶大家一起來實踐一下。
本教程所用的ROM是0462 - 降魔靈符傳,沒有的自己找地方下載吧。
本人不提供遊戲軟體
好了,準備工作完成,下面正式開始教程。
拿到一個新ROM,個人習慣看看此ROM的文本是不是用標準的Shift-JIS編碼
如果是的話那就可以省去做碼表的功夫了。那如何判斷一個ROM是否用Shift-JIS編碼的呢?
首先,用模擬器或者NDS運行遊戲,記錄下遊戲開頭的第一句話
如降魔靈符傳的第一句話是“今は昔”
然後在Shift-JIS-A.tbl裡面查找此三個字的編碼,結果為:8DA1 82CD 90CC。
然後用CrystalTile(以後簡稱為CT)打開降魔靈符傳
按CTRL+H切換到十六進制編輯器視圖,再選擇菜單的碼表/導入碼表
打開Shift-JIS-A.tbl,再次選擇碼表/啟用碼表。
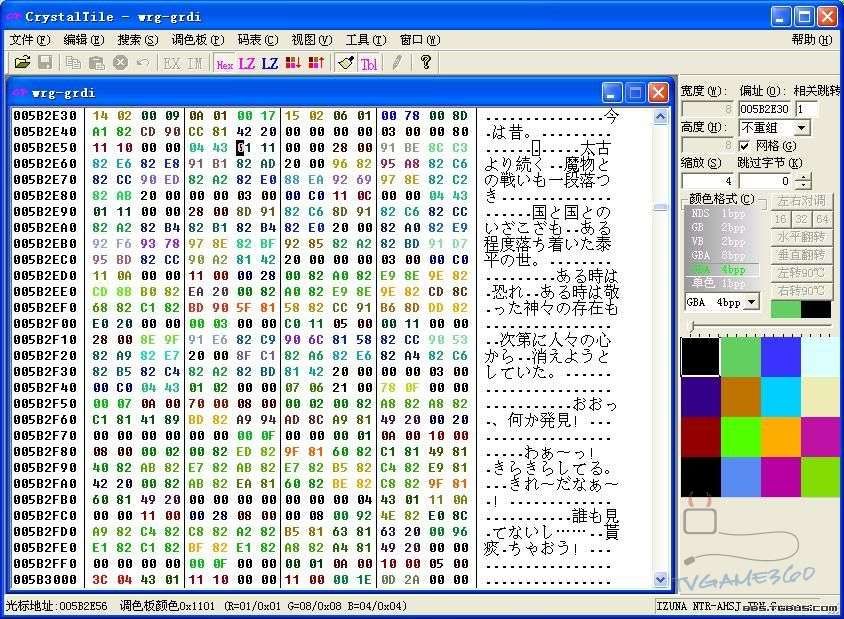
按CTRL+F彈出查找窗口,輸入“今は昔”的SJIS編碼:8DA1 82CD 90CC。按下“查找下一個”
很快就能找到了,如圖一所示,為了驗證一下,我們來修改下測試吧。
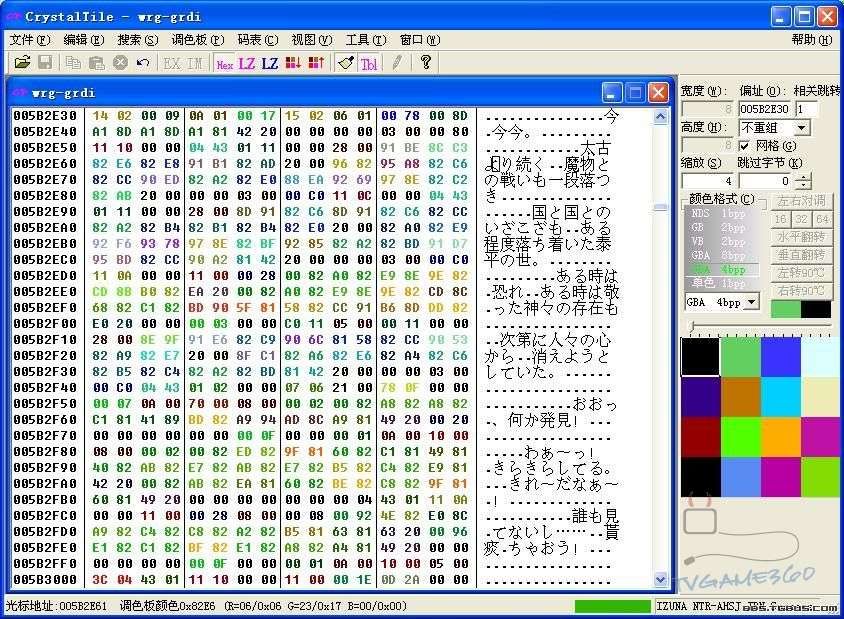
將“は昔”的編碼修改為“今”的編碼,如圖二,保存。
運行遊戲,效果出來了,遊戲的第一句話被我們改為“今今今。”了。
由此說明了此處的文本正是遊戲所用的文本,也說明了此遊戲的文本用的編碼就是SHIFT-JIS編碼。
圖一:搜索到“今は昔”的文本
圖二:修改為“今今今"
圖三:修改測試成功
到這裡先別急著導出文本,遊戲字庫我們還沒找呢!
找遊戲字庫一般的方法就是用CT打開ROM,然後一頁一頁往下翻,仔細查找。
不過這方法傚率低,而且很廢眼睛,不到萬不得已一般不用
個人一般習慣先用NDSTOOL解壓ROM,然後在解壓出來的文件裡面查找。
把降魔靈符傳的ROM放在NDSTOOL目錄下
運行_dump.bat,會彈出一個DOS窗口,稍等片刻等它自動關閉後就解壓完成了。
進入data目錄,下面還有幾個子目錄,根據目錄的名稱可以猜測:
data:遊戲數據目錄
font:字庫目錄
gra:圖形目錄
scenario:遊戲場景
sound:聲音
一般font目錄下的文件就是該遊戲的字庫
如果沒有該目錄的話各位可以搜索文件名中含有font的文件,一般來說這個文件也就是字庫。
進去font目錄,發現有四個文件,文件名為Font**.NFTR,其中的**是代表字體的寬度
單位為像素。本遊戲的字體寬度是12像素的
可在遊戲裡面截圖,然後在畫圖裡面放大數下寬度為幾個像素
所以推測Font12.NFTR文件就是此遊戲的字庫文件。
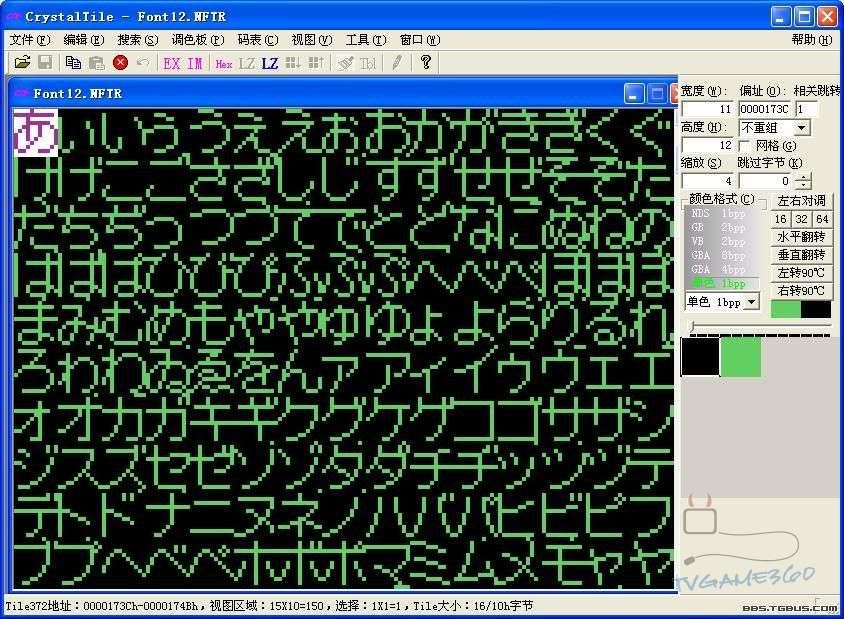
下面再來驗證一下。用CT打開Font12.NFTR,選擇菜單的視圖/Tile視圖
然後在右邊的屬性那裡設置寬度為11,高度為12,顏色格式為單色1BPP
然後再使用CTRL+左右鍵進行微調後就可以看清字庫了。
大家可以把日文假名都抹掉然後在遊戲裡面看看還會不會顯示日文假名。
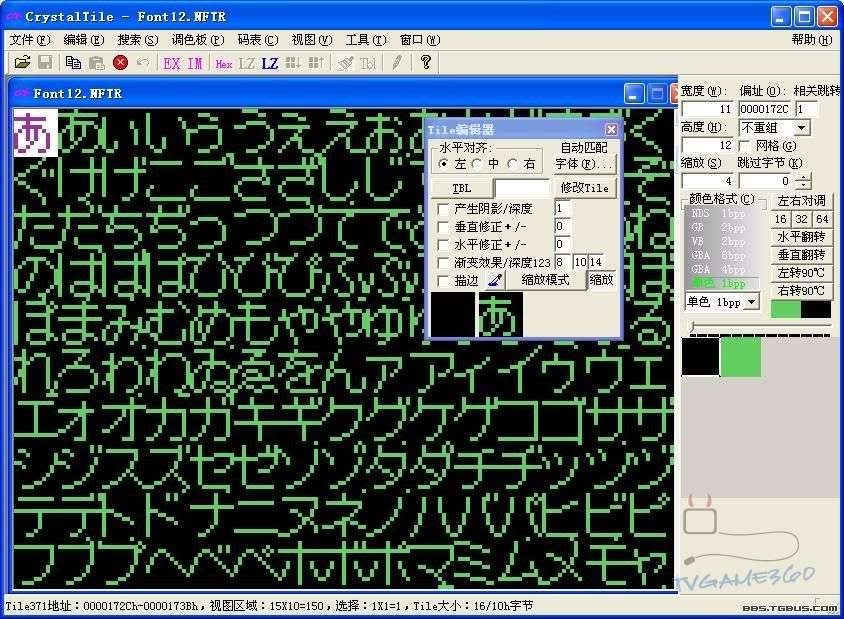
選中日文假名的第一個假名“ぁ”,選擇菜單的視圖/Tile編輯器
按CTRL+D調出Tile編輯器窗口,一直點擊修改Tile抹掉全部假名,最後保存。
圖四:本遊戲的字庫
圖五:利用CT修改字庫
最後運行_pack.bat就可以把之前解壓出來的文件打包成ROM了
生成的文件名為pack.nds,運行測試一下此ROM,如圖六,發現日文假名都不顯示了
從而驗證了Font12.NFTR這個文件就是該遊戲所用的字庫。
圖六:抹掉日文假名後的效果
接下來就是要導出文本了。首先要找到文本在ROM裡面的開始地址和結束地址
可以在之前查找到的文本“今は昔”處向上一直翻頁,來到文本的最開始處
把光標放在文本的開頭,查看左下方顯示的光標地址:0058BA36
這個地址就是開始地址,記錄下來吧!同樣,一直向下翻頁可以找到結束地址:005C883E。
有了這兩個地址我們就可以開始導出文本了。
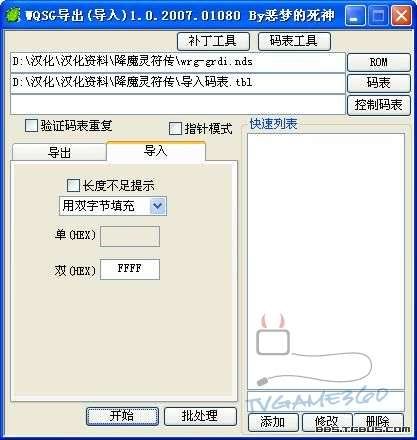
運行WQSG 導出(導入) 工具,如圖
分別點擊ROM和碼表選擇降魔靈符傳的ROM和Shift-JIS-A.tbl碼表
然後在開始地址和結束地址處填上之前我們找到的地址,之後再按開始鍵就可以導出文本了。
導出的文本如下:
0058BA36,12,そんな中……
0058BA43,38,未だ神の存在が色濃く殘る 小さな村に
0058BA74,14,泰平の世ゆえに
0058BA83,10,職を失った
0058BA9B,32,x四人の忍びがたどり著いた……
0058BAC1,1,x
0058BAC3,2,4
0058BACF,66,やけに風が強いなぁ~。 あ、おじじ様。 や~っと村についたよ~!
0058BB2A,1,↙
0058BB38,1,↙
0058BB41,1,↙
0058BB43,2,@
0058BB4A,32,おお! なかなかいい村じゃな。
呵呵,發現好多亂碼吧,大家可以修改下碼表
把前面的半字節部分都刪除,只保留從8140= 開始的部分,然後再導出文本。
導出文本然後就交給翻譯來翻譯吧
翻譯好後做導入碼表來導入,以及做中文字庫,完成這些工作後一個漢化遊戲就誕生了!
下面就用開頭處的文本來教大家怎麼做碼表和字庫吧。
開頭部分的日文文本:
005B2E3F,8,今は昔。
005B2E5C,12,太古より続く
005B2E6A,24,魔物との戦いも一段落つき
005B2E96,20,國と國とのいざこざも
005B2EAC,28,ある程度落ち著いた泰平の世。
005B2ED9,12,ある時は恐れ
005B2EE7,26,ある時は敬った神々の存在も
005B2F12,18,次第に人々の心から
005B2F26,20,消えようとしていた。
005B2F5B,18,おおっ、何か発見!
005B2F85,28,わぁ~っ! きらきらしてる。
005B2FA3,16,きれ~だなぁ~!
005B2FCB,18,誰も見てないし……
005B2FDF,14,貰っちゃおう!
翻譯後:
005B2E3F,8,在過去。
005B2E5C,12,太古時代開始
005B2E6A,24,同魔物的戰爭漸漸平靜
005B2E96,20,國與國之間的糾紛
005B2EAC,28,也漸漸消融,進入太平盛世。
005B2ED9,12,那些恐懼
005B2EE7,26,被人膜拜的神靈
005B2F12,18,從人們心中
005B2F26,20,逐漸消失了
005B2F5B,18,啊!發現什麼了!!
005B2F85,28,哇~~! 閃閃發光
005B2FA3,16,好漂亮!!
005B2FCB,18,沒人看見……
005B2FDF,14,歸我了!
注意此文本不是用指針表導出的文本,對翻譯後的文本長度有限制
即翻譯後的長度不能超出原日文的長度,否則導入會出現問題。
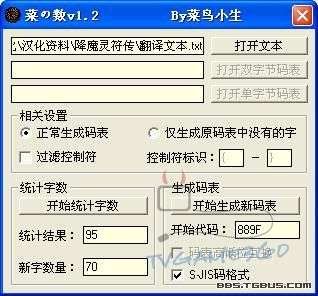
翻譯好之後接下來就用菜の數來統計字數和生成碼表吧。
運行菜の數,打開翻譯好的文本,點擊開始統計字數,之後就會顯示統計結果。
由於此遊戲用的編碼是標準的SHIFT-JIS編碼,所以選擇S-JIS碼格式
另外做中文字庫的時候一般是修改原日文字庫中的日文漢字部分
而在SHIFT-JIS編碼中第一個漢字“亜”的編碼是889F
所以在開始代碼那裡填889F,然後按下開始生成新碼表就會生成我們所需要的導入碼表了
接著就來導入文本吧,運行WQSG 導出(導入) 工具
點擊導入,選擇ROM以及之前用菜の數生成的導入碼表
選擇用雙字節FFFF填充(不填充的話就會顯示多餘的亂碼文本)。
然後點擊開始導入翻譯好的文本。
導入完成,接著就是做字庫了。
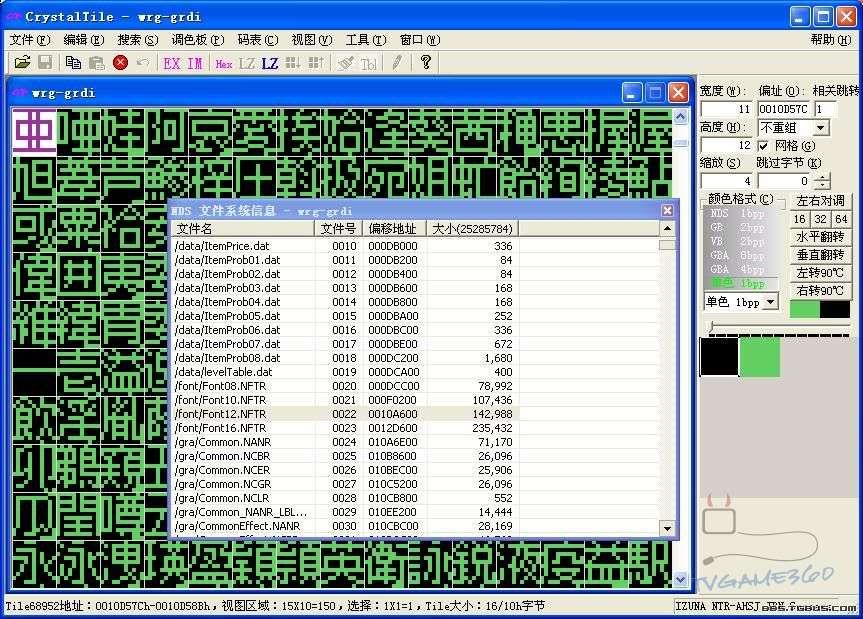
用CT打開ROM,選擇菜單的工具/NDS文件信息系統
找到之前的字庫文件Font12.NFTR,雙擊就會自動跳到此文件的地址
然後按之前的設置,正常顯示該字庫。
之後找到光標選中第一個漢字“亜”
按CTRL+D調出TILE編輯器窗口,點擊字體選擇新宋體,大小為小四
當然其他字體也行,主要是美觀問題,確定
然後按TBL打開導入碼表
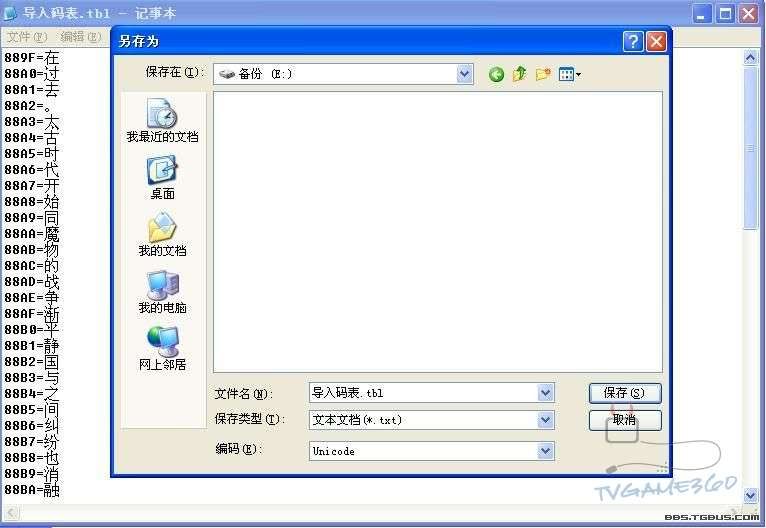
注意此版本的CT只支持UNICODE編碼的文本
所以之前要把導入碼表另存為UNICODE編碼的文本
這樣就可以生成字庫了。保存,然後運行遊戲看看你所做的成果吧。
圖十:把導入碼表另存為UNICODE編碼
漢化成功!
接下來會有更完整的教學喔
 創作內容
創作內容
















 電影心得與推薦 (1)
電影心得與推薦 (1)